
正しいエンベデッドモデルを選ぶには?

検索拡張生成(RAG)は、LLMモデル(ChatGPTなど)の知識を拡張するために自分のデータを使用することをサポートする、生成AI(GenAI)のアプリケーションのクラスです。
ラグ Embeddingモデル、Rerankearモデル、Big Languageモデルです。この記事では、データの種類や言語、特定のドメイン(法律など)に基づいて、適切なEmbeddingモデルを選択する方法について説明します。
1.テキストデータ:MTEBランキング
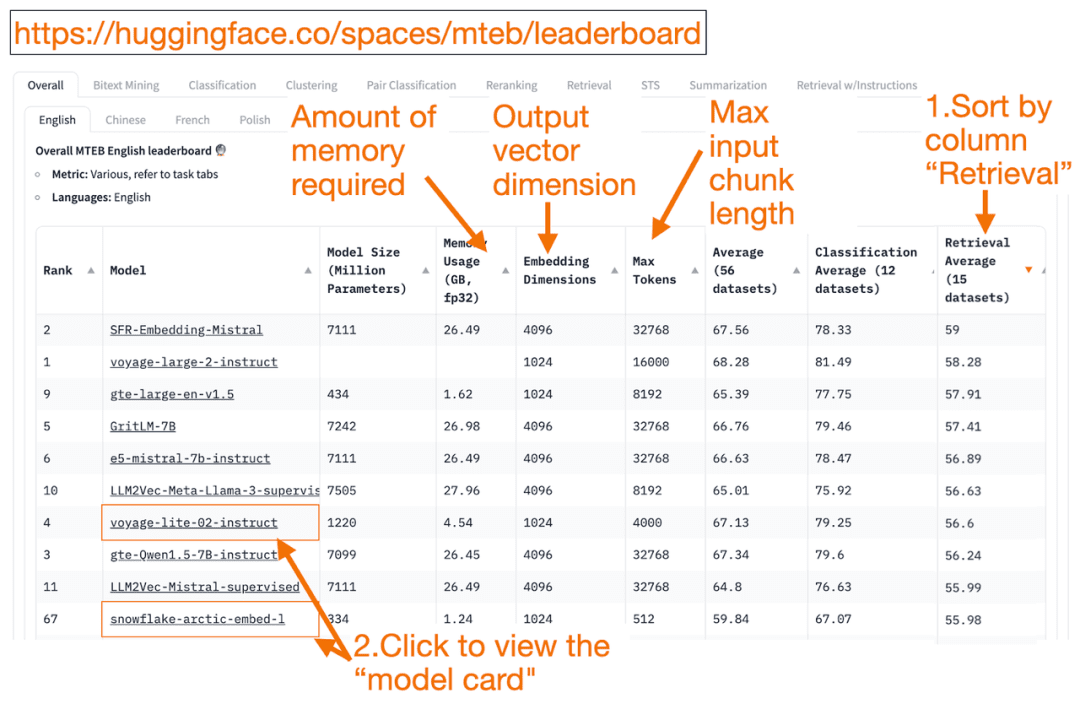
ハグ顔 MTEBリーダーボード は、テキスト埋め込みモデルのワンストップリストです!各モデルの平均性能を知ることができます。
検索平均」列を降順に並べ替えると、ベクトル検索タスクに最適です。そして、最もメモリフットプリントが小さく、最もランクの高いモデルを探します。
- 埋め込みベクトルの次元は、モデルが出力するベクトルの長さ、すなわちf(x)=yのyである。
- 最大 トークン この数字は、モデルに入力できる入力テキストブロックの長さ、つまりf(x)=yのxである。
をパスするだけでなく 検索 タスクの並べ替えに加え、以下の基準でフィルターをかけることもできます:
- 言語:フランス語、英語、中国語、ポーランド語に対応しています。(例: task=検索。
言語=中国語)
- 法律分野のテキスト。
例検索、言語=法律)
トレーニングデータの一部は最近になって公開されたものであるため、MTEBのエンベッディング・モデルの中には、以下のようなものがあることは注目に値する。よさげしかし、実際にランキングを膨らませた不適なモデルは、実際には異なるパフォーマンスを示す可能性がある。その結果、HuggingFaceはブログモデルランキングの信憑性を判断するためのポイントを解説しています。モデルのリンク(「モデルカード」と呼ばれる)をクリックした後:
- モデルがどのようにトレーニングされ、評価されるかを説明しているブログや論文を探す。モデルのトレーニングに使用されている言語、データ、タスクをよく見てください。また、有名な企業が作成したモデルも探しましょう。例えば、voyage-lite-02-instructモデルカードには、他のVoyageAIモデルがリストアップされていますが、このモデルはリストアップされていません。これがヒントです!このモデルはオーバーフィッティングモデルであり、使用すべきではありません!
- 下のスクリーンショットでは、スノーフレークの新モデル "snowflake-arctic-embed-1 "を試してみる。このモデルはランキングが高く、私のラップトップで実行できるほど小さく、モデルカードにブログや論文へのリンクがある。
HuggingFaceを使用する利点は、Embeddingモデルを選択した後にモデルを変更する必要がある場合、コード内のmodel_nameを変更するだけでよいということです!
import torch
from sentence_transformers import SentenceTransformer
# Initialize torch settings
torch.backends.cudnn.deterministic = True
DEVICE = torch.device('cuda:3' if torch.cuda.is_available() else 'cpu')
# Load the model from Huggingface
model_name = "WhereIsAI/UAE-Large-V1" # Just change model_name to use a different model!
encoder = SentenceTransformer(model_name, device=DEVICE)
# Get the model parameters and save for later
EMBEDDING_DIM = encoder.get_sentence_embedding_dimension()
MAX_SEQ_LENGTH_IN_TOKENS = encoder.get_max_seq_length()
# Print model parameters
print(f"model_name: {model_name}")
print(f"EMBEDDING_DIM: {EMBEDDING_DIM}")
print(f"MAX_SEQ_LENGTH: {MAX_SEQ_LENGTH_IN_TOKENS}")

2.画像データ:ResNet50
入力した画像に似た画像を検索したい場合もあるでしょう。例えば、スコティッシュ・フォールド・キャットの画像をもっと探している場合です。このような場合、スコティッシュ・フォールド・キャットの画像をアップロードして、検索エンジンに類似画像を検索してもらうことができます。
ResNet50 は、もともと2015年にマイクロソフトがImageNetデータを使って訓練した人気のCNNモデルである。
同様にビデオ検索この場合でもResNet50はビデオを埋め込みベクトルに変換することができる。そして、静的なビデオフレームに対して類似性検索が実行され、最も類似したビデオがベストマッチとしてユーザーに返される。
3.オーディオデータ:PANN
画像検索と同様に、入力されたオーディオクリップから類似のオーディオを検索することもできます。
PANN(PANNは大規模なオーディオデータセットで事前にトレーニングされており、オーディオ分類やラベリングなどのタスクに優れているためです。
4. マルチモーダルな画像とテキストデータ:
シグリップまたはユナム
近年、非構造化データ(テキスト、画像、音声、動画)の混合データに対して学習させたEmbeddingモデルが数多く登場している。これらのモデルは、複数のタイプの非構造化データのセマンティクスを、同じベクトル空間で同時に捉えることができる。
マルチモーダル埋め込みモデルは、テキストを使った画像の検索、画像のテキスト説明文の生成、画像の検索をサポートする。
OpenAIは2021年に発足 クリップ が標準的なエンベッディング・モデルである。しかし、ユーザーが自分で微調整する必要があり、使いにくかったため、2024年までにグーグルは シグリップ(Sigmoidal-CLIP)。このモデルは、ゼロショットプロンプトを使用した場合に良好な性能を達成した。
今日、小規模LLMモデルの人気が高まっている。これらのモデルは大規模なクラウドクラスターを必要とせず、ノートパソコンで実行できるからだ。小型のモデルは、大型のモデルよりもメモリ使用量が少なく、レイテンシーが低く、実行速度が速い。ユナム マルチモーダルなミニエンベディングモデルを提供。
5.マルチモーダルなテキスト、オーディオ、ビデオデータ
ほとんどのマルチモーダルテキスト音声RAGシステムはマルチモーダル生成LLMを使用しており、まず音声をテキストに変換し、音声とテキストのペアを生成し、次にテキストをEmbeddingベクトルに変換します。その後、RAGを使って通常通りテキストを取り出すことができる。最後のステップで、テキストは音声にマッピングされる。
オープンAI ウィスパー は音声をテキストに書き起こすことができる。さらに、OpenAIの 音声合成 (TTS) モデルはテキストをオーディオに変換することもできる。
マルチモーダルなテキスト-ビデオRAGシステムは、まずビデオをテキストにマッピングし、それをEmbeddingベクトルに変換し、テキストを検索し、検索結果としてビデオを返すという同様のアプローチを採用している。
オープンAI ソラ テキストをビデオに変換できる。Dall-eと同様、LLMがビデオを生成する間、あなたはテキストプロンプトを提供します。Soraはまた、静止画像や他のビデオからビデオを生成することができます。
Milvusは現在、主流のEmbeddingモデルを統合しています:https://milvus.io/docs/embeddings.md
協議
MTEBリーダーボード:https://huggingface.co/spaces/mteb/leaderboard
MTEBベストプラクティス:https://huggingface.co/blog/lyon-nlp-group/mteb-leaderboard-best-practices
類似画像検索: https://milvus.io/docs/image_similarity_search.md
イメージビデオ検索: https://milvus.io/docs/video_similarity_search.md
類似のオーディオ検索: https://milvus.io/docs/audio_similarity_search.md
テキスト画像検索:https://milvus.io/docs/text_image_search.md
2024 SigLIP(Sigmoid loss CLIP)紙: https://arxiv.org/pdf/2401.06167v1
ウナム・マルチモーダル埋め込みモデル:
https://github.com/unum-cloud/uform
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事



コメントはありません