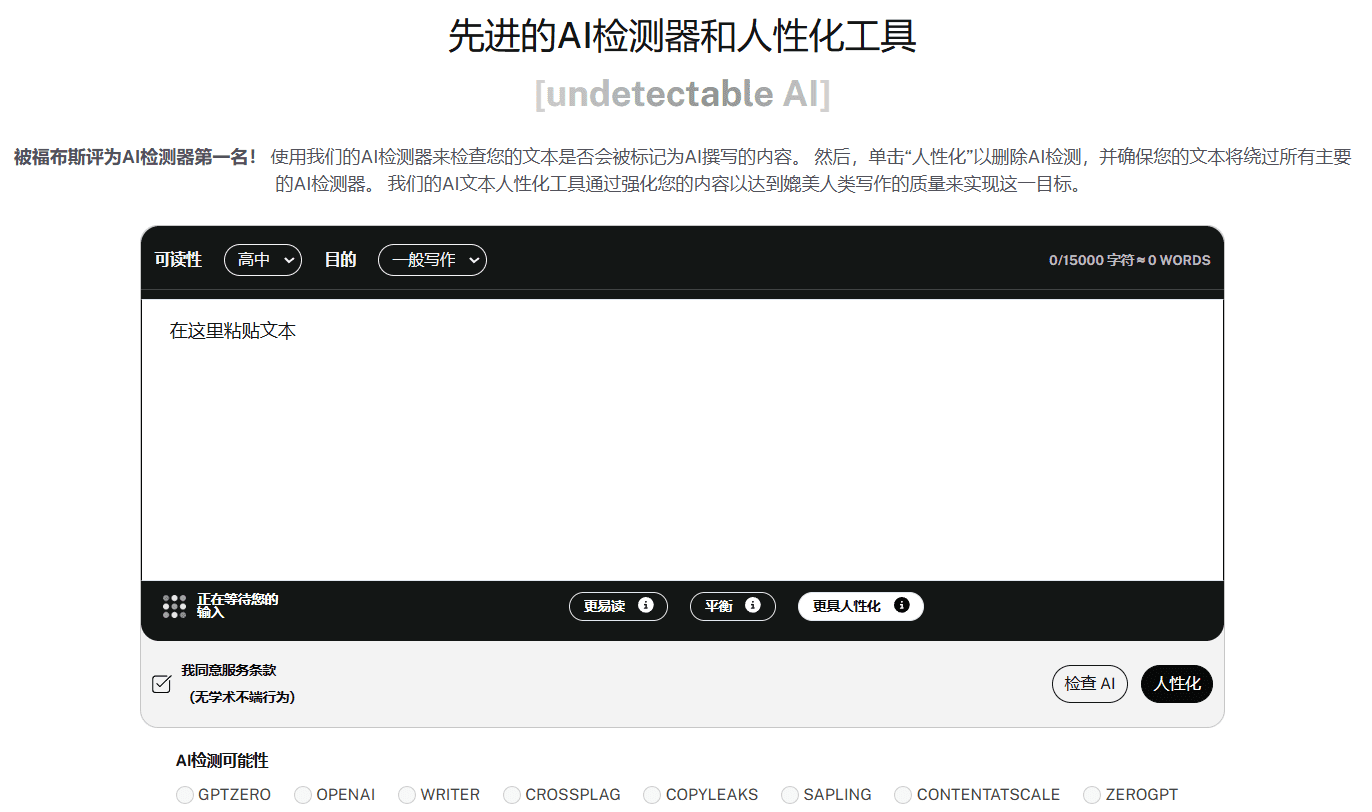
RapBank: 歌詞とバッキングトラックからラップ(Rap)ボーカルを直接生成するモデル(現在オープンデータセット)

はじめに
RapBankは、ラップ歌詞生成のために設計されたデータセットとツールセットです。NZqianによって作成されたこのプロジェクトは、YouTubeからラップソングを収集・処理することで、研究者や開発者に高品質のラップ歌詞データセットを提供することを目的としている。RapBankには、84言語、90,000曲以上のラップソングが含まれており、ユーザーが効率的にデータを処理し、モデルを学習できるように、詳細な処理パイプラインと使用方法を提供している。このプロジェクトのデータとコードは、CC BY-NC-SA 4.0ライセンスの下、GitHubでオープンソースとして公開されている。
人声的模型(目前开放了数据集)-1")
機能一覧
- データセットダウンロード: 90,000曲以上のラップを多言語で収録したデータセット。
- データ処理パイプライン:ソース分離、セグメンテーション、歌詞認識などのステップを含み、ユーザーが効率的にデータを処理できるよう支援する。
- 詳細なドキュメント:ユーザーがすぐに使い始められるように、完全な手順とサンプルコードを提供します。
- オープンソースコード:すべてのコードとデータはGitHubでオープンソース化されており、ユーザーが二次開発を行うのに便利です。
- ライセンス契約:データとコードはCC BY-NC-SA 4.0ライセンス契約の対象となり、利用者が合法的な範囲内に留まることを保証します。
ヘルプの使用
設置プロセス
- クローン・プロジェクト・ウェアハウス
git clone https://github.com/NZqian/RapBank.git
cd RapBank
- 依存関係をインストールします:
pip install -r requirements.txt
- データセットをダウンロードし、指定されたフォルダに置く。
/path/to/your/data/wav.
データ処理
- 提供されたスクリプトを使用してデータを処理する:
bash pipeline.sh /path/to/your/data /path/to/save/features start_stage stop_stage
start_stage歌で応えるstop_stageパラメーターは、処理の開始段階と終了段階を指定するために使われ、0から5まである。- より高速に処理するためには、複数のGPUを推奨する。
機能 操作の流れ
- データセットのダウンロード: GitHubページにアクセスして、必要なデータセットファイルをダウンロードしてください。
- データ処理:上記の手順に従って依存関係をインストールし、処理スクリプトを実行して必要なフィーチャーファイルを生成します。
- モデルトレーニング:処理されたデータをモデルトレーニングに使用する。具体的な手順については、プロジェクトドキュメントのサンプルコードを参照してください。
- 結果の分析:生成されたモデルを使用したラップ歌詞の生成、結果の分析と最適化。
詳細機能
- データセットダウンロード90,000曲以上のラップのデータセットが用意されており、必要に応じてダウンロードして研究開発に利用することができる。
- データ処理パイプラインソース分離、セグメンテーション、歌詞認識などの複数のステップを含み、ユーザーが効率的にデータを処理、分析できるようにします。
- 詳細資料このプロジェクトは、ユーザーがすぐに開発を始められるように、完全な手順とサンプルコードを提供しています。
- オープンソースすべてのコードとデータはGitHub上でオープンソース化されており、ユーザーは自由にダウンロードして使用することができます。
- ライセンスデータとコードはCC BY-NC-SA 4.0ライセンスに準拠しており、利用者が合法的な範囲内で使用していることを保証します。
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事


コメントはありません