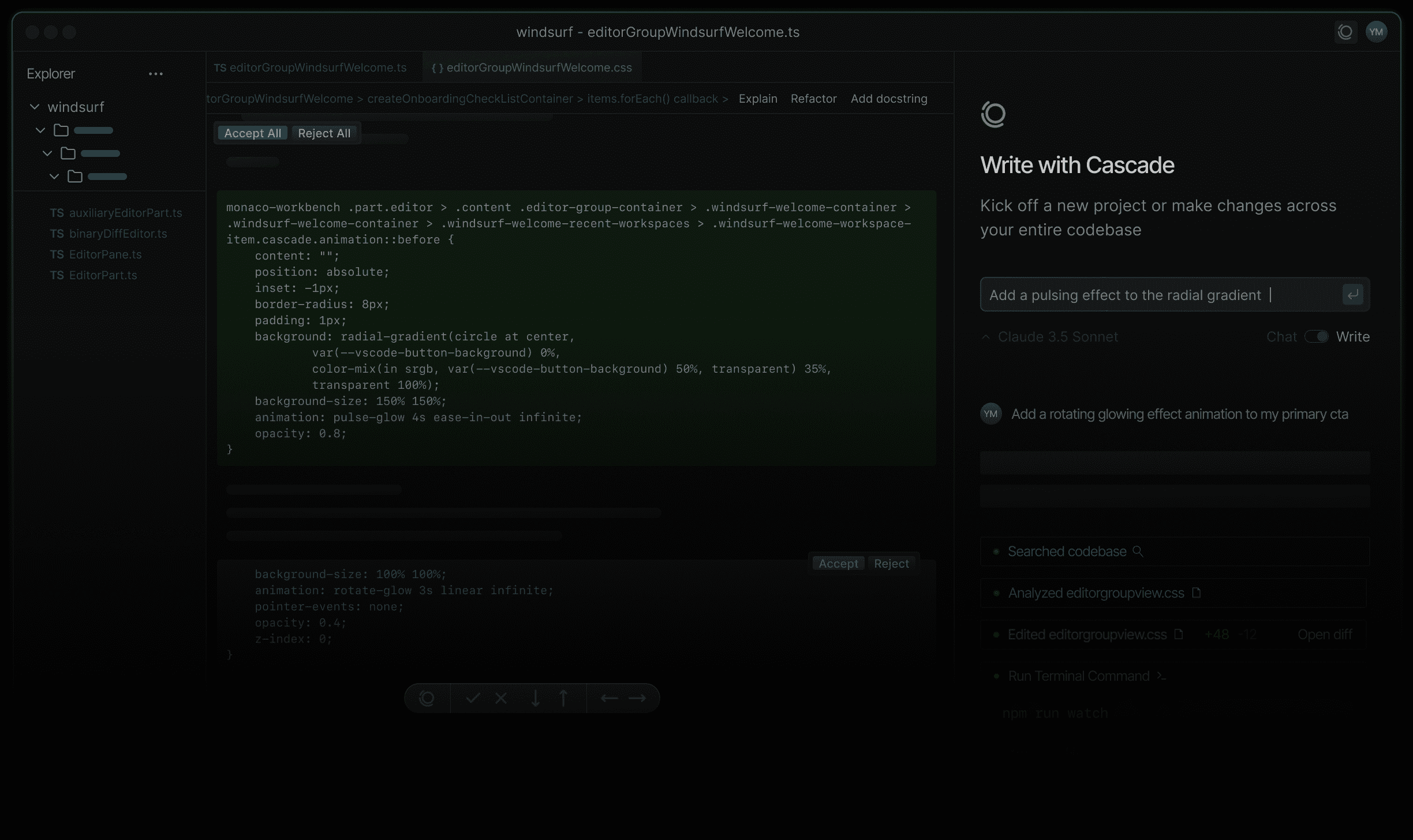
Scraperr: セルフホスティングのウェブデータスクレイピングツール

はじめに
Scraperrは、XPath要素を指定してウェブデータをスクレイピングできる、セルフホスティングのウェブデータスクレイピングツールです。Scraperrは、クロールタスクを管理するためのユーザーログインをサポートし、ログ表示と統計情報を提供します。

機能一覧
- ウェブクローリングのためにURLを送信し、キューに入れる。
- XPathによるクロール要素の追加と管理
- 同じドメイン名のすべてのページをクロールする
- カスタムJSONヘッダーを追加してリクエストを送信する
- 取り込んだデータの結果を表示する
- 結果を含むCSVファイルをダウンロードする
- キャプチャタスクを再実行する
- キューに入れられたタスクのステータスの表示
- ブックマークとブックマークしたタスクの表示
- タスクを整理するためのユーザーログイン/登録
- アプリケーションログの表示
- タスク統計の表示
- クロール結果を対話の文脈に含めることをサポートするAI統合
ヘルプの使用
設置プロセス
- クローン倉庫
git clone https://github.com/jaypyles/scraperr.git - 環境変数とタグの設定
docker-compose.ymlファイルで環境変数やラベルを設定することができる:scraperr: labels: - "traefik.enable=true" - "traefik.http.routers.scraperr.rule=Host(`localhost`)" - "traefik.http.routers.scraperr.entrypoints=web" scraperr_api: environment: - LOG_LEVEL=INFO - MONGODB_URI=mongodb://root:example@webscrape-mongo:27017 - SECRET_KEY=your_secret_key - ALGORITHM=HS256 - ACCESS_TOKEN_EXPIRE_MINUTES=600 - サービスを開始する:
docker-compose up -d
使用プロセス
- クロール用URLの送信::
- Scraperrにログイン後、スクレイピングタスクページに移動します。
- クロールするURLと対応するXPath要素を入力します。
- タスクを送信すると、システムは自動的にキューに入れ、キャプチャを開始する。
- クロール要素の管理::
- クロールタスクのページでは、XPath要素を追加、編集、削除することができます。
- 同一ドメイン内の全ページのクロールをサポート。
- クロール結果を見る::
- キャプチャが完了すると、結果が表に表示される。
- ユーザーは、結果を含むCSVファイルをダウンロードするか、タスクを再実行することを選択できる。
- タスク管理::
- ユーザーは、キューに入れられたタスクのステータスをチェックしたり、ブックマークしたり、ブックマークされたタスクを表示したりすることができます。
- 実行タスクの統計情報を表示する Task Statistics ビューを提供します。
- ログビュー::
- アプリケーションログ]ページでは、キャプチャタスクに関する詳細情報のシステムログを表示することができます。
- AIインテグレーション::
- クロールの結果を対話の文脈に組み込むためのサポートは、現在以下の通りである。 オーラマ とOpenAI。
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事

コメントはありません