
テスト時間計算のスケーリング:ベクトル・モデルに関する思考の連鎖

OpenAIがo1モデルをリリースして以来。テストタイム・コンピューティングのスケーリング(スケーリング推論)は、AI界で最もホットなトピックの一つとなっている。簡単に言うと、事前学習や事後学習の段階で計算能力を積み上げるのではなく、推論の段階(つまり大規模言語モデルが出力を生成する段階)でより多くの計算資源を使った方が良いということである。 o1 モデルは、大きな問題を一連の小さな問題に分割する(つまりChain-of-Thought)ことで、モデルが人間のように段階的に考えることができるようになり、さまざまな可能性を評価し、より詳細な計画を立て、答えを出す前に自分自身を振り返るなどする。モデルは人間のように考えることができ、さまざまな可能性を評価し、より詳細な計画を立て、答えを出す前に自分自身を振り返るなどする。このように、モデルは再学習する必要がなく、推論中の追加計算によってのみ性能を向上させることができる。モデルに暗記させるのではなく、もっと考えさせる。-- アリババが最近発表したQwQモデルは、推論時の計算を拡張することでモデルの能力を向上させるという、この技術的傾向を裏付けている。
👩🏫 本論文におけるスケーリングとは、推論プロセス中に計算リソース(演算や時間など)を増加させることを指す。水平方向のスケーリング(分散コンピューティング)や加速処理(計算時間の短縮)については言及していない。

o1モデルを使ったことがある人なら、問題を解くために思考の連鎖を構築する必要があるため、多段階推論の方が時間がかかると感じるに違いない。
Jina AIでは、大規模言語モデル(LLM)よりもエンベッディングとリランカーに重点を置いています:思考の連鎖」という概念を、エンベディング・モデルにも適用することは可能だろうか?
一見すると直感的ではないかもしれないが、本稿では新たな視点を模索し、スケーリング・テストタイム・コンピュートがどのように適用できるかを実証する。jina-clipをより深く理解することができる。 トリッキーなアウト・オブ・ドメイン(OOD)イメージ カテゴリー分けは、不可能な課題を解決するために行われる。
CLIPのようなモデルは、画像とテキストのマッチングには強いが、モデルが見たことのない領域外(OOD)データに遭遇するとロールオーバーする傾向がある。
しかし、我々は次のことを発見した。モデルの推論時間を増やし、モデルのチューニングを必要としない連鎖思考のような多目的分類戦略を採用することで、領域外データの分類精度を向上させることができる。
ケーススタディ:ポケモン画像分類
Google Colab: https://colab.research.google.com/drive/1zP6FZRm2mN1pf7PsID-EtGDc5gP_hm4Z#scrollTo=CJt5zwA9E2jB
数千枚のポケモンカード画像を含むTheFusion21/PokemonCardsデータセットを使用した。これは画像分類タスクである。これは、切り取られたポケモンデッキ(説明文は削除されている)を入力し、正しいポケモン名を出力するものです。しかし、CLIP Embeddingモデルでは、いくつかの理由から、これは困難です:
- ポケモンの名前と見た目は比較的新しいモデルであり、直接的な分類で転がるのは簡単だ。
- ポケモンにはそれぞれ視覚的特徴があるCLIPは、形、色、ポーズなど、よりよく理解されている。
- カードのスタイルは統一されているがしかし、背景やポーズ、画風が異なることが、難易度を高めている.
- この作業には複数の視覚的特徴を同時に考慮するLLMの複雑な思考の連鎖のように。

これらのポケモンクラスのラベルは、アブソル、エアロダクティルのような彼らの名前であるため、モデルたちがズルをして直接テキストから答えを見つけることがないように、カードからすべてのテキスト情報(タイトル、フッター、説明)を削除しました。
ベースライン手法:直接類似性比較
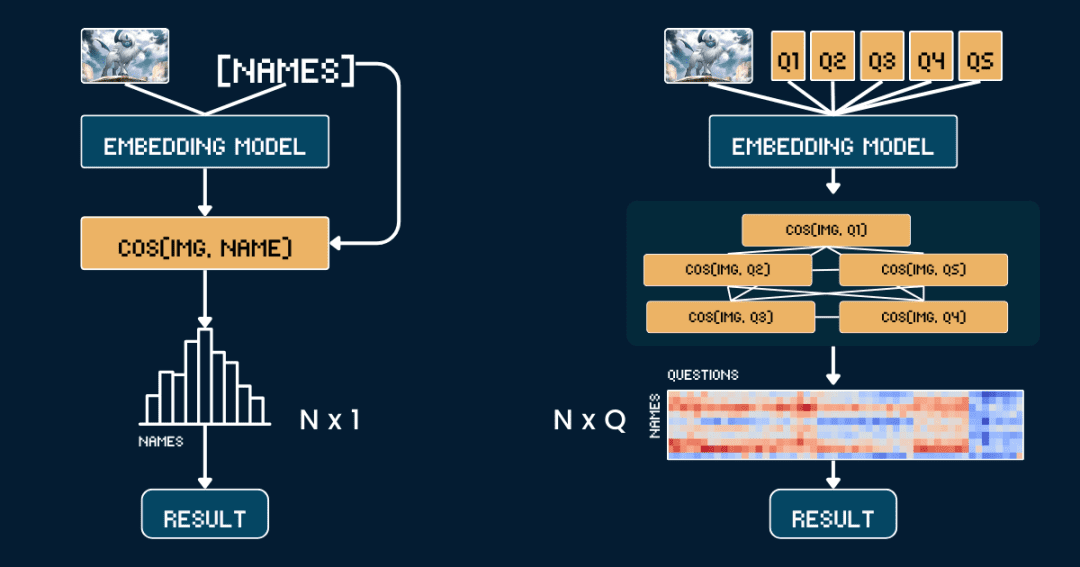
最も単純なベースライン方法論から始めよう。 ポケモンの写真と名前の類似性の直接比較.
まず、CLIPモデルがテキストから直接答えを推測する必要がないように、カードからすべてのテキスト情報を削除する方がよい。次に jina-clip-v1 歌で応える jina-clip-v2 このモデルでは、画像とポケモンの名前を別々に符号化し、それぞれのベクトル表現を得る。最後に、画像ベクトルとテキストベクトル間の余弦類似度が計算され、類似度が最も高い方の名前が、その画像がどのポケモンであるとみなされる。
このアプローチは、他の文脈情報や属性を考慮することなく、画像と名前を一対一で照合することと同じである。以下の擬似コードで、この処理を簡単に説明する。
# 预处理 cropped_images = [crop_artwork(img) for img in pokemon_cards] # 去掉文字,只保留图片 pokemon_names = ["Absol", "Aerodactyl", ...] # 宝可梦名字# 用 jina-clip-v1 获取 embeddings image_embeddings = model.encode_image(cropped_images) text_embeddings = model.encode_text(pokemon_names) # 计算余弦相似度进行分类 similarities = cosine_similarity(image_embeddings, text_embeddings) predicted_names = [pokemon_names[argmax(sim)] for sim in similarities] # 哪个名字相似度最高,就选哪个 # 评估准确率 accuracy = mean(predicted_names == ground_truth_names)
上級:画像分類に思考の連鎖を応用する
今回は、写真と名前を直接一致させるのではなく、「ポケモンコネクト」をプレイするように、ポケモンの識別をいくつかのパートに分けた。
私たちは5つの主要属性を定義した:原色(例:「白」、「青」)、原形(例:「狼」、「翼のある爬虫類翼のある爬虫類")、主要な特徴("白い角"、"大きな翼 "など)、体の大きさ("4本足のオオカミ型"、"翼のある細長い体型"、"翼のあるほっそりとした")、背景の情景("宇宙"、"緑の森 "など)。
各属性のセットに対して、「このポケモンの体は主に{}色をしている」といった特別なキュー・ワードをデザインし、可能な選択肢を埋めていった。次に、このモデルを使って画像と各オプションの類似度スコアを計算し、ソフトマックス関数を使ってスコアを確率に変換します。
完全な思考の連鎖(CoT)は2つの部分からなる:classification_groups 歌で応える pokemon_rules前者は質問の枠組みを定義するもので、各属性(色や形など)は質問テンプレートと可能な回答の選択肢のセットに対応しています。後者は、それぞれのポケモンに対して、どの選択肢を一致させるべきかを記録します。
例えば、アブソルの色は「白」で、姿は「狼」でなければなりません。完全なCoT構造を構築する方法については後述しますが、以下のpokemon_systemはCoTの具体例です:
pokemon_system = {
"classification_cot": {
"dominant_color": {
"prompt": "This Pokémon's body is mainly {} in color.",
"options": [
"white", # Absol, Absol G
"gray", # Aggron
"brown", # Aerodactyl, Weedle, Beedrill δ
"blue", # Azumarill
"green", # Bulbasaur, Venusaur, Celebi&Venu, Caterpie
"yellow", # Alakazam, Ampharos
"red", # Blaine's Moltres
"orange", # Arcanine
"light blue"# Dratini
]
},
"primary_form": {
"prompt": "It looks like {}.",
"options": [
"a wolf", # Absol, Absol G
"an armored dinosaur", # Aggron
"a winged reptile", # Aerodactyl
"a rabbit-like creature", # Azumarill
"a toad-like creature", # Bulbasaur, Venusaur, Celebi&Venu
"a caterpillar larva", # Weedle, Caterpie
"a wasp-like insect", # Beedrill δ
"a fox-like humanoid", # Alakazam
"a sheep-like biped", # Ampharos
"a dog-like beast", # Arcanine
"a flaming bird", # Blaine's Moltres
"a serpentine dragon" # Dratini
]
},
"key_trait": {
"prompt": "Its most notable feature is {}.",
"options": [
"a single white horn", # Absol, Absol G
"metal armor plates", # Aggron
"large wings", # Aerodactyl, Beedrill δ
"rabbit ears", # Azumarill
"a green plant bulb", # Bulbasaur, Venusaur, Celebi&Venu
"a small red spike", # Weedle
"big green eyes", # Caterpie
"a mustache and spoons", # Alakazam
"a glowing tail orb", # Ampharos
"a fiery mane", # Arcanine
"flaming wings", # Blaine's Moltres
"a tiny white horn on head" # Dratini
]
},
"body_shape": {
"prompt": "The body shape can be described as {}.",
"options": [
"wolf-like on four legs", # Absol, Absol G
"bulky and armored", # Aggron
"winged and slender", # Aerodactyl, Beedrill δ
"round and plump", # Azumarill
"sturdy and four-legged", # Bulbasaur, Venusaur, Celebi&Venu
"long and worm-like", # Weedle, Caterpie
"upright and humanoid", # Alakazam, Ampharos
"furry and canine", # Arcanine
"bird-like with flames", # Blaine's Moltres
"serpentine" # Dratini
]
},
"background_scene": {
"prompt": "The background looks like {}.",
"options": [
"outer space", # Absol G, Beedrill δ
"green forest", # Azumarill, Bulbasaur, Venusaur, Weedle, Caterpie, Celebi&Venu
"a rocky battlefield", # Absol, Aggron, Aerodactyl
"a purple psychic room", # Alakazam
"a sunny field", # Ampharos
"volcanic ground", # Arcanine
"a red sky with embers", # Blaine's Moltres
"a calm blue lake" # Dratini
]
}
},
"pokemon_rules": {
"Absol": {
"dominant_color": 0,
"primary_form": 0,
"key_trait": 0,
"body_shape": 0,
"background_scene": 2
},
"Absol G": {
"dominant_color": 0,
"primary_form": 0,
"key_trait": 0,
"body_shape": 0,
"background_scene": 0
},
// ...
}
}
つまり、単純に類似性を一度だけ比較するのではなく、複数の比較を行い、各属性の確率を組み合わせることで、より合理的な判断ができるようになるのだ。
# 分类流程
def classify_pokemon(image):
# 生成所有提示
all_prompts = []
for group in classification_cot:
for option in group["options"]:
prompt = group["prompt"].format(option)
all_prompts.append(prompt)
# 获取向量及其相似度
image_embedding = model.encode_image(image)
text_embeddings = model.encode_text(all_prompts)
similarities = cosine_similarity(image_embedding, text_embeddings)
# 将相似度转换为每个属性组的概率
probabilities = {}
for group_name, group_sims in group_similarities:
probabilities[group_name] = softmax(group_sims)
# 根据匹配的属性计算每个宝可梦的得分
scores = {}
for pokemon, rules in pokemon_rules.items():
score = 0
for group, target_idx in rules.items():
score += probabilities[group][target_idx]
scores[pokemon] = score
return max(scores, key=scores.get) # 返回得分最高的宝可梦
2つの方法の複雑さ分析
N個のポケモンの名前の中から、与えられた画像に最も一致する名前を見つけたいとします:
ベースライン法では、N個のテキスト・ベクトル(各名前に1個ずつ)と1個の画像ベクトルを計算し、N個の類似度計算(画像ベクトルと各テキスト・ベクトルを比較する)を行う必要がある。したがって、ベンチマーク手法の複雑さは、主にテキストベクトルの計算回数Nに依存する。
そして、私たちのCoTメソッドはQ個のテキストベクトル(Qはすべての質問と選択肢の組み合わせの総数)と1個の画像ベクトルを計算する必要があります。その後、Q個の類似度計算(各質問と選択肢の組み合わせに対する画像ベクトルとテキストベクトルの比較)を行う必要があります。したがって、手法の複雑さは主にQに依存する。
この例では、N = 13、Q = 52(1グループあたり平均約10のオプションを持つ属性の5つのグループ)。どちらの手法も画像ベクトルを計算し、分類ステップを実行する必要があり、比較ではこれらの共通操作を四捨五入しています。
極端な例では、Q = Nの場合、我々の方法は事実上ベンチマーク手法に退化する。つまり、推論時間の計算を効果的に拡張する鍵は
Qの値が大きくなるように問題を設計する。 それぞれの質問に、絞り込むための有用な手がかりがあることを確認する。 情報を最大限に得るためには、質問間で情報が重複しないようにするのがベストです。
結果
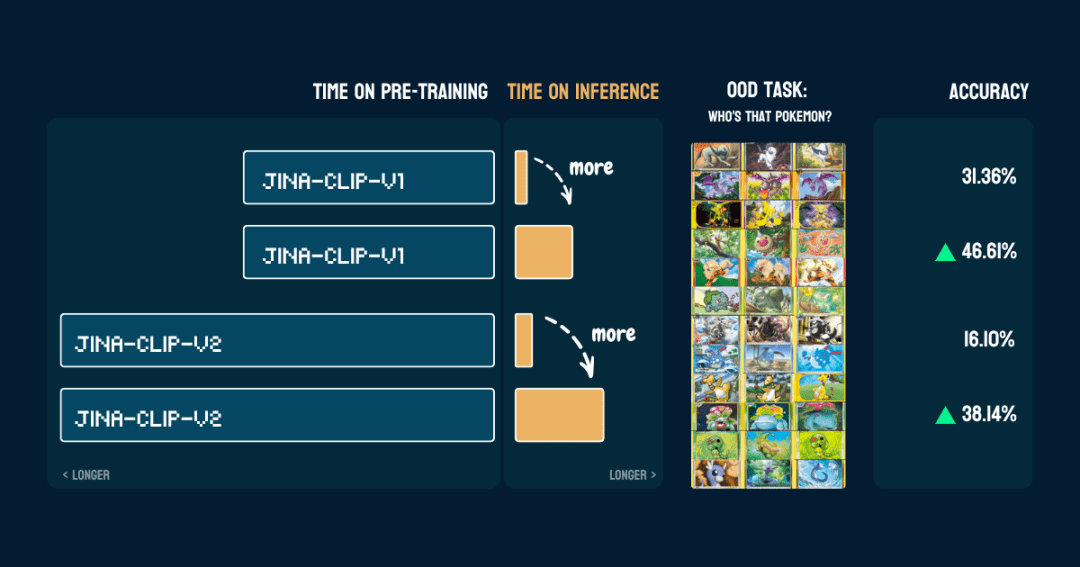
13種類のポケモンを含む117枚のテスト画像で評価した。精度の結果は以下の通りである:

また、一度pokemon_system正しく作られている。同じCoTを、コードを変更することなく、微調整や追加トレーニングなしに、別のモデルに直接使用することができる。
興味深い。jina-clip-v1ポケモンデータを含むLAION-400Mデータセットで学習したため、ポケモン分類の基本精度は31.36%と高い。一方 jina-clip-v2このモデルはDFN-2Bで学習されたもので、より質の高いデータセットですが、より多くのデータをフィルタリングし、おそらくポケモン関連のコンテンツも削除しているため、基本的な精度は低くなっています(16.10%)。
待って、この方法はどうやって使うの?
👩🏫 私たちがやったことを復習しよう。
私たちはまず、サンプル数がゼロの分布外(OOD)問題を扱えない、訓練済みの固定ベクトル・モデルを使い始めました。しかし、分類木を作ったところ、突然それができるようになったのです。その秘密は何だろう?伝統的な機械学習における弱い学習者の統合のようなものだろうか? 私たちのベクトルモデルが「悪い」から「良い」にアップグレードできるのは、統合学習それ自体のためではなく、分類木に含まれる外部のドメイン知識のためであることは注目に値する。ゼロサンプルで何千もの質問を繰り返し分類することはできますが、答えが最終結果に寄与しなければ意味がありません。20問の "you tell me, I guess "ゲームのようなもので、1問ごとに解答を徐々に絞り込んでいく必要がある。 このように、外部からの知識や思考プロセスこそが重要なのである。- 例のように、ポケモンシステムがどのように構築されているかがカギとなる。この専門知識は、人間から得ることも、大規模な言語モデルから得ることもできる。
pokemon_system品質.このCoTシステムを構築するには、マニュアルから完全自動化まで多くの方法があり、それぞれに長所と短所がある。1.マニュアル施工
2.LLMアシスト建設
我需要一个宝可梦分类系统。对于以下宝可梦:[Absol, Aerodactyl, Weedle, Caterpie, Azumarill, ...],创建一个包含以下内容的分类系统:
1. 基于以下视觉属性的分类组:
- 宝可梦的主要颜色
- 宝可梦的形态
- 宝可梦最显著的特征
- 宝可梦的整体体型
- 宝可梦通常出现的背景环境
2. 对于每个分类组:
- 创建一个自然语言提示模板,用 "{}" 表示选项
- 列出所有可能的选项
- 确保选项互斥且全面
3. 创建规则,将每个宝可梦映射到每个属性组中的一个选项,使用索引引用选项
请以 Python 字典格式输出,包含两个主要部分:
- "classification_groups": 包含每个属性的提示和选项
- "pokemon_rules": 将每个宝可梦映射到其对应的属性索引
示例格式:
{
"classification_groups": {
"dominant_color": {
"prompt": "This Pokemon's body is mainly {} in color.",
"options": ["white", "gray", ...]
},
...
},
"pokemon_rules": {
"Absol": {
"dominant_color": 0, # "white" 的索引
...
},
...
}
}
LLMは素早く初稿を作成するが、手作業によるチェックや修正も必要となる。
より確実なアプローチは次のようなものだ。 LLM生成と手動検証の組み合わせ.まずLLMに初期バージョンを生成させ、次に属性のグループ化、オプション、ルールを手動でチェックして修正し、その修正内容をLLMにフィードバックして、LLMが納得するまで改良を続ける。このアプローチは、効率と精度のバランスをとるものである。
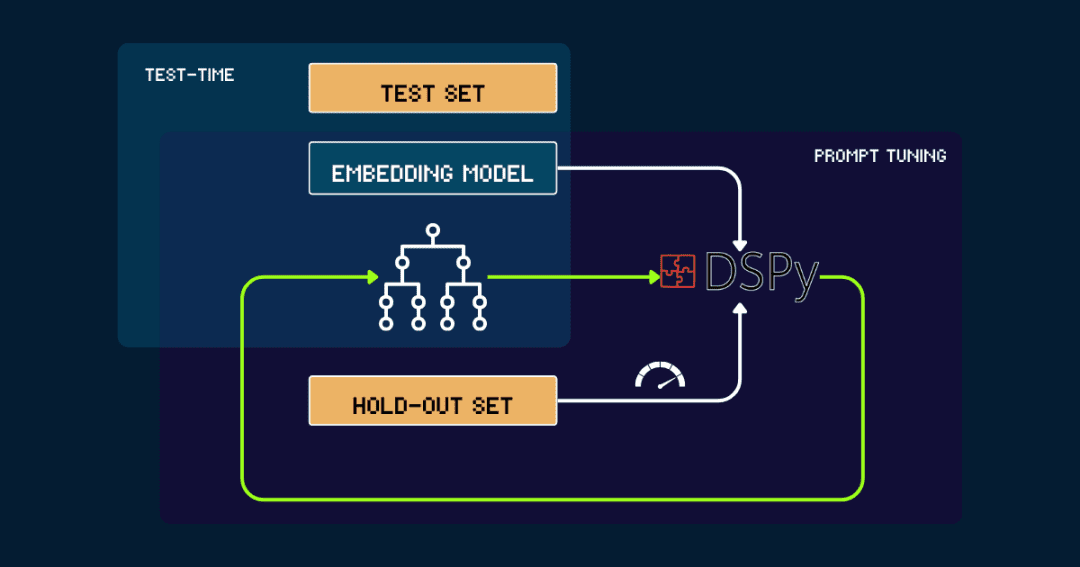
3.DSPyによる自動ビルド
完全自動ビルド pokemon_systemこれはDSPyで繰り返し最適化できる。
まずはシンプルに pokemon_system DSPyはこのフィードバックを使って、新しいデータを生成する。DSPyはこのフィードバックを使って新しい pokemon_systemパフォーマンスが収束し、大幅な改善が見られなくなるまで、このサイクルを繰り返す。
ベクトルモデルはプロセスを通して固定される.DSPyを使えば、最適なpokemon_system (CoT)設計を自動的に見つけることができ、タスクごとに一度だけチューニングする必要があります。
なぜベクトルモデルのテスト時間計算をスケーリングするのか?
事前学習済みモデルのサイズを常に大きくするコストがかかるため、持ち運ぶには高すぎる。
ジーナ・エンベッディング・コレクションjina-embeddings-v1そしてv2そしてv3 まで jina-clip-v1そしてv2そして jina-ColBERT-v1そしてv2しかし、アップグレードのたびに、より大きなモデル、より多くの事前訓練されたデータ、そして増大するコストに依存している。
取るjina-embeddings-v12023年6月に1億1,000万パラメータでリリースされる場合、トレーニングには5,000ドルから10,000ドルの費用がかかる。その頃には jina-embeddings-v3しかし、それはまだリソースにお金を投じることが中心である。現在、トップモデルのトレーニングコストは数千ドルから数万ドルに上昇し、大企業では数億ドルを費やさなければならないほどだ。事前トレーニングに投資すればするほど、モデルの結果は良くなるが、コストが高すぎて、費用対効果がどんどん低くなっている。
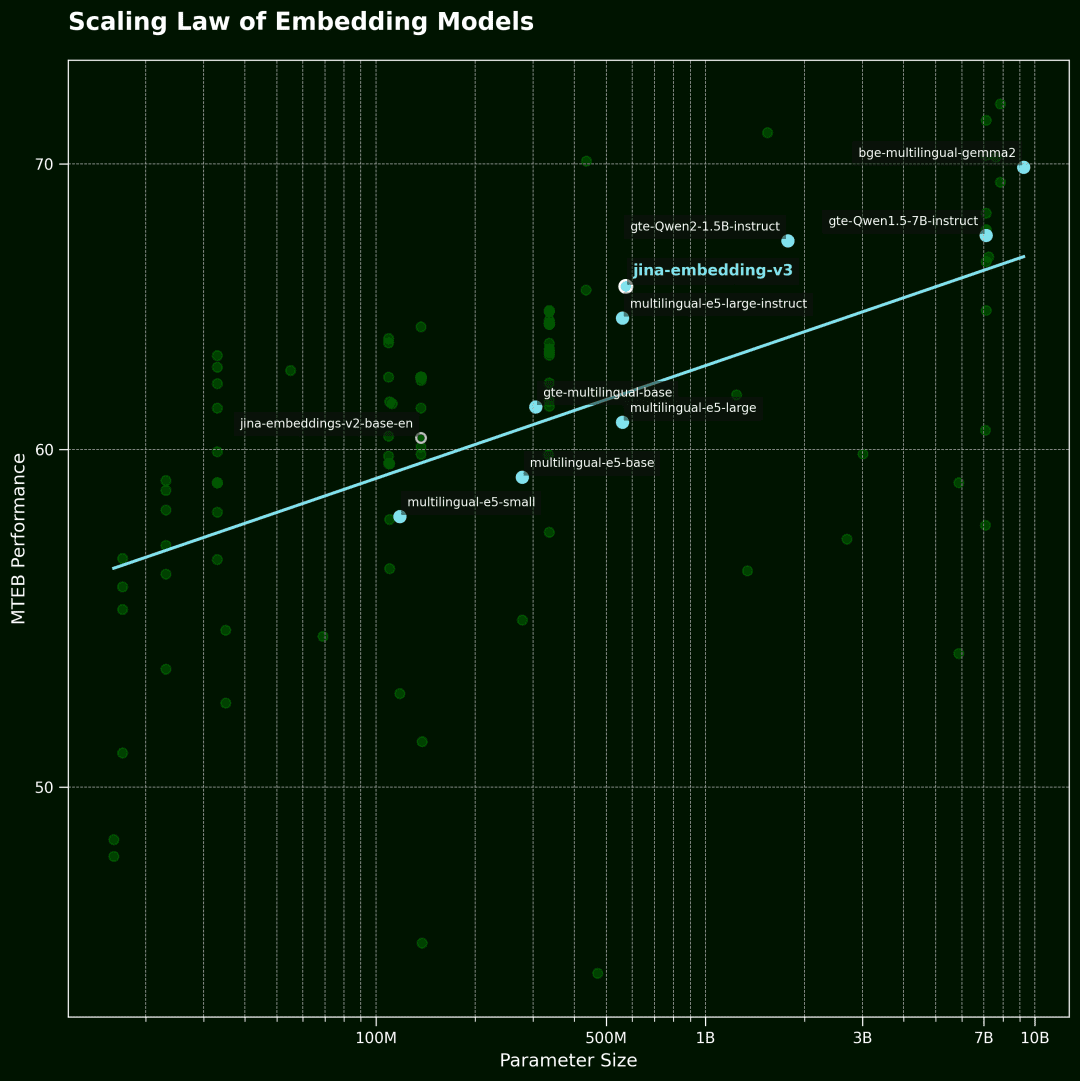
ベクトルモデリング スケーリングの法則
そしてこの図は、ベクトルモデルのScアリング法横軸はモデルパラメーターの数、縦軸はMTEBの平均性能である。各ポイントはベクトルモデルを表す。傾向線は全モデルの平均を表し、青い点は多言語モデルである。
データはMTEBランキングの上位100ベクターモデルから選択した。データの質を保証するため、モデルサイズの情報を開示していないモデルや、一部の無効な投稿を除外した。
一方、ベクトルモデルは現在、多言語、マルチタスク、マルチモーダル、優れたゼロサンプル学習と命令追従能力など、非常に強力なものとなっている。この多用途性により、アルゴリズムの改良や推論時の計算の拡張など、想像力豊かな可能性が大きく広がる。
重要なのは、そのことだ:ユーザーは、本当に関心のあるクエリにいくら支払っても構わないと思っているのだろうか。?事前に訓練された固定モデルの推論に少し時間をかけるだけで、結果の質が劇的に向上するのであれば、多くの人がそれに価値を見出すと確信している。
我々の意見では。推論時間計算の拡張は、ベクトルモデリングの分野で未開拓の大きな可能性を秘めているこれはおそらく、今後の研究にとって重要なブレークスルーとなるだろう。より大きなモデルを目指すのではなく、推論段階に力を入れ、パフォーマンスを向上させるために、より巧妙な計算方法を模索する方がよい。 -- この方が経済的で効果的なルートかもしれない。
評決を下す
ある jina-clip-v1/v2 実験では、以下のような重要な現象が見られた:
我々 モデルが見ていない、ドメイン外のデータについて(OOD)属より高い認識精度が達成され、モデルの微調整や追加トレーニングはまったく必要なかった。 このシステムは次のように機能する。 類似性検索と分類基準の反復的改良より細かな差別化が可能になる。 導入することで ダイナミックなキュー調整と反復推論(思考の連鎖 "に似ている)、ベクトルモデルの推論プロセスを単一のクエリーからより複雑な思考の連鎖へと変換する。
これはほんの始まりに過ぎない!スケーリング・テストタイム・コンピュートの可能性はこれをはるかに超える!しかし、探索すべき広大な空間がまだ残っている。例えば、「20の質問」ゲームにおける最適解戦略と同様に、最も効率的な戦略を繰り返し選択することで、解答空間を狭める、より効率的なアルゴリズムを開発することができる。推論時間計算を拡張することで、ベクトルモデルを既存のボトルネックから押し出すことができ、かつては手が届かないと思われていた複雑で細かなタスクを解き放ち、これらのモデルをより広範なアプリケーションに押し出すことができる。
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事


コメントはありません