
プロンプト上級者向けヒント:LLM出力の正確な制御と疑似コードによる実行ロジックの定義

ご存知のように、大規模な言語モデルにタスクを実行させる必要がある場合、その実行をガイドするプロンプトを入力する必要がある。簡単なタスクであれば、自然言語で明確に記述することができます。例えば、「以下を簡体字中国語に翻訳してください」、「以下の要約を生成してください」などです。
しかし、モデルに特定のJSON形式を生成させるような複雑なタスクや、タスクに複数の分岐があり、各分岐が複数のサブタスクを実行する必要があり、サブタスクが相互に関連しているような場合には、自然言語による記述では不十分である。
議題
この先を読む前に、2つの示唆に富む質問を試してみてほしい:
- 複数の長い文章があり、それぞれを80文字以内の短い文章に分割し、長い文章と短い文章の対応を明確に記述したJSON形式に出力する必要がある。
例えば、こうだ:
[
{
"long": "This is a long sentence that needs to be split into shorter sentences.",
"short": [
"This is a long sentence",
"that needs to be split",
"into shorter sentences."
]
},
{
"long": "Another long sentence that should be split into shorter sentences.",
"short": [
"Another long sentence",
"that should be split",
"into shorter sentences."
]
}
]
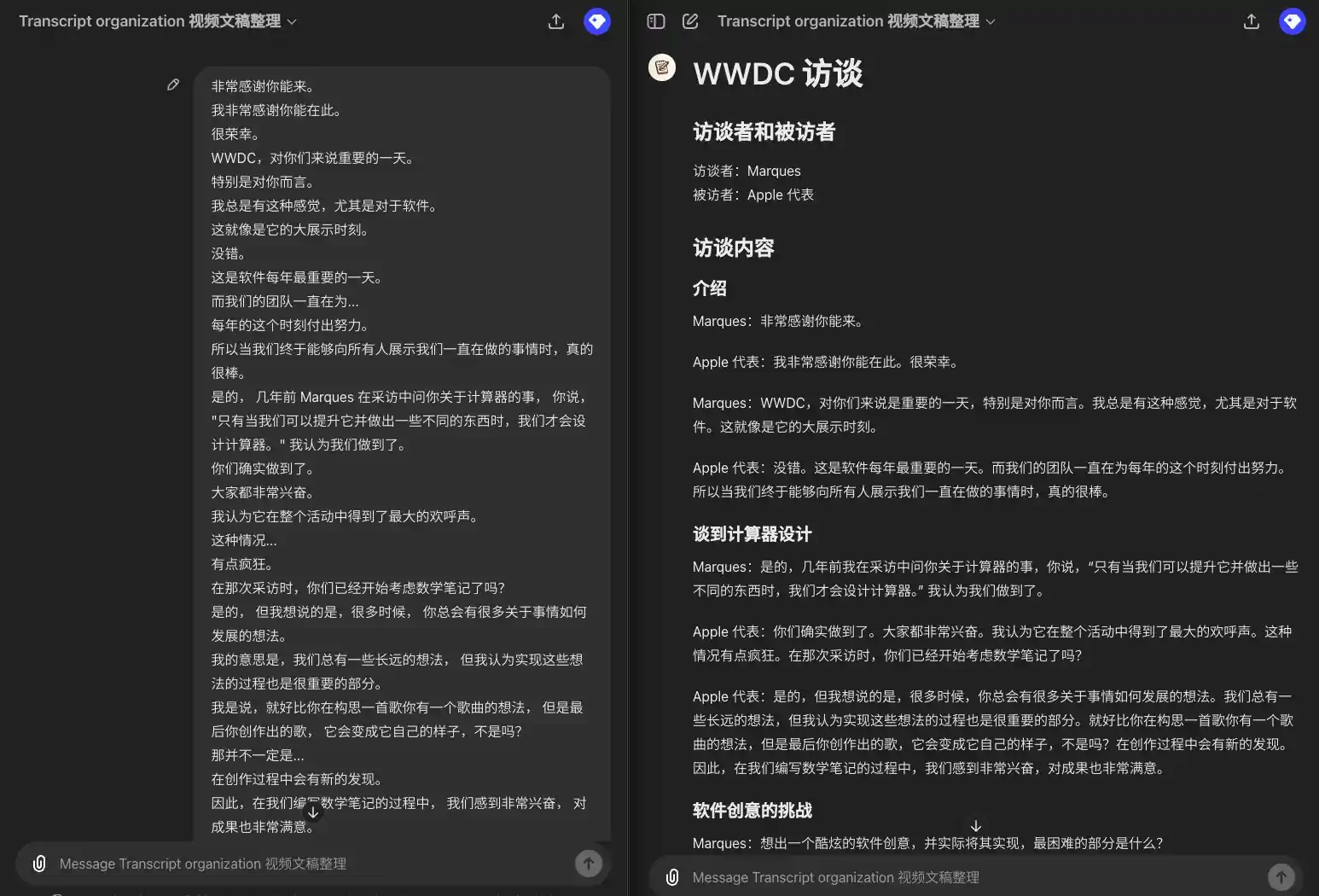
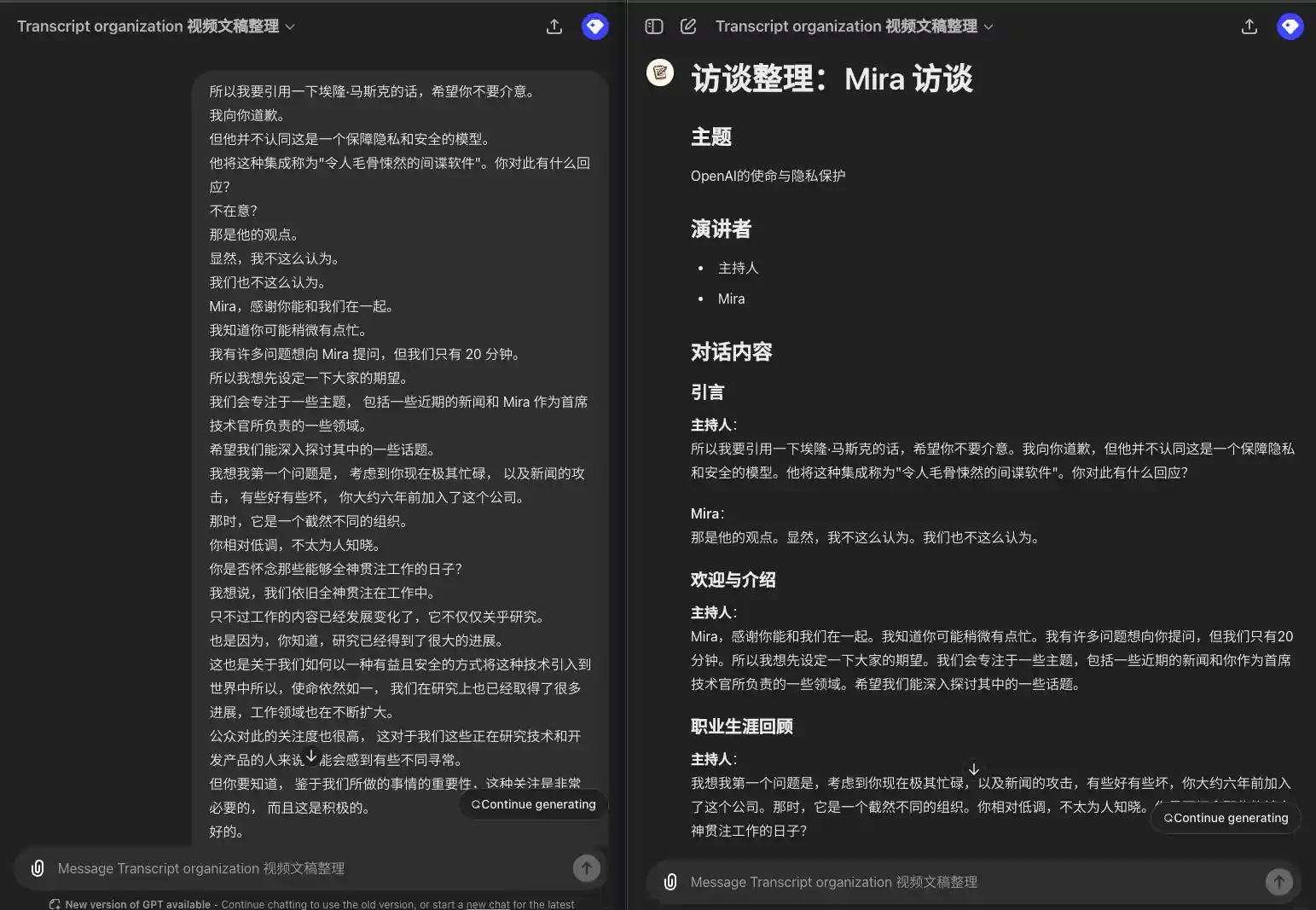
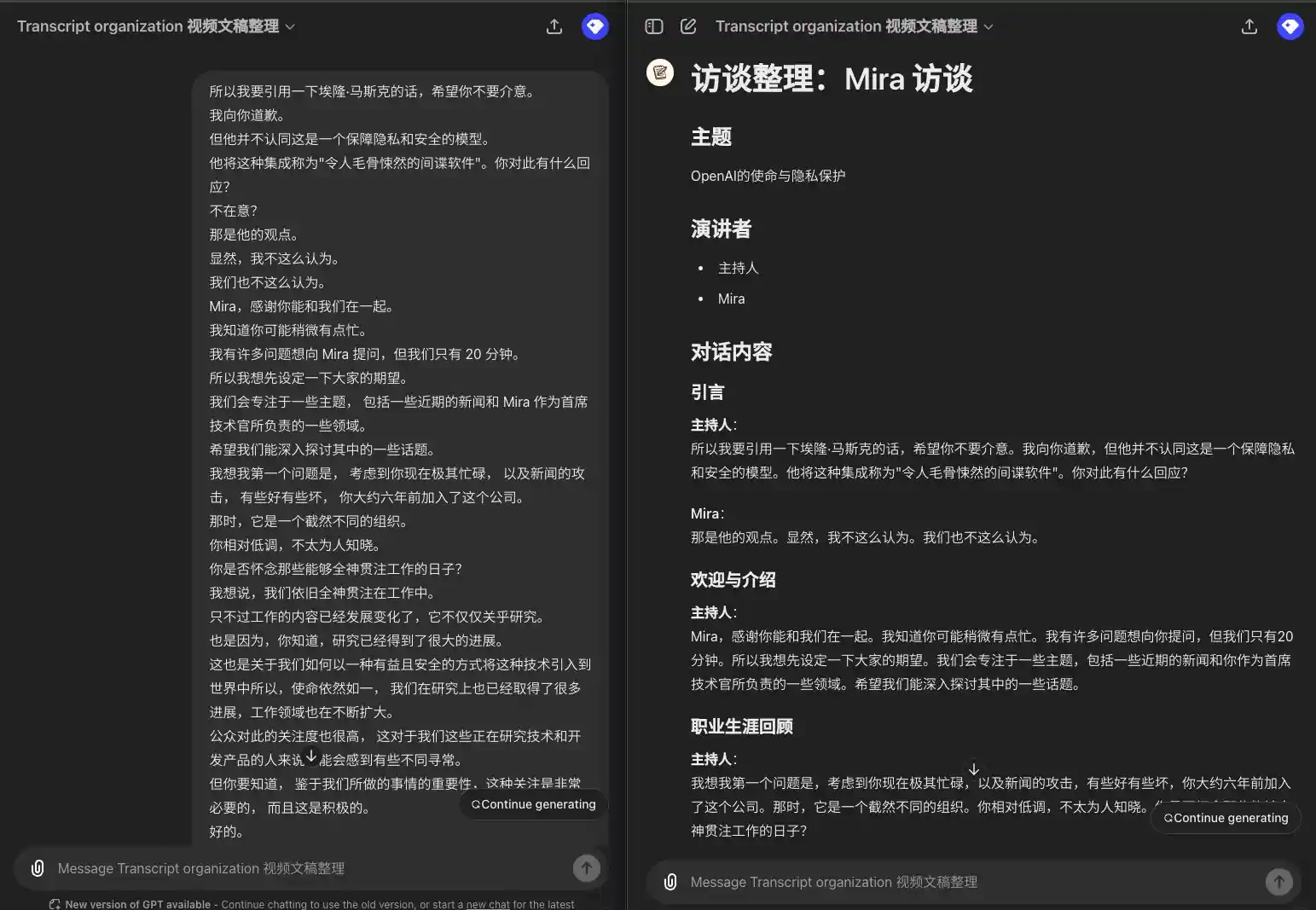
- 元の字幕付きテキストには、台詞の情報しかありませんが、そこから章、話者を抽出し、章と段落ごとに台詞をリストアップする必要があります。複数の話し手がいる場合は、同じ話し手が連続して話す場合ではなく、それぞれの台詞の前に話し手を付ける必要がある。(これは、私自身がビデオスクリプトを整理するために使用しているGPTです。 ビデオスクリプト照合GPT)
入力例:
所以我要引用一下埃隆·马斯克的话,希望你不要介意。 我向你道歉。 但他并不认同这是一个保障隐私和安全的模型。 他将这种集成称为"令人毛骨悚然的间谍软件"。你对此有什么回应? 不在意? 那是他的观点。 显然,我不这么认为。 我们也不这么认为。 Mira,感谢你能和我们在一起。 我知道你可能稍微有点忙。 我有许多问题想向 Mira 提问,但我们只有 20 分钟。 所以我想先设定一下大家的期望。 我们会专注于一些主题, 包括一些近期的新闻和 Mira 作为首席技术官所负责的一些领域。 希望我们能深入探讨其中的一些话题。 我想我第一个问题是, 考虑到你现在极其忙碌, 以及新闻的攻击, 有些好有些坏, 你大约六年前加入了这个公司。 那时,它是一个截然不同的组织。 你相对低调,不太为人知晓。 你是否怀念那些能够全神贯注工作的日子? 我想说,我们依旧全神贯注在工作中。 只不过工作的内容已经发展变化了,它不仅仅关乎研究。 也是因为,你知道,研究已经得到了很大的进展。 这也是关于我们如何以一种有益且安全的方式将这种技术引入到世界中所以,使命依然如一, 我们在研究上也已经取得了很多进展,工作领域也在不断扩大。 公众对此的关注度也很高, 这对于我们这些正在研究技术和开发产品的人来说可能会感到有些不同寻常。 但你要知道, 鉴于我们所做的事情的重要性,这种关注是非常必要的, 而且这是积极的。
出力例:
### 引言 **主持人**: 所以我要引用一下埃隆·马斯克的话,希望你不要介意。我向你道歉,但他并不认同这是一个保障隐私和安全的模型。他将这种集成称为"令人毛骨悚然的间谍软件"。你对此有什么回应? **Mira**: 那是他的观点。显然,我不这么认为。我们也不这么认为。 ### 欢迎与介绍 **主持人**: Mira,感谢你能和我们在一起。我知道你可能稍微有点忙。我有许多问题想向你提问,但我们只有 20 分钟。所以我想先设定一下大家的期望。我们会专注于一些主题,包括一些近期的新闻和你作为首席技术官所负责的一些领域。希望我们能深入探讨其中的一些话题。 ### 职业生涯回顾 **主持人**: 我想我第一个问题是,考虑到你现在极其忙碌,以及新闻的攻击,有些好有些坏,你大约六年前加入了这个公司。那时,它是一个截然不同的组织。你相对低调,不太为人知晓。你是否怀念那些能够全神贯注工作的日子? **Mira**: 我想说,我们依旧全神贯注在工作中。只不过工作的内容已经发展变化了,它不仅仅关乎研究。也是因为,研究已经得到了很大的进展。这也是关于我们如何以一种有益且安全的方式将这种技术引入到世界中。所以,使命依然如一,我们在研究上也已经取得了很多进展,工作领域也在不断扩大。公众对此的关注度也很高,这对于我们这些正在研究技术和开发产品的人来说可能会感到有些不同寻常。但你要知道,鉴于我们所做的事情的重要性,这种关注是非常必要的,而且这是积极的。
プロンプトの真髄
プロンプトのテクニックの書き方に関する記事をネットでたくさん読んだり、プロンプトのテンプレートをたくさん覚えたりしているかもしれないが、プロンプトの本質とは何だろうか?なぜプロンプトが必要なのか?
プロンプトは、基本的に自然言語で記述されたLLMへの制御命令であり、LLMがこちらの要求を理解し、必要に応じて入力を希望する出力に変えることを可能にする。
例えば、よく使われる数発技法は、LLMに例題を通してこちらの要求を理解させ、そのサンプルを参照してこちらの望む結果を出力させるというものです。例えば、CoT(Chain of Thought)とは、タスクを人為的に分解し、実行プロセスを限定することで、LLMが拡散しすぎたり、重要なステップをスキップしたりすることなく、こちらが指定したプロセスやステップに従うことができ、より良い結果を得ることができるようにすることである。
私たちが学生だった頃、先生が数学の定理について話すときには、その定理の意味を理解できるような例を示さなければならなかったのと同じように、私たちが実験をするときには、先生は実験の手順を教えてくれなければならなかった。たとえ私たちが実験の原理を理解していなくても、手順通りに実験を行えば、多かれ少なかれ同じ結果を得ることができる。
プロンプトの結果が最適でないことがあるのはなぜですか?
これは、LLMが我々の要求を正確に理解できないためであり、一方ではLLMの指示を理解し従う能力によって、他方では我々のプロンプトの説明の明確さと正確さによって制限される。
LLMの出力を正確に制御し、擬似コードを用いてその実行ロジックを定義する方法
プロンプトは基本的にLLMの制御命令であるため、従来の自然言語による記述に限定されることなく、LLMの出力を正確に制御し、その実行ロジックを定義するために擬似コードを使用してプロンプトを記述することができる。
疑似コードとは何か?
擬似コードの歴史は古く、自然言語とプログラミング言語の中間のような記述方法で、アルゴリズムを記述するための形式的な記述方法です。様々なアルゴリズムの本や論文では、擬似コードの記述をよく見かけますが、言語に詳しくなくても、擬似コードを通してアルゴリズムの実行の流れを理解することができます。
では、LLMは擬似コードをどの程度理解しているのだろうか?実際、LLMの擬似コードに対する理解度は非常に高く、LLMは大量の高品質なコードで訓練を受けており、擬似コードの意味を容易に理解することができます。
プロンプトの擬似コードの書き方は?
疑似コードは、プログラマーにとっては非常に馴染み深いものであり、プログラマーでなくても、いくつかの基本的なルールを覚えておくだけで、簡単な疑似コードを書くことができる。いくつかの例を挙げよう:
- 例えば、入力や中間結果を特定の記号で表す。
- 文字列、数値、配列など、データの型を定義するために使用される。
- 特定のサブタスクの実行ロジックを定義する関数
- ループや条件判定など、プログラムの実行プロセスを制御するために使われる制御フロー。
- if-else文は、条件Aが満たされればタスクAを実行し、そうでなければタスクBを実行する。
- 配列の各要素に対してタスクを実行するforループ。
- whileループでは、Aという条件が満たされると、Bというタスクが連続して実行される。
では、前の2つのリフレクション・クエスチョンを例にして、擬似コードのプロンプトを書いてみましょう。
特定のJSONフォーマットを出力する疑似コード
希望するJSONフォーマットは、TypeScriptの型定義に似た擬似コードで明確に記述できる:
Please split the sentences into short segments, no more than 1 line (less than 80 characters, ~10 English words) each.
Please keep each segment meaningful, e.g. split from punctuations, "and", "that", "where", "what", "when", "who", "which" or "or" etc if possible, but keep those punctuations or words for splitting.
Do not add or remove any words or punctuation marks.
Input is an array of strings.
Output should be a valid json array of objects, each object contains a sentence and its segments.
Array<{
sentence: string;
segments: string[]
}>
字幕スクリプトを擬似コードで整理する
字幕付きテキストを照合するタスクは比較的複雑である。 このタスクを達成するためのプログラムを書くことを想像すると、章を抽出し、話者を抽出し、最後に章と話者に従ってダイアログを照合するなど、多くのステップがあるかもしれない。擬似コードを使えば、このタスクをいくつかのサブタスクに分解することができる。具体的なコードを書く必要はなく、サブタスクの実行ロジックを明確に記述すればよい。そして、これらのサブタスクを段階的に実行し、最後に結果出力を統合する。
のような変数を使うことができる。 subjectそしてspeakersそしてchaptersそしてparagraphs その他
出力時には、Forループを使って章や段落を繰り返し、If-else文を使って発言者の名前を出力する必要があるかどうかを判断することもできる。
あなたの仕事は、読みやすくするためにビデオトランスクリプトを再編成し、複数人の対話のために話者を認識することです。 以下は、それを行う方法についての擬似コードです。以下はその擬似コードです。
def extract_subject(transcript):
# Find the subject in the transcript and return it as a string.
def extract_chapters(transcript):
# Find the chapters in the transcript and return them as a list of strings.
def extract_speakers(transcript):
# Find the speakers in the transcript and return them as a list of strings.
def find_paragraphs_and_speakers_in_chapter(chapter):
# Find the paragraphs and speakers in a chapter and return them as a list of tuples.
# Each tuple contains the speaker and their paragraphs.
def format_transcript(transcript):
# extract the subject, speakers, chapters and print them
subject = extract_subject(transcript)
print("Subject:", subject)
speakers = extract_speakers(transcript)
print("Speakers:", speakers)
chapters = extract_chapters(transcript)
print("Chapters:", chapters)
# format the transcript
formatted_transcript = f"# {subject}\n\n"
for chapter in chapters:
formatted_transcript += f"## {chapter}\n\n"
paragraphs_and_speakers = find_paragraphs_and_speakers_in_chapter(chapter)
for speaker, paragraphs in paragraphs_and_speakers:
# if there are multiple speakers, print the speaker's name before each paragraph
if speakers.size() > 1:
formatted_transcript += f"{speaker}:"
formatted_transcript += f"{speaker}:"
for paragraph in paragraphs:
formatted_transcript += f" {paragraph}\n\n"
formatted_transcript += "\n\n"
return formatted_transcript
print(format_transcript($user_input))
どうなるか見てみよう:
WWDCアクセス記録集
複数スピーカー、ショースピーカー
1 スピーカー、スピーカーなし
このプロンプトで生成したGPTを使うこともできます:転写組織GPT
擬似コードでChatGPTに複数の画像を同時に描画させる
私も最近、台湾のネットユーザーである尹祥志先生から、非常に興味深い言葉の使い方を学んだ。擬似コードでChatGPTに複数の画像を一度に描画させる.
さて、もしあなたが チャットGPT 一度に複数の画像を生成したい場合は、擬似コードを使って複数の画像を生成するタスクを複数のサブタスクに分割し、複数のサブタスクを一度に実行し、最終的に結果出力を統合することができます。
下面是一段画图的伪代码,请按照伪代码的逻辑,用DALL-E画图:
images_prompts = [
{
style: "Kawaii",
prompt: "Draw a cute dog",
aspectRatio: "Wide"
},
{
style: "Realistic",
prompt: "Draw a realistic dog",
aspectRatio: "Square"
}
]
images_prompts.forEach((image_prompt) =>{
print("Generating image with style: " + image_prompt.style + " and prompt: " + image_prompt.prompt + " and aspect ratio: " + image_prompt.aspectRatio)
image_generation(image_prompt.style, image_prompt.prompt, image_prompt.aspectRatio);
})

概要
上記の例から、自然言語による記述に限定するのではなく、擬似コードを使用することで、LLMの出力結果をより正確に制御し、その実行ロジックを定義できることがわかります。複雑なタスクや複数の分岐を持つタスクに遭遇し、各分岐が複数のサブタスクを実行する必要があり、サブタスクが互いに関連している場合、擬似コードを使用してプロンプトを記述する方がより明確で正確です。
プロンプトを書くとき、プロンプトは基本的に自然言語で記述されたLLMへの制御命令であり、LLMが私たちの望むことを理解し、必要に応じて入力を期待する出力に変えることを可能にするものであることを覚えておいてください。プロンプトを記述する形式としては、例えば数ショット、CoT、擬似コードなど、様々な形式に柔軟に対応することができます。
他の例もある:
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事




コメントはありません