
Qwen2.5-1M: 100万トークンコンテキストをサポートするオープンソースQwenモデル

1.はじめに
2ヶ月前、QwenチームはQwen2.5-Turboをアップグレードし、最大100万トークンのコンテキスト長をサポートした。本日、QwenはオープンソースのQwen2.5-1Mモデルとそれに対応する推論フレームワークのサポートを正式に開始した。リリースのハイライトは以下の通り:
オープンソースモデル: 2つの新しいオープンソースモデルが発表された。 Qwen2.5-7B-Instruct-1M 歌で応える Qwen2.5-14B-Instruct-1MQwenがオープンソースのQwenモデルのコンテキストを1Mの長さに拡張したのは今回が初めてである。
推論の枠組み: 開発者が Qwen2.5-1M モデルファミリーをより効率的に展開できるように、Qwen チームは、Qwen2.5-1M モデルを完全にオープンソース化しました。 ブイエルエルエム スパース・アテンション・アプローチを統合した推論フレームワークにより、1Mのラベル付き入力をより高速に処理できるようになった。 3倍から7倍.
テクニカルレポート: Qwenチームはまた、トレーニングや推論フレームワークの設計思想、アブレーション実験の結果など、Qwen2.5-1Mシリーズの技術的な詳細についても共有した。
モデルリンクhttps://www.modelscope.cn/collections/Qwen25-1M-d6cf9fd33f0a40
テクニカルレポート:https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen2.5-1M/Qwen2_5_1M_Technical_Report.pdf
経験リンクhttps://modelscope.cn/studios/Qwen/Qwen2.5-1M-Demo
2.モデルの性能
まず、Qwen2.5-1Mファミリーの長文文脈タスクと短文文脈タスクにおける性能を見てみよう。
ロングコンテキストタスク
コンテキストの長さは100万 トークン パスキー検索タスクでは、Qwen2.5-1Mファミリーのモデルは、1M長の文書から隠された情報を正確に検索し、7Bモデルのエラーはわずかであった。
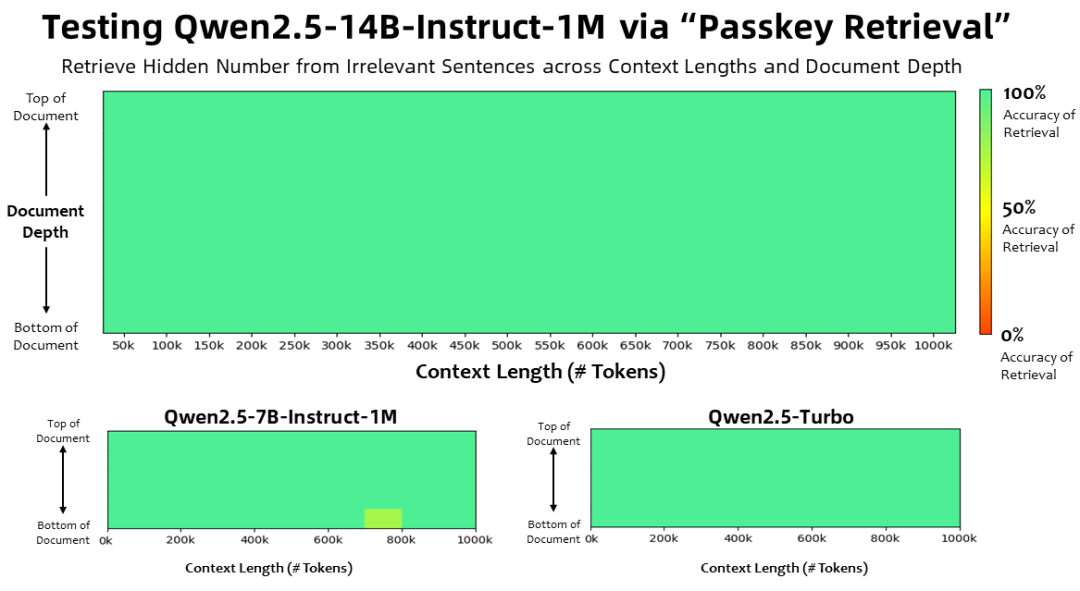
より複雑な長い文脈を理解するタスクには、RULER、LV-Eval、LongbenchChatのテストセットが選ばれた。
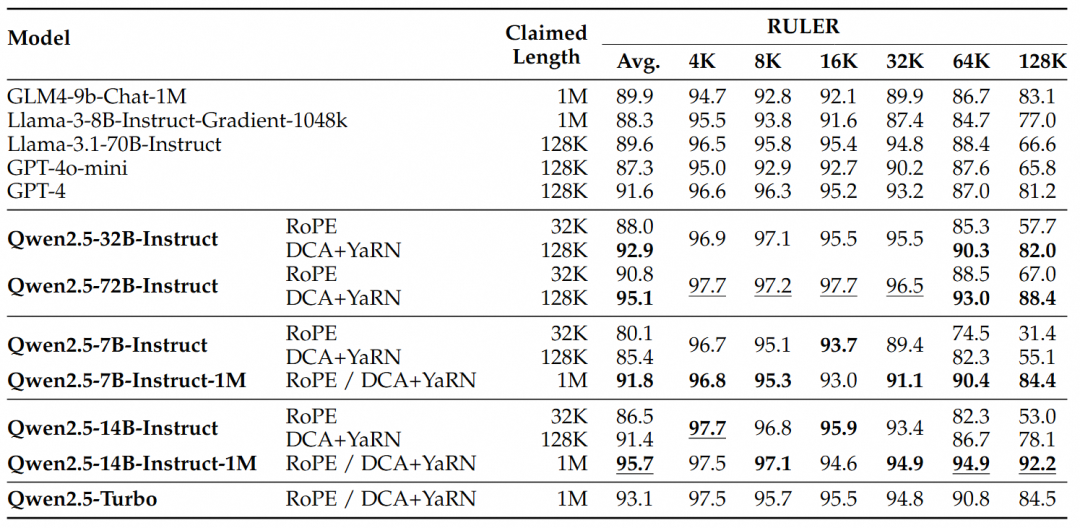
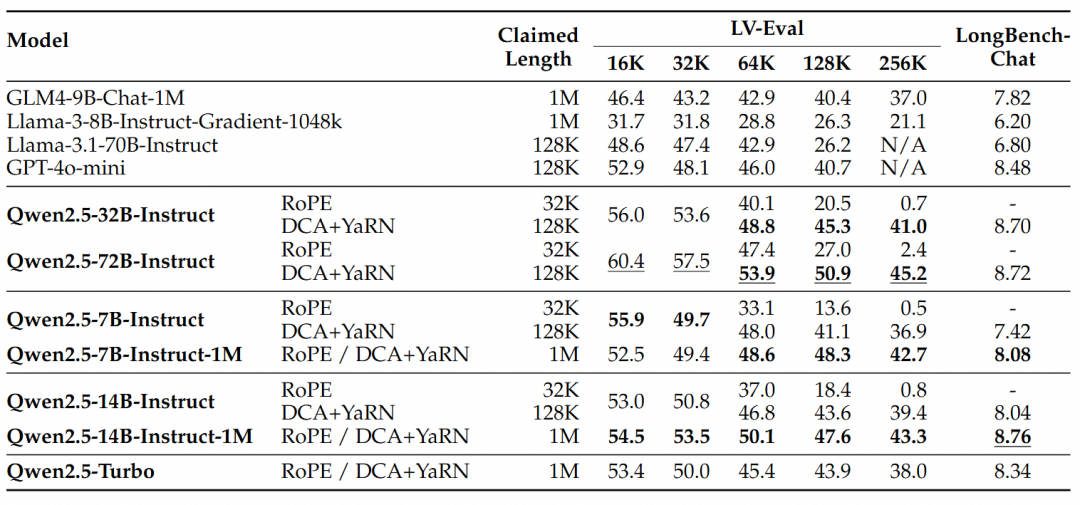
これらの結果から、次のような重要な結論を導き出すことができる:
- 128Kバージョンを大幅に上回る:Qwen2.5-1Mファミリーは、ほとんどの長いコンテキスト・タスク、特に64Kを超える長さのタスクを扱う場合、以前の128Kバージョンを大幅に上回る性能を発揮する。
- パフォーマンスの優位性は明らかだ:Qwen2.5-14B-Instruct-1Mモデルは、Qwen2.5-Turboを上回るだけでなく、複数のデータセットにおいてGPT-4o-miniを常に上回っており、長いコンテキストのタスクに最適なオープンソースモデルを提供しています。
ショートシーケンシャルタスク
長いシーケンスのタスクでの性能に加えて、短いシーケンスでのモデルの性能も同様に重要である。Qwen2.5-1Mシリーズと以前の128Kバージョンを、広く使用されている学術ベンチマークで比較し、比較のためにGPT-4o-miniを追加した。 
見つけることができる:
- Qwen2.5-7B-Instruct-1MとQwen2.5-14B-Instruct-1Mの短文タスクの性能は、128K版と同等であり、長文処理機能の追加によって基本性能が損なわれていないことが確認された。
- GPT-4o-miniと比較して、Qwen2.5-14B-Instruct-1MとQwen2.5-Turboは、文脈の長さがGPT-4o-miniの8倍であるにもかかわらず、短文タスクで同程度の性能を達成した。
3.キーテクノロジー
ロングコンテキストトレーニング
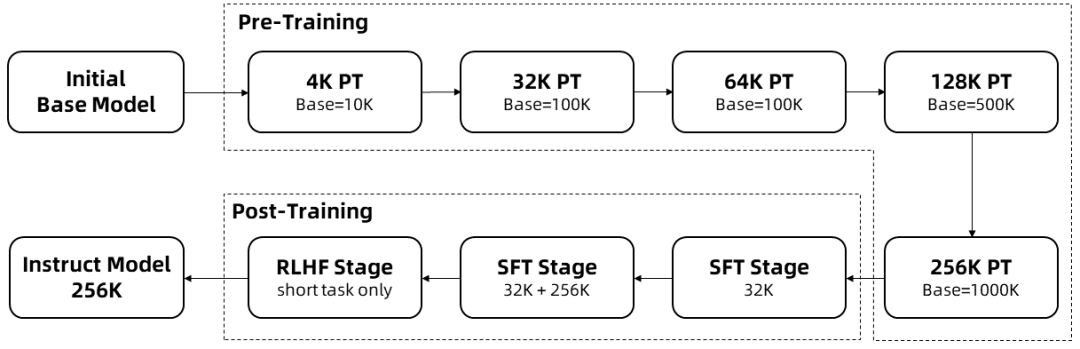
長い配列の学習には多くの計算資源を必要とするため、Qwen2.5-1Mのコンテキスト長を4Kから256Kまで多段階に拡張する段階的拡張が用いられた:
事前学習済みのQwen2.5の中間チェックポイントからスタートし、この時点でのコンテキスト長は4Kである。
トレーニング前の段階さらに、コンテキスト長は4Kから256Kへと徐々に増加させ、RoPEのベース周波数は調整ベース周波数スキームを用いて10,000から10,000,000へと増加させた。
モニタリングの微調整段階短いシーケンスのパフォーマンスを維持するために、2段階に分けている:
第一段階: 微調整は、短い命令(長さ32Kまで)に対してのみ行われ、Qwen2.5の128Kバージョンと同じデータとステップ数が使用される。
第二段階: 短い(最大32K)命令と長い(最大256K)命令が混在して実装されており、短いタスクの品質を維持しながら長いタスクの性能を向上させている。
集中学習段階これは、短いテキスト(最大8Kトークン)でモデルを訓練するものである。短いテキストで訓練した場合でも、人間が好むアライメントを向上させることは、長いコンテキストのタスクにもよく一般化することがわかった。 上記のトレーニングにより、最大256Kトークンの長さのシーケンスを処理できるInstructモデルが完成した。
以上の学習により、256Kのコンテキスト長を持つ命令微調整モデルが得られる。
長さの外挿
上記の学習プロセスでは、モデルのコンテキスト長はわずか256Kトークンである。これを1Mトークンに拡張するために、長さの外挿技術が使用された。
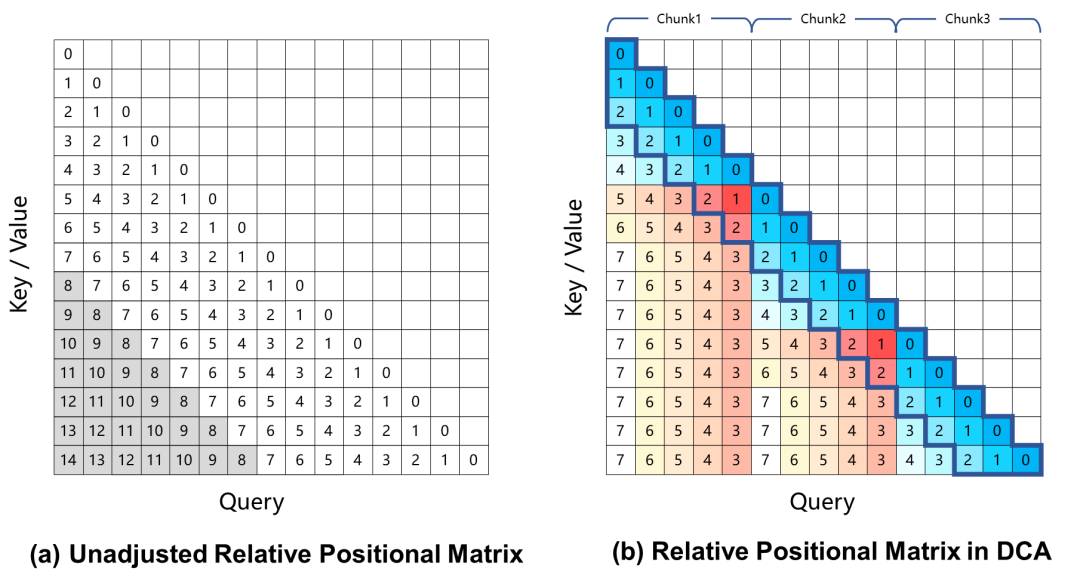
現在のところ、回転位置エンコーディングに基づく大規模言語モデルは、長い文脈タスクにおいて性能劣化を引き起こす。これは主に、注意の重みを計算する際に、学習過程では見えない、クエリとキーの間の大きな相対位置距離に起因する。この問題を解決するために、Qwen2.5-1Mは、過剰に大きな相対位置を取り出し、より小さな値に再マッピングすることでこの課題を解決する、デュアルチャンクアテンション(DCA)アプローチを採用しています。
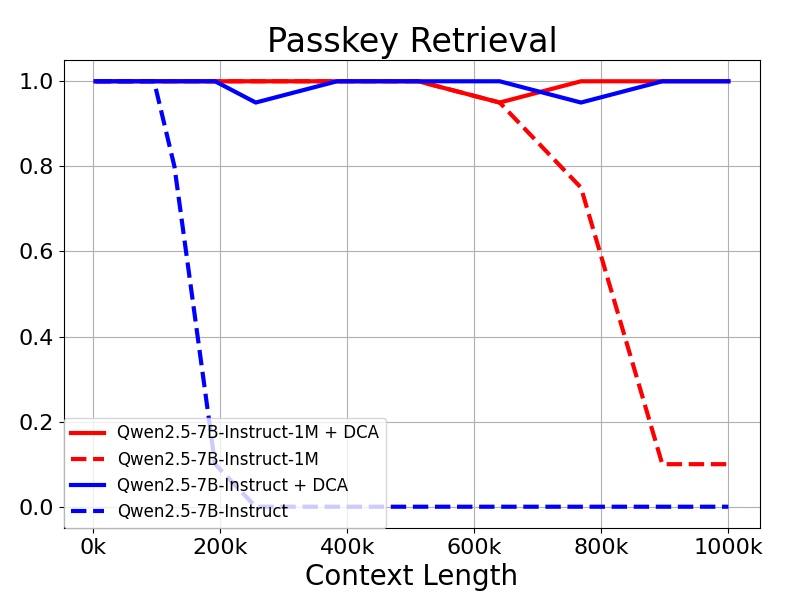
Qwen2.5-1Mモデルと旧128Kモデルは、長さ外挿法の有無で評価された。
その結果、Qwen2.5-7B-Instructのような32Kトークンのみで訓練されたモデルでさえ、Passkeyの1Mトークンのコンテキストに対応できないことがわかった。 検索 タスクでもほぼ完璧な精度を示した。これは、追加の訓練なしにサポートされるコンテキストの長さを大幅に拡張するDCAの力を実証している。
疎な注意メカニズム
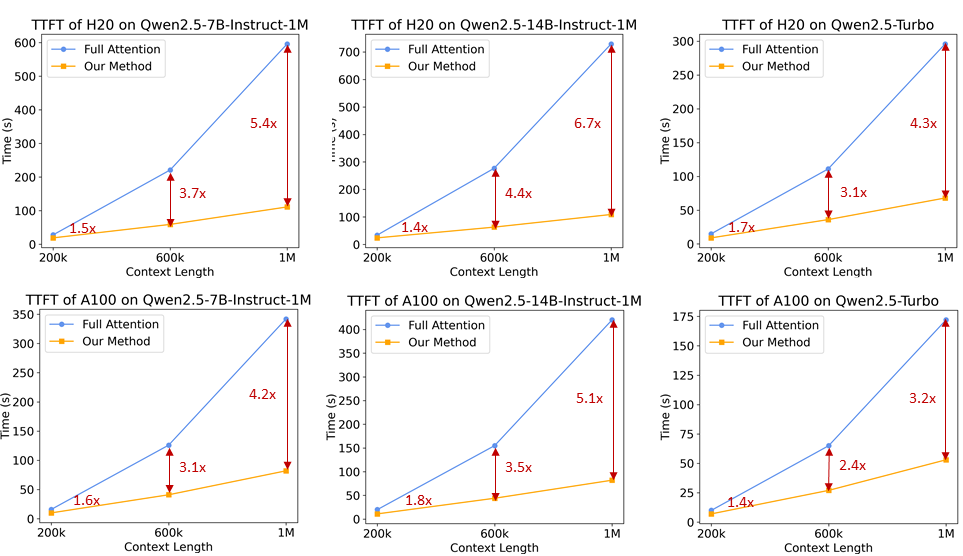
長いコンテキストの言語モデルにとって、推論速度はユーザーエクスペリエンスにとって極めて重要である。プリ・ポピュレーション段階を高速化するために、研究チームはMInferenceに基づくスパース・アテンション・メカニズムを導入している。さらに、いくつかの改良も提案されている:
- Chunked Prefill:長さ100万までのシーケンスを処理するためにモデルを直接使用した場合、MLP層の活性化重みはQwen2-5-7Bの場合最大71GBという膨大なメモリオーバヘッドを生じます。Qwen2.5-7Bを例にとると、この部分のオーバーヘッドは71GBにもなります。 Chunked Prefill with Sparse Attentionを適応することで、入力シーケンスを32768の長さにチャンクして1つずつプリフィルすることができ、MLP層の活性化重みのメモリ使用量を96.7%減らすことができるため、デバイスのメモリ要件を大幅に削減することができます。
- 統合された長さ外挿スキーム:DCAに基づく長さ外挿スキームをスパース注意メカニズムにさらに統合することで、我々の推論フレームワークは長いシーケンスタスクに対してより高い推論効率と精度の両方を享受することができる。
- Sparsity Optimisation: オリジナルのMInferenceメソッドは、各注意ヘッドに最適なスパース化構成を決定するためにオフライン検索を必要とする。この探索は通常短い配列に対して実行され、完全な注意重みのメモリ要件が大きいため、長い配列では必ずしもうまく機能しない。我々は、長さ100万の配列に対してスパース化構成を最適化できる方法を提案し、これによりスパース注意による精度の損失を大幅に低減する。
- その他の最適化:フレームワーク全体のポテンシャルを最大限に引き出すために、演算効率の最適化やパイプライン並列の動的チャンキングなど、その他の最適化も導入した。
これらの機能強化により、推論フレームワークは1M トークン 長さの配列の前増殖速度は3.2倍から6.7倍に増加した。
4.モデル展開
システム準備
最高のパフォーマンスを得るには、最適化されたコアをサポートするAmpereまたはHopperアーキテクチャのGPUを使用することをお勧めします。
以下の条件を満たしていることをご確認ください:
- CUDAバージョン:12.1または12.3
- Pythonバージョン:>=3.9および<=3.12
1M長のシーケンスを処理するのに必要なメモリ:
- Qwen2.5-7B-Instruct-1M:少なくとも120GBのビデオメモリが必要(マルチGPUの合計)。
- Qwen2.5-14B-Instruct-1M: 少なくとも320GBのビデオメモリが必要です(マルチGPUの合計)。
GPUメモリがこれらの要件を満たさない場合でも、Qwen2.5-1Mを短時間のタスクに使用することができます。
依存関係のインストール
当面は、カスタムブランチからvLLMリポジトリをクローンし、手動でインストールする必要がある。研究チームは、そのブランチをvLLMプロジェクトにコミットする作業を行っている。
git clone -b dev/dual-chunk-attn git@github.com:QwenLM/vllm.git cd vllm pip install -e . -v
OpenAI互換APIサービスの開始
モデルが ModelScope からダウンロードされることを指定します。
export VLLM_USE_MODELSCOPE=True
OpenAI対応APIサービスのリリース
vllm serve Qwen/Qwen2.5-7B-Instruct-1M \ --tensor-parallel-size 4 \ --max-model-len 1010000 \ --enable-chunked-prefill --max-num-batched-tokens 131072 \ --enforce-eager \ --max-num-seqs 1
パラメータの説明
--tensor-parallel-size- 7Bモデルは最大4GPU、14Bモデルは最大8GPUをサポートします。
--max-model-len- 入力シーケンスの最大長を定義する。メモリ不足の問題が発生した場合は、この値を小さくする。
--max-num-batched-tokens- Chunked Prefill のブロックサイズを設定します。値を小さくすると起動時のメモリ使用量は減りますが、推論が遅くなる可能性があります。
- 最適なパフォーマンスを得るために推奨される値は131072である。
--max-num-seqs- 同時に処理するシーケンス数を制限する。
モデルとの対話
デプロイされたモデルを操作するには、以下のメソッドを使用できます:
オプション1。
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "Qwen/Qwen2.5-7B-Instruct-1M",
"messages": [
{
"role": "user",
"content": "Tell me something about large language models."
}
],
"temperature": 0.7,
"top_p": 0.8,
"repetition_penalty": 1.05,
"max_tokens": 512
}'
オプション2.Pythonを使う
from openai import OpenAI
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:8000/v1"
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
prompt = (
"""There is an important info hidden inside a lot of irrelevant text.
Find it and memorize them. I will quiz you about the important information there.\n\n
The pass key is 28884. Remember it. 28884 is the pass key.\n"""
+ "The grass is green. The sky is blue. The sun is yellow. Here we go. There and back again. " * 800
+ "\nWhat is the pass key?"
)
# The prompt is 20k long. You can try a longer prompt by replacing 800 with 40000.
chat_response = client.chat.completions.create(
model="Qwen/Qwen2.5-7B-Instruct-1M",
messages=[
{"role": "user", "content": prompt},
],
temperature=0.7,
top_p=0.8,
max_tokens=512,
extra_body={
"repetition_penalty": 1.05,
},
)
print("Chat response:", chat_response)
Qwen-Agentのような他のフレームワークも検討し、モデルがPDFファイルなどを読めるようにすることもできます。
5.Magic Hitch API-Inference を使用して、直接
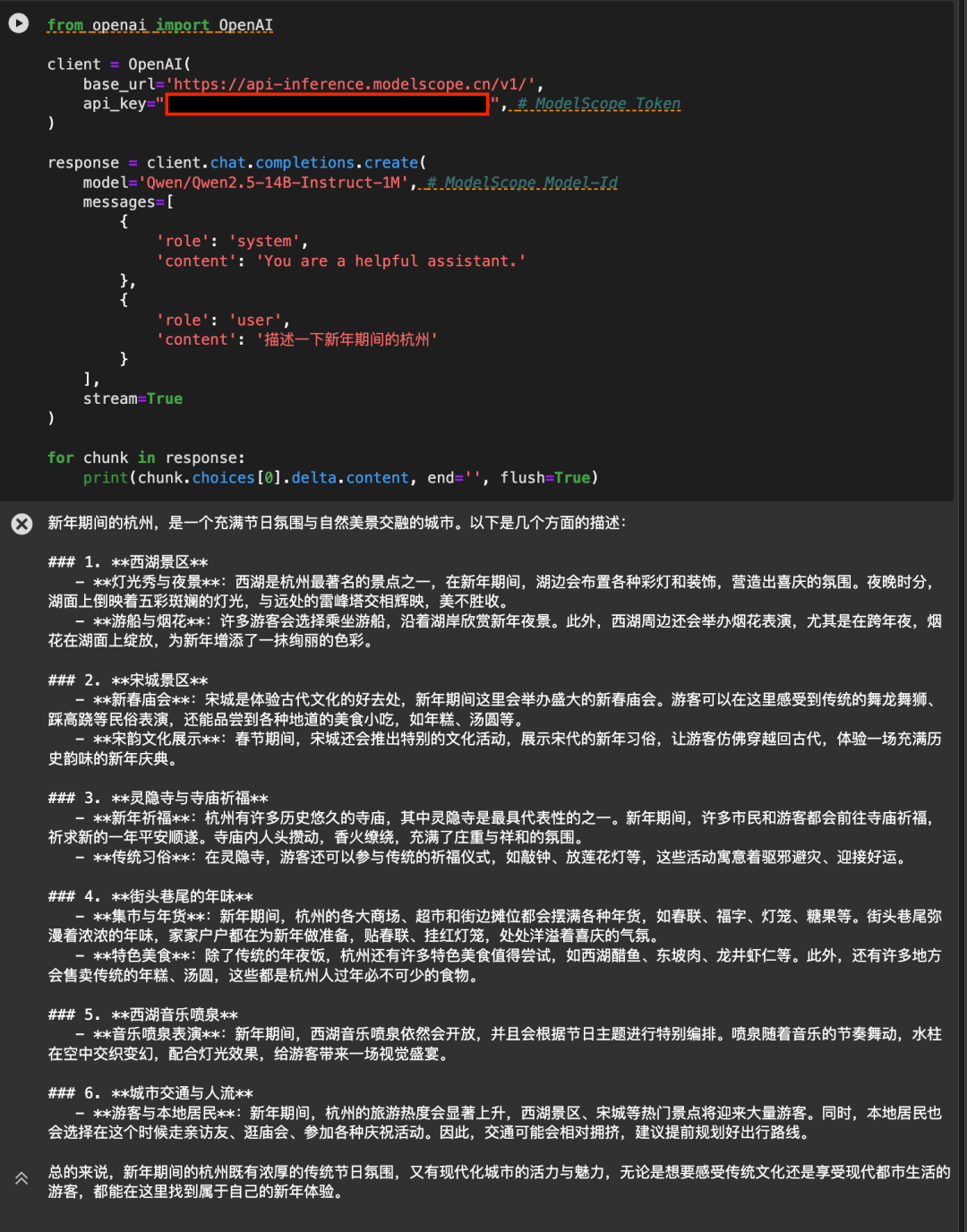
Magic MatchプラットフォームのAPI-Inferenceは、Qwen2.5-7B-Instruct-1MとQwen2.5-14B-Instruct-1Mモデルを初めてサポートします。Magic Hitchのユーザーは、APIコールによってモデルを直接使用することができます。具体的なAPI-Inferenceの使用方法は、モデルのページ(例:https://modelscope.cn/models/Qwen/Qwen2.5-14B-Instruct-1M )に記載されています:

または、API-Inferenceのドキュメントhttps://www.modelscope.cn/docs/model-service/API-Inference/intro。
AliCloud Hundred Refinement Platformに感謝する。
Ollamaとllamafileの使用
Magic Hitchでは、ローカルでの利用を容易にするために、Qwen2.5-7B-Instruct-1MモデルのGGUF版とllamafile版を最初に提供しています。Ollamaフレームワークから呼び出すこともできますし、llamafileを直接引っ張ってくることもできます。
1.オーラマ・コール
まずollamaをenableに設定する:
ollama serve
そして、ollama runというコマンドを使って、Magic Hitch上でGGUFモデルを直接実行することができる:
ollama run modelscope.cn/modelscope/Qwen2.5-7B-Instruct-1M-GGUFランの結果
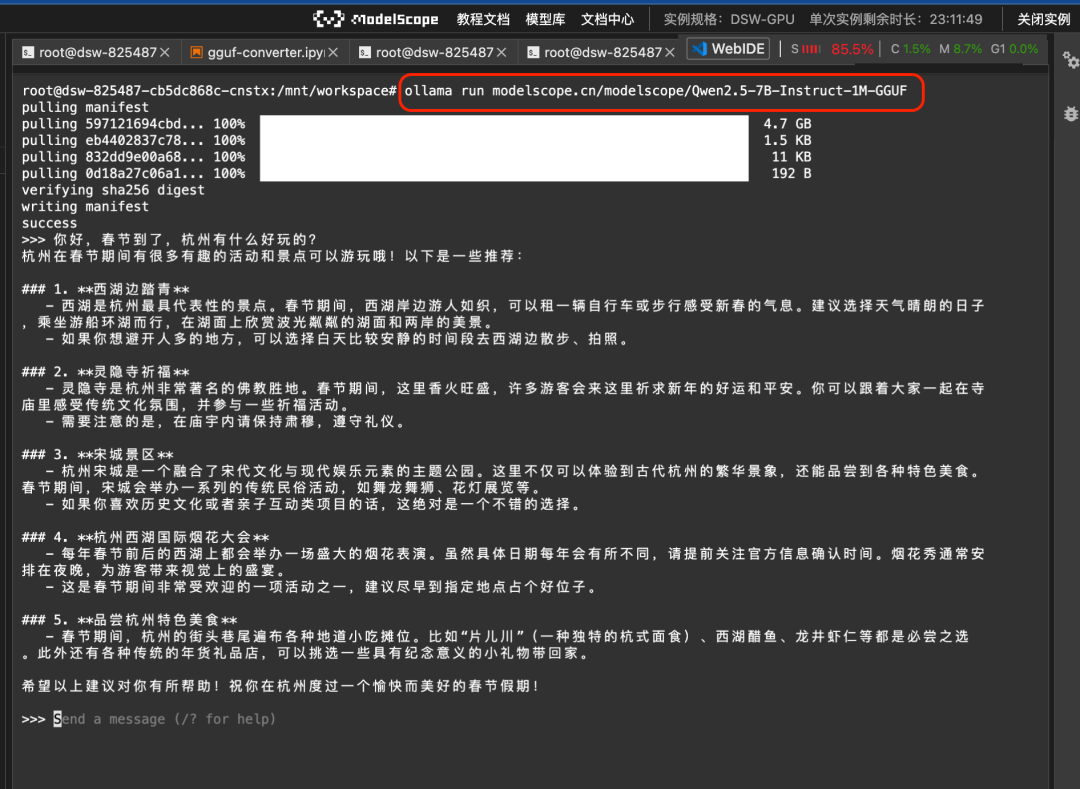
2. llamafileモデルが直接プルアップ
ラマファイル ビッグモデルと実行環境が1つの実行ファイルにカプセル化されたソリューションを提供します。Magic Rideコマンドラインとllamafileの統合により、Linux/Mac/Windowsのような異なるオペレーティングシステム環境で、ワンクリックでビッグモデルを実行することができます:
modelscope llamafile --model Qwen-Llamafile/Qwen2.5-7B-Instruct-1M-llamafileランの結果
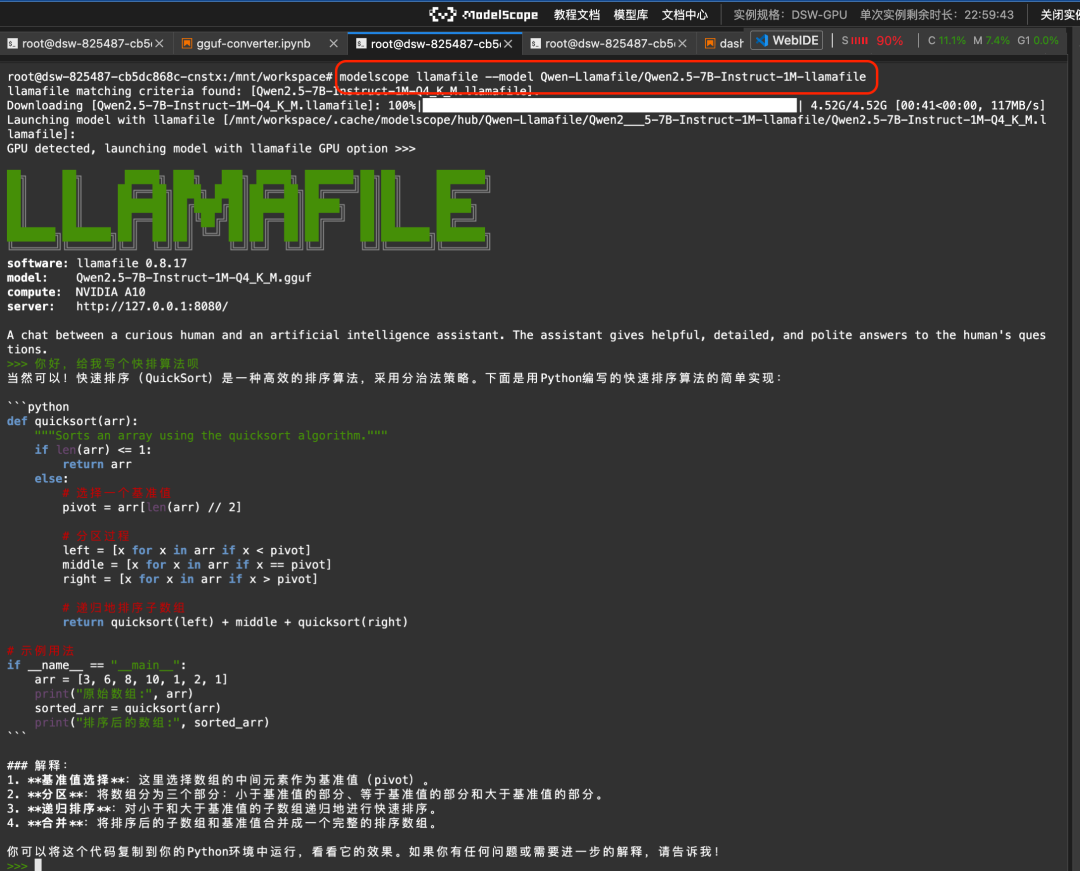
詳しいドキュメントは https://www.modelscope.cn/docs/models/advanced-usage/llamafile にある。
6.モデルの微調整
ここでは、ms-swiftを用いたQwen/Qwen2.5-7B-Instruct-1Mの微調整について述べる。
微調整を始める前に、環境が正しくインストールされていることを確認してください:
# 安装ms-swift git clone https://github.com/modelscope/ms-swift.git cd ms-swift pip install -e .
カスタムデータセットのための実行可能な微調整デモとスタイルを提供し、微調整スクリプトは以下の通りである:
cuda_visible_devices=0
swift sft \
--model Qwen/Qwen2.5-7B-Instruct-1M \
--train_type lora \
--dataset 'AI-ModelScope/alpaca-gpt4-data-zh#500' \
'AI-ModelScope/alpaca-gpt4-data-en#500' \
'swift/self-cognition#500' \
--torch_dtype bfloat16 \
--num_train_epochs 1 \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--learning_rate 1e-4 \
--lora_rank 8 \
--lora_alpha 32 \
--target_modules all-linear \
--gradient_accumulation_steps 16 \
--eval_steps 50 \
--save_steps 50 \
--save_total_limit 5 \
--logging_steps 5 \
--max_length 2048 \
--output_dir output \
--warmup_ratio 0.05 \
--dataloader_num_workers 4 \
--model_author swift \
--model_name swift-robot
トレーニングビデオのメモリ使用量:

カスタムデータセット形式: (`--dataset ` を使って直接指定する)
{"messages": [{"role": "user", "content": "<query>"}, {"role": "assistant", "content": "<response>"}, {"role": "user", "content": "<query2>"}, {"role": "assistant", "content": "<response2>"}]}
推論スクリプト:
CUDA_VISIBLE_DEVICES=0 \
swift infer \
--adapters output/vx-xxx/checkpoint-xxx \
--stream true \
--max_new_tokens 2048
モデルを ModelScope にプッシュします:
CUDA_VISIBLE_DEVICES=0 swift export \
--adapters output/vx-xxx/checkpoint-xxx \
--push_to_hub true \
--hub_model_id '' \
--hub_token ''
7.次はどうする?
Qwen2.5-1Mファミリーは、長いシーケンス処理タスクのための優れたオープンソースオプションをもたらしますが、研究チームは、長いコンテキストモデルにはまだ多くの改善の余地があることを十分に認識しています。私たちの目標は、短いタスクと長いタスクの両方に優れたモデルを構築し、実世界のアプリケーションシナリオで真に役立つようにすることです。この目的のため、チームはより効率的なトレーニング方法、モデル・アーキテクチャ、推論アプローチに取り組み、リソースに制約のある環境であっても、これらのモデルの効率的な展開と最適なパフォーマンスを可能にしている。 チームは、これらの取り組みがロングコンテキストモデルの新たな可能性を切り開き、その応用範囲を劇的に拡大し、この分野の限界を押し広げ続けることを確信しています!
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事


コメントはありません