SDモデルはドレスアップ:何でもインペイント

類似のケース:https://cloud.tencent.com/developer/article/2365063
実例
レースで飾られた白いウエディングドレスを着て、夕暮れの浜辺を歩く美しい女性。 彼女の髪はそよ風にそっと持ち上げられ、白いバラのブーケを持っている。彼女の髪はそよ風にそっと持ち上げられ、白いバラのブーケを持っている。ダイナミックポーズ、写真、傑作、最高品質、8K、HDR、ハイレゾ、不合理な解像度:1.2、Kodak portra portra 400、フィルムグレイン、背景ぼけ、ボケ:1.2、フィルムグレイン。背景ぼけ, ボケ: 1.2, レンズフレア
リバース: NSFW, ブス, 絵, スケッチ, (最低画質:2), (低画質:2), (普通画質:2), lowres
例えば、このようなマネキンに服を着せている写真がありますが、これは私たちのショールームで撮影したものです。

屋上プラン
Stable Diffusionが使えれば、最初の画像を出すのに10分もかからないだろう。

調整が必要だとしても、1時間もあれば十分だ。例えば

マネキン・ジェネレーション・ライブ・モデル1

マネキン・ジェネレーション・ライブ・モデル2

マネキン・ジェネレーション・ライブ・モデル2
I. 現実の人間プラットフォーム図生成のためのアイデア
ダミーテーブルを本物の人間に変え、なおかつ洋服を維持するためには何が必要なのか?
この時点で、安定した拡散に精通している友人は言うでしょう:私は知っている、それはTuchengtuでInpaint関数を使用することであり、その後、安定した拡散が再塗装するように、服の外にマスクを作成します。
あのマスクはどうやって作るんですか?手で一筆書きでマスキングをしなければならないなら、それは遅すぎる。それなら、特にこれで出てくる必要はない。
フォトショップでマスクを作ってから、マスクの再ペイント機能を使えばいい。
それも一つの方法だが、今の方がスマートかもしれない。
今日は、Inpainting anythingというプラグインを使って、写真を様々な色に塗り分けよう。最後に、どのカラーブロックをマスクにするかを選ぶだけで、マスクができあがる。
その後、リペイント機能を使って、服を着たままダミーを等身大にする。

基本的な考え方はこうだが、自分でやったことのある人なら、道中にはまだたくさんの穴があることをご存じだろう。
そこでこの記事では、ダミーを本物の人間に変える方法をハンズオンで紹介するだけでなく、重要なのは、私がその穴をどのように埋めているかも紹介することだ。
そのすべてを今から説明しよう。
II.ダミーテーブルモデル実現準備ツール
このデモでは、SD 1.5モデルでAutomatic 1111のWebUIを使用します!
準備1:何でも塗る
まず、Inpaint Anythingプラグインが必要です。Automatic 1111のWebUIでInpaint Anythingプラグインがあるかどうかを確認してください。

何でもインペイントをインストールする
URLからインストール」に進み、次のように入力する。
https://github.com/Uminosachi/sd-webui-inpaint-anything.git
取り付け準備完了

インストールが完了したら、インストールタブに戻り、適用を押して終了する。

準備2:痛み特異的モデル
今回は、epiCPhotoGasmを使って、まるで巨匠のカメラマンが撮影したかのようなクオリティのモデルが出来上がることを実証してみよう。
今日は彼のメインモデルの代わりに、インペイントモデルを使おう。

以下のリンクからInpaintモデルをダウンロードし、後で使用するためにインストールしてください。
https://civitai.com/models/132632?modelVersionId=201346
準備3:ダミー写真
今回の例を使おう。
これは彼自身のショールームで撮影されたもので、彼は黒人のマネキンなので、後で面倒なことになるのでご注意を。まずはこちらから。
この3つの準備ができたら、始めよう。
III.オペレーション・デモンストレーション
この指導では、SD1.5モデルを使用して、プロセス全体を示す。
ステップ1:SAMモデルの選択とモデルのダウンロード
Inpaint Anything』タブを押すと、次のような画面が表示されます。

使用するセマンティック・セグメンテーション・モデルのセグメント・モデル ID を選択します。ここでは sam_vit_l_0b3195.pth を選択します。インストールしたばかりの場合、これらのモデルはまだダウンロードされていないので、ダウンロードする前にモデルのダウンロードボタンをクリックする必要があります。
負荷をかける。

ステップ2:セグメンテーション図の例を入手する
インペイント・エニシングする画像をアップロードし、Run Segment Anythingを押す。

右側に分割図の例がある。

ステップ3:予備マスクを作る。
後で再描画機能を使うには、再描画したい部分のマスクを作る必要がある。意味的に分離されたカラー・ブロックができた今、マスクを素早く作るにはどうすればいいのだろうか。
ブロック全体を塗る必要はなく、そのブロックをタップして少し待つだけでマスクになります。
背景やダミーなどをリペイントしてほしいので、そういった場所はピックアップしなければならないが、背景はアップするのが少し複雑だ
面倒なので、代わりにドレスのカラーブロックをクリックし、「マスクを反転」にチェックを入れる。
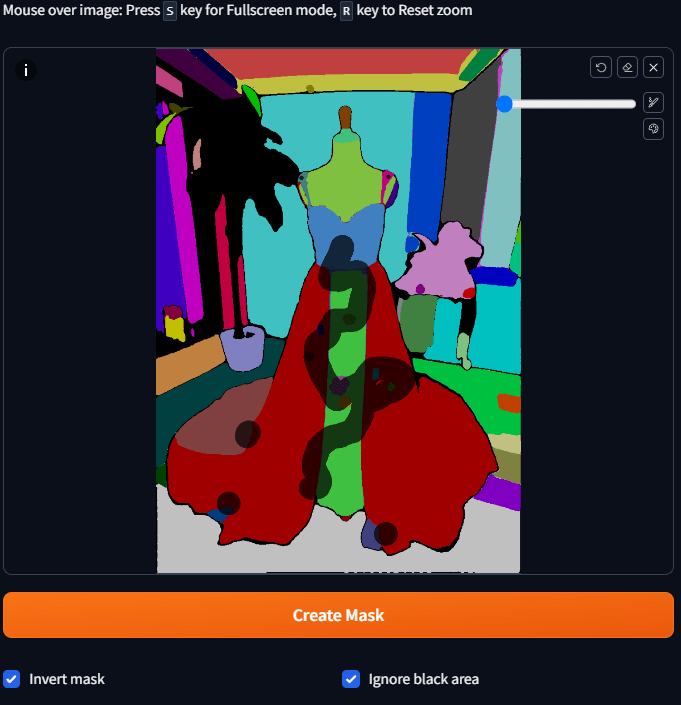
すべて選択したら、「マスクを作成」を押すと、マスクの結果が表示される。

ステップ4:マスクの結果を見る
マスクの結果を確認して、見逃しがないかどうかを確認するために、実際には、画面がより複雑な場合は、明確に表示することは困難であるため、ここではトリックである、タブの横にあるマスクのみのページが開きます。

そこには2つのボタンがある:
画像のアルファ値としてマスクを取得する
マスク
この2つのボタンを押すと、マスクが完成したかどうかがわかる。

ちなみに、こっちの白はマスクで、今後AIで塗りつぶす部分、黒は残す部分なので、間違えないように。
ステップ5:マスクの微調整
このマスク画像を見てわかるように、服以外にもまだマスクされていない場所がある(つまり、そこにあってはならないものがある)。
(黒線)。

その時に手作業で微調整するんだ。
マスクを生成したダイアグラムに戻り、その上にマスクする領域をペイントする。黒を追加する部分があれば、手動で移動させてTrim mask by skatchボタンを押し、逆に白を追加する場合は、手動で移動させてAdd mask by skatchボタンを押す。
絵が小さすぎて描きにくいと思ったら、Sを押して拡大し、もう一度Sを押すと元に戻ります。

プラス・ブラック:スカッチボタンによるトリムマスク
白を追加:スカッチボタンでマスクを追加

を押してください。 Add mask by sketch.
次にマスクのみタブで Get mask まで Get mask as alpha of image それが我々の望むことなのか?
マスク

もし、他にはみ出した部分があれば、同じように切り落とす。問題がなければ、次のステップに進む。
ステップ6:何でもインペイントで再塗装を開始する
マスクがすべて完成したら、背景を埋めるために安定した拡散を求めることができる。
インペイントタブに移動し、言及と逆の言及を記入する。生成したいイメージは、ウェディングドレスを着て白いバラを持った美しい女性です。そこで次のように入力します:
A beautiful woman wearing a white wedding dress while holding a bouquet of white roses.
Dynamic pose, photography, masterpiece, best quality, 8K, HDR, highres, absurdres: 1.2,
Kodak portra 400, film grain, blurry background, bokeh: 1.2, lens flare
逆テレは以下の通り:
Nsfw, ugly, paintings, sketches, (worst quality:2), (low quality:2), (normal quality:2), lowres

インペイントモデルのいずれかを選択する。

私たちは本物の写真を撮りたいので、次のようなものを使っている。 海の幸/realisticVisionV51_v51VAE-inpainting この
モデル
Run Inpaintingを押すと、ライブモデルの画像が表示されます。

良さそうだ。

カルテを手に入れた後、この指導は終わったと思いますか?
まだだ!というのも、本当に使いたいのかどうか、まだ疑問があるからだ。
- 一度にたくさんの写真を選ぶことはできない。
- 欲しいモデルを使う方法がない
では、どうすればいいのか?次のステップが必要だ。
ステップ7:テューペロの再描画機能を使う
Mask Onlyタブに戻り、「Send to img 2 img inpaint」を押す。

マスクを送信すると、TupeloのInpaint Uploadタブにジャンプします。画像とマスクが送信されたことがわかります!

SDに慣れ親しんだ人々は、慣れ親しんだ場所に戻り、ようやくお気に入りのモデルを選べることを喜ぶだろう。
では、モデルを選んでみよう!ここではchilloutmixを選ぶ。
そして、写真のサイズを調整する。三角形のボードを押した後、システムは自動的に幅と高さを写真と同じに調整する。

さて、テレプロンプターを埋めるために、今度は美しい女性がウェディングドレスを着て浜辺におり、髪がそよ風にそよぎ、白いバラのブーケを持っているように変更したい。そこで、テレプロンプターを次のように変えてみよう:
A beautiful woman wearing a white wedding dress adorned with lace, walking along the
beach at sunset. Her hair is gently lifted by the breeze, and she is holding a bouquet of white roses. Dynamic pose, photography, masterpiece, best quality, 8K, HDR, highres, absurdres: 1.2,
Kodak portra 400, film grain, blurry background, bokeh: 1.2, lens flare
逆テレは変わらず:
Nsfw, ugly, paintings, sketches, (worst quality:2), (low quality:2), (normal quality:2), lowres
サンプラーはDPM++ 2 M Karrasで、サンプリングステップは40に設定されている。
それ以外のパラメーターは、以下のようにプリセットとして使用される:

これですべての準備が整ったはずだ!
奇妙なものが現れた!

なぜAIモデルは服を着替えないのか?服が宙に浮いているように見える。
調整が必要なのはマスクされたコンテンツですか?現在のプリセットはオリジナルです。

まずはフィルから始めよう。

まだうまく装着できていない。じゃあ、潜伏ノイズにして見てください。

写真はさらに奇妙だ。ということは、潜伏無になるのだろうか?

服を着ていないという意味で!どうしたんだ?なぜ服はいつも着たままなんだ?
だから、こっちの結論は......壊れている......。
まだ結論を急いではいけない。これは本当に間違ったモデルを選んでしまったということなんだ。
ステップ8:epiCPhotoGasmインペイントモデル再塗装を選択する
私たちがやっているのは再塗装であって、純粋に生成しているわけではない。
ChilloutMixはリペイントに使うモデルではないので、代わりに以前ダウンロードしたepiCPhotoGasm_zinpaintingを使うことにする。
モデル

モデルが変更されたので、生成を開始しよう。 これで問題ないはずだ!
結果を見てみよう:

着飾った...美しいマネキンを手に入れた。
どうなっているんだ?さっきまで服が着られなかったのに、今はその人がいない。約束された美しさはどこに?運が悪かったのかもしれない。

その結果、美しさはそこにあるが、胸の黒い布は何なのか?この布は頼んでいない!
その理由は、現在のマスク・コンテンツ・パラメータがオリジナルであるため、再描画時にオリジナル画像の構造と色を参照することになり、その結果、プラットフォームと黒い布がオリジナル画像に存在するように見えるからである。では、どうすればこの問題を解決できるのでしょうか?
簡単なのは、パラメータを別のものに変えるだけだ。 フィル 下のような図が表示されます。




潜在ノイズを使用した場合、結果は以下のようになる。



潜伏無しを使用する場合



これは素晴らしい写真ではないか。まだ微調整もしてないのにこの画質なんだから、また最適化すればもっと良くなるだろうし、次はどうするんだ?
IV.よくある質問
こうして活動すれば、ひとつひとつ説明するための質問がいくつか出てくるかもしれない。
質問1:インスタンス・パーティショニングとは何ですか?
インスタンス・セグメンテーションとは、異なるものを異なる色でラベリングし、それぞれの色が1つのものを表すことで、画像内のものを区別するプロセスを指す。
今回は、マスクを作るのにかかる時間を短縮するための、例による分割についてだ。
質問2:Inpaint Anythingには異なるSegment Anything Modelsがあります。
SAM とも呼ばれる Segment Anything Model は、Inpaint Anything に 9 種類の Segment Anything モデルを提供します。

それは4つのカテゴリーに分けられる。
クラス1:sam_vitで始まる - Metaが提供するSAMモデル
sam_vitの始まりは、metaが提供したモデルである。Metaは彼らのセマンティックセグメンテーションモデルをSegment Anything Modelと名付けたので、現在私たちが話しているSAMはここから始まっており、このSAMモデルの波の元祖と考えるべきである。
これはメタが2023年4月に発表したシリーズで、他のSAMモデルもこのシリーズと比較される。サイズ的にはh(巨大)、l(大)、b(ベース)の3モデルで、巨大>大>ベースとなっており、精度は理論上サイズに比例し、計算速度もサイズに比例する。
効果という点では、巨大と巨大の差はほとんどないが、ベースと巨大の差は大きい。

メタSAMリファレンス:
https://segment-anything.com/
https://github.com/facebookresearch/segment-anything
https://huggingface.co/facebook/sam-vit-base/tree/main
https://huggingface.co/facebook/sam-vit-large
https://huggingface.co/facebook/sam-vit-huge
クラス2:sam_hq_vitの始まり - セグメント何でも高画質シリーズ
sam_hq_vit で始まるモデルは、チューリッヒ工科大学の Visual Intelligence and Systems Group が提供する高品質なセマンティック・セグメンテーション・モデルであり、彼らの論文で提供されているデータによれば、彼らのセグメンテーションの精度は Meta よりも良いので、高品質と呼ばれている。彼らの論文で提供されているデータによると、彼らのセグメンテーションの精度はMetaよりも良いので、高品質と呼ばれる。ただし、セグメンテーションされた領域はMetaよりも薄いが、我々のケースではその差は大きくない。

SAM本部参照:
https://github.com/SysCV/sam-hq
https://huggingface.co/lkeab/hq-sam/tree/main
クラス3:FastSAMの始まり - FastSAMシリーズ
良い結果を得るために、そしてメモリを節約するために、CASIA-IVA-Lab(カシア・イバ・ラボ)が提供しているFastSAMシリーズを使うことができます。私自身、小さなVRAMマシンでこのモデルを使っています。
XとSの2つのモデルがある。
モデルXはこのウェディングドレスの例では問題なく使用できたが、Sは私たちの例には適さなかっただろう。

FastSAM の情報は以下の通りです:
https://github.com/CASIA-IVA-Lab/FastSAM
https://huggingface.co/An-619/FastSAM
カテゴリー4:モバイルSAM
小型で高速なSAM、CPUでも高速に動作するSAM。しかし、その効果は最悪で、大きなブロックを見分けるのにしか適していない。

モバイルSAMリファレンス
https://github.com/ChaoningZhang/MobileSAM
https://huggingface.co/dhkim2810/MobileSAM/tree/main
質問3:InpaintのMasked contentパラメータは何を制御するのですか?

マスクされたコンテンツには、以下の4つのオプションがある:
オプション1:充填
塗りつぶしオプションは、再描画領域の画像を可能な限りぼかし、大まかな構造と色のみを保持します。したがって、大規模な再塗装が必要な場合に使用します。
私たちのパラダイムでは、海面の位置も砂の難易度のコースもすべて同じで、夕日の色さえも似ている。

オプション2:オリジナル
オリジナルとは元画像のことで、生成される画像は、ブロックや色などの点で元画像に非常に似ている。
この例では、このオプションはマネキンの黒い部分を残し、ビーチの方向を残す。

オプション3:潜在ノイズ
潜在ノイズは再描画する部分にノイズを与え、無関係な内容を生成する傾向があり、創造性が要求される場合に使用される。
このデモでおわかりのように、潜在ノイズを使って生成された画像は、プロンプトで言及された小さなこと(例えば、この場合は白いバラ)を繰り返す。

オプション4:何もしない
Latent nothingは、再描画する領域の近くの色を参照し、近くの色の平均を求め、再描画領域を塗りつぶします。これは、不要なオブジェクトを取り除くのに最適です。
しかし今回の例では、大きなスケールで描き直しているため、物が取り除かれているようには感じない。しかし、潜在的な何もない状態で生成された図を観察すると、配色や構図が非常に似ていることがわかるでしょう。例えば、砂の色もすべて非常に似ています。

V. 延長問題の見直し
今やったことを復習しよう。
簡単に言えば、大きく分けて2つのステップがある:
- Inpaint Anythingのセマンティックセグメンテーション機能を使ったマスキング。
- これは、グラフィックアップロード用のインペイントアップロードと、モデルの再塗装専用のインペイントに転送される。
それだけで今日のような生産性が得られたはずだ。


すべてがもっと良くなる可能性があるし、現在のアプローチにはまだいくつかの問題がある:
- 欲しいモデルにインペイントモデルがない場合は?汎用モデルを使うことはできますか?
- 服の光と影を変えるにはどうすればいい?
- 時々、フォトショップで加工した写真のように感じることがありますが、より自然にするためにはどうしたらいいですか?
- 今あるような画像ではなく、より豊かな画像を生成する方法。
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事


コメントはありません