Qwen3-ASR-Flash - Ali Tongyi Qianqianが発表した一連の音声認識モデル。

Qwen3-ASR-Flashとは何ですか?
Qwen3-ASR-Flashは、アリババが開発した最新の高精度音声認識モデルです。 クウェン3 膨大なマルチモーダルデータによって学習されたベースモデル。北京語、四川語、閩南語、呉語、広東語などの方言や、イギリス英語、アメリカ英語など、11の言語と複数のアクセントをサポートしています。主な特徴として、トップクラスの認識精度、圧倒的な歌認識能力(エラー率8%以下)、カスタマイズ認識(ユーザーが背景テキストを提供することで、カスタマイズされた結果を得ることができる)、非ボーカルリジェクションによる言語認識、複雑な音響環境における高いロバスト性が挙げられる。ユーザーは、ModelScope、Hugging Face、AliCloud Hundred Refinements APIを通じて、このモデルを無料で体験することができます。
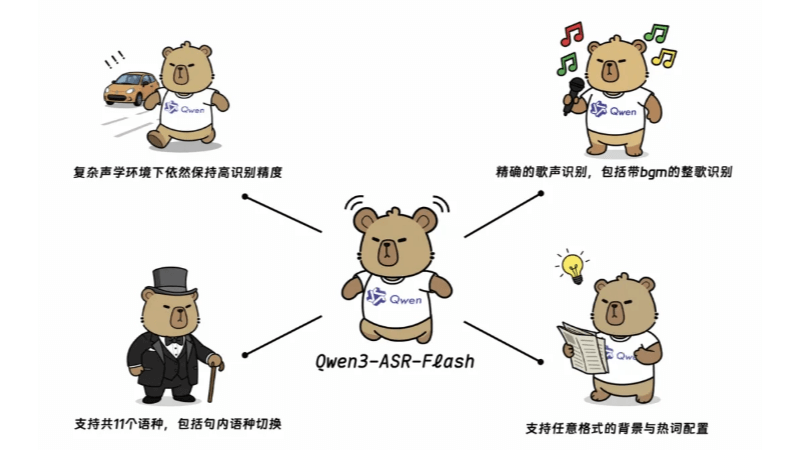
Qwen3-ASR-Flash 機能的特徴
- 高精度の認識英語、中国語、多言語ベンチマークで最高のパフォーマンスを発揮し、複数の言語や方言を正確に認識。
- 楽曲認識このシステムは、きれいな歌唱とBGM付きの全曲認識をサポートし、測定されたエラー率は8%より低い。
- カスタマイズされた識別ユーザーは背景テキストをどのような形式でも提供することができ、モデルはそれに応じて認識結果を調整することができる。
- 言語認識と非音声拒否音声言語を正確に識別し、無音や背景雑音などの非音声セグメントを自動的にフィルタリングします。
- 高い堅牢性複雑な音響環境や、長文や難解な文、文の途中で言語が切り替わるような難しいテキストパターンに直面しても、高い精度を維持します。
Qwen3-ASR-Flashの主な利点
- 高精度の認識多言語および方言認識テストにおいて、競合製品よりも低いエラー率で優れたパフォーマンスを発揮。
- 多言語サポート1つのモデルで、北京語、英語、フランス語、ドイツ語など、11の言語と複数の方言をサポートしています。
- カスタマイズされた識別ユーザは背景テキストを任意のフォーマットで提供でき、モデルは文脈情報をインテリジェントに利用して、カスタマイズされた認識結果を出力します。
- 楽曲認識きれいな歌唱とBGM付きの全曲認識をサポートし、測定されたエラー率は8%より低く、歌唱認識の分野では優れた性能である。
- 言語認識と非音声拒否音声言語を正確に区別し、無音や背景雑音などの非音声セグメントを自動的にフィルタリングできるため、認識効率が向上します。
- 高い堅牢性複雑な音響環境や、長文や難解な文、文の途中で言語が切り替わるような難しいテキストパターンに直面しても、高い精度を維持します。
Qwen3-ASR-Flashの公式サイトは?
- プロジェクトのウェブサイトhttps://bailian.console.aliyun.com/?spm=5176.29597918.J_tAwMEW-mKC1CPxlfy227s.1.4f007b08aWhTjW&tab=model#/model-market/detail/group-qwen3-asr-flash?modelGroup=group-qwen3-asr-flash
- オンライン体験デモ:: https://huggingface.co/spaces/Qwen/Qwen3-ASR-Demo
Qwen3-ASR-Flashの対象者
- 高精度の音声書き起こしを必要とするユーザー例えば、ジャーナリスト、会議録音者、研究者などは、音声コンテンツを素早く正確にテキストに変換することができます。
- ポリグロット例えば、外国語学習者、多国籍企業の従業員、国際会議の参加者など。
- コンテンツクリエータービデオブロガーやポッドキャストホストなどは、字幕やトランスクリプトを効率的に作成することができます。
- その道のプロフェッショナル例えば、医療、金融、法律分野の実務者は、カスタマイズされた認識機能を使用して、専門用語を正確に識別することができる。
- 特別な音声認識が必要な方例えば、聴覚障害者は、モデルの助けを借りて音声情報をより良く理解することができます。また、接客係や現場記者など、騒がしい環境で音声認識を必要とするユーザーもいます。
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事

コメントはありません