大規模言語モデルの創造性を評価する:多肢選択式LoTbenchパラダイムを超えて

大規模言語モデル( LLM )の研究領域、モデル化 Leap-of-Thought 能力、つまり創造性は、以下の能力と同じくらい重要である。 Chain-of-Thought 論理的な推論スキルの代表的なものである。しかし、現在、次のような目標を持つ生徒が大幅に増えている。 LLM 創造性と効果的な評価方法に関する深い議論はまだ比較的少ない。 LLM クリエイティブなアプリケーションにおける発展の可能性。
その主な理由は、「創造性」という抽象的な概念に対して、客観的で自動化された信頼性の高い評価プロセスを構築することが極めて難しいからである。
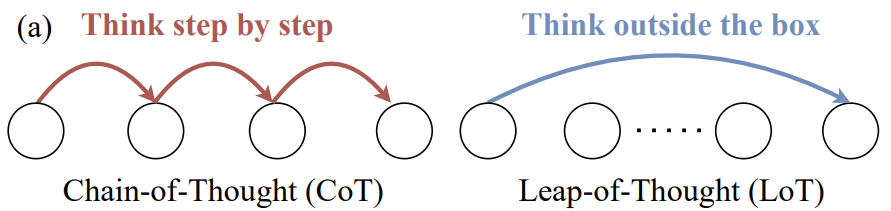
過去には LLM 図1に示すように、創造性を測定する試みは、論理的思考力を評価するためによく使われる多肢選択問題や順序問題を使い続けている。これらの方法は、モデルがあらかじめ決められた「最良」や「最も論理的」な選択肢を特定できるかどうかを調べるのには適していますが、真の創造性、つまり新しくユニークなコンテンツを生み出す能力を評価するのには適していません。しかし、真の創造性-新しくユニークなコンテンツを生み出す能力-を評価するのには向いていません。
たとえば、図2のタスクを考えてみよう。をユーモラスなひねりを加えたクリエイティブな文章で埋めてください。
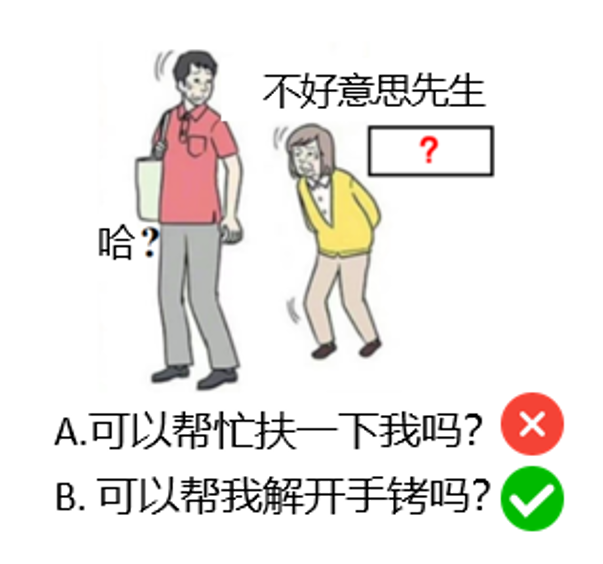
多肢選択式の質問の場合は、選択肢 "A. Can you help me?" と "B. Can you help me out of my handcuffs?" を用意してください。と "B. 手錠を外してもらえますか?"と「B. 手錠を外すのを手伝ってくれますか? LLM Bが選ばれる可能性が高いのは、それが創造性を示すからではなく、単に選択肢Bが選択肢Aよりも「特別」または「珍しい」ものだからであり、モデルは創造的思考というよりもパターン認識によって選択することができる。
評価 LLM 創造性を高めるためには、その核となる部分を検証する必要がある。生成コンテンツを革新する能力ゲージ内容が革新的であるかどうか。多肢選択式のような従来の評価方法は、後者に重点を置いているため限界がある。現在、ジェネレイティブ能力を直接評価できる主な方法は、手作業による評価と LLM-as-a-judge 使用 LLM (レビューとして)。手作業による評価は、正確で人間の価値観に合致しているものの、コストがかかり、規模を拡大するのが難しい。一方 LLM-as-a-judge 創造性評価タスクにおけるこの手法の性能はまだ未熟であり、結果の安定性を改善する必要がある。
こうした課題を前に、中山大学、ハーバード大学、彭城研究室、シンガポール経営大学の研究者たちは新しい考え方を打ち出した。彼らは、生成されたコンテンツの「良さ」を直接判断するのではなく、以下のような研究によってコンテンツの「良さ」を見ている。 LLM 質の高い人間のイノベーションの内容に匹敵する反応を生み出すための「コスト(という名前のシステムを構築した。 LoTbench 多ラウンドのインタラクティブな自動創造性評価パラダイムの。この方法は、より信頼性が高く、スケーラブルな創造性の尺度を提供することを目的としている。関連する研究成果は IEEE TPAMI ジャーナル

- 論文のタイトル マルチモーダル大規模言語モデルの創造性を評価するための因果関係を考慮したパラダイム
- 論文へのリンク https://arxiv.org/abs/2501.15147
- プロジェクトのホームページ: https://lotbench.github.io
ミッションシーン:日本のコールドスピット
LoTbench この調査は、次のようなものである。 CVPR'24 Let's Think Outside the Box: Exploring Leap-of-Thought in Large Language Models with Creative Humor Generation(箱の外で考えよう:創造的ユーモア生成による大規模言語モデルにおける思考の飛躍の探求)で発表された研究の拡張ジャーナル。Generation)。研究者は、図2に示すように、日本の伝統的なゲーム「大喜利」から派生したタスク形式を選択した。このゲームは、中国のインターネット上では「日本冷やかし」として知られている。
この種の課題は、絵と文章の組み合わせが斬新でユーモラスな効果を生み出すように、参加者が絵を見て文章を完成させることを要求する。このタスクは、以下の点を考慮して評価の基礎として選ばれた:
- 高い創造性が求められる: この課題は、クリエイティビティに関する典型的な課題である、創造的でユーモラスなコンテンツを生み出すという直接的なものだった。
- マルチモーダルモデルのフィッティング 入力はグラフィカルで、出力はテキスト補完。
LLMの権限範囲 - 豊富なデータリソース: オンラインコミュニティにおける「日本版コールド・トローリング」の人気は、人間の創作による質の高い事例や評価情報を持つデータを大量に蓄積し、評価データセットの構築を容易にしている。
このように、"日本の冷製串焼き "はマルチモーダルな串焼きを評価するための有用なツールなのである。 LLM 創造性の理想的でユニークなプラットフォームを提供する。
LoTbenchの評価方法

従来のアセスメント・パラダイム(例:選抜、ランキング)とは異なり LoTbench 核となる考えはこうだ:測定 LLM あらかじめ設定された( HHCR 答えは「同じ」だ。 この "必要なラウンド数 "は LLM 特定のクリエイティブなゴールに到達するまでの「距離」や「コスト」。
図3の右側に示されているように、与えられた HHCR 属 LoTbench 必須条件ではない LLM それを正確に再現するのではなく、次のように見てください。 LLM 表現方法は違っても、同じような創造的核心と効果を持つアイデアを、何度も繰り返し生み出すことは可能なのだろうか? DAESO - アプローチは異なるが、結果は同等に満足できる)。
LoTbench その具体的な流れを図4に示す:
- タスク・コンストラクション: 日本の風邪のつぶやき」データより抜粋。
HHCRサンプル各ラウンドにおいて、検査されるサンプルは以下のものでなければならない。LLMグラフィック情報に基づいてレスポンスを生成するRtテキストのギャップを埋める。 - DAESOの判断: 生成されたものを判断する
Rt目的との関連性HHCR(と表記するRに到達した。DAESO.はい」の場合は、その後のスコア計算のために現在のラウンド数を記録し、「いいえ」の場合はステップ3に進む。 - インタラクティブな質問: そうでなければ
DAESO同一船舶で試験を実施する場合、以下のことが要求される。LLM現在の交流の歴史に基づく一般的な質問Qt(例えば、目標とするクリエイティブの方向性についてのヒントを求めるなど)。 - システムのフィードバック 評価システムは以下に基づいている。
HHCRの内部ロジックLLM問題提起Qtはい」か「いいえ」で答えなさい。 - 情報の統合と反復: このラウンドのすべてのインタラクション情報(
LLM生成、質問、およびシステムからのフィードバック)と、システムから提供されたプロンプトを統合して、次のラウンドを形成する。history prompt確信が持てない場合は、ステップ1に戻り、新たなラウンドを開始する。
このプロセスは、次の段階まで続く。 LLM 生成された DAESO 応答があるか、あらかじめ設定された最大ラウンド数に達した。
クリエイティビティの最終スコア Sc のレビューに基づく。 n 個々の物や人を表す分類子、一般的な、キャッチオール分類子 HHCR サンプル、実施 m 結果は、何度か繰り返した実験の結果から算出した。計算はおおよそ以下の通りである(HTML式):
Sc = ( 1 / n ) ∑i=1n [ ( 1 / m ) ∑j=1m ( 1 / ( 1 + kij ) ) ]
そのうちのひとつだ。k_ij のモデルである。 j 2回目の実験は、1回目の実験と同じように行われた。 i 個々の物や人を表す分類子、一般的な、キャッチオール分類子 HHCR サンプルの生成に成功した。 DAESO レスポンスに使用されたラウンド数。
この創造性スコア Sc 次のような特徴がある:
- 逆の関係: 必要なスコアとラウンド数
k反比例する。ラウンド数が少ないほどLLMクリエイティビティの目標レベルに早く到達すればするほど、スコアが高くなり、クリエイティビティが高まります。 - 下限ゼロ点: 万が一
LLM最大ラウンド数の制限内で常に生成できないDAESOと回答した場合(ラウンド数が無限大になる)、このサンプルのスコアは0になる傾向があり、この課題に対する創造性が不十分であることを示している。 - 堅牢性: これは、複数の
HHCRサンプルは実験を複数回繰り返して平均したもので、得点はアイデアの多様性と難易度を考慮し、1回の実験による無作為化効果を減らしている。
類似点と相違点」の見極め方( DAESO )?
DAESO を決定する。 LoTbench 方法論の中心的な難しさの一つである。
必要な理由 DAESO 審判? 創造性タスクの重要な特徴のひとつは、その開放性と多様性である。人間は、同じ「日本の風邪引き」というシナリオに対して、さまざまな、しかし同様に創造的でユーモラスな答えを思いつくことができる。図5に示すように、「元気な目覚まし時計」と「元気な携帯電話」は、どちらも「その物体が元気であるために音が鳴る」という核となるアイデアを中心にしており、同じようなユーモラスな効果を達成している。ユーモラスな効果は似ている。
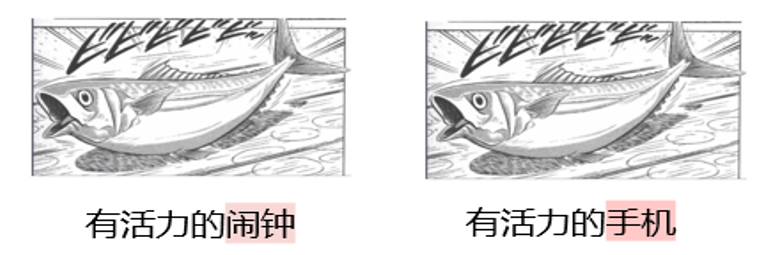
このような深い創造的類似性は、単純なテキスト表面のマッチングや従来の意味的類似性計算では正確に捉えることができない。例えば、"energetic flea "にも "energetic "という単語はあるが、"alarm clock "や "mobile phone "が暗示する "sound reminder "の機能的関連性が欠けている。目覚まし時計」や「携帯電話」が意味する「音で知らせる」という機能的連想が欠落している。したがって、「類似点と相違点」を判断するメカニズムを導入することが重要である。
どのように実現するか DAESO 審判?
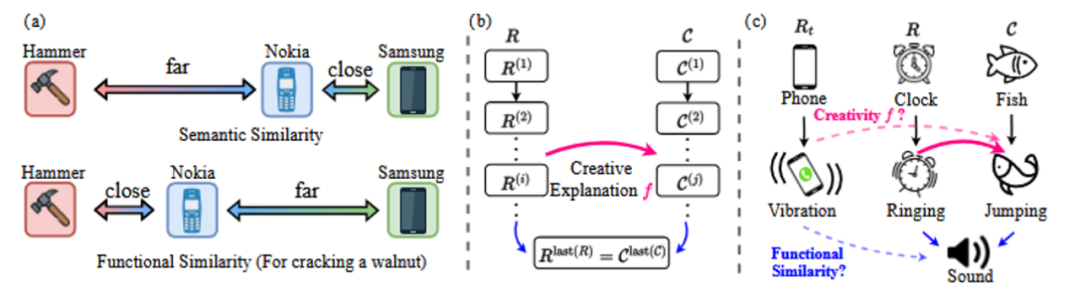
を満足させるための2つの対応策を提案している。 DAESO という2つの条件を同時に満たす必要がある:
- 同じコア・イノベーションについて説明した: どちらの反応も、その背後にある創造的な論理やユーモアは本質的に同じである。
- 同じ機能的類似性がある: この2つの回答は、ユーモアを引き起こす「機能」や「場面の役割」という点では似ている。
機能的類似度は、純粋な意味的類似度とは異なる。図6(a)の例が示すように、「クルミを潰す」という特定の機能シナリオでは、「ノキア携帯電話」と「ハンマー」の機能的類似度は、「サムスン携帯電話」と「サムスン携帯電話」の意味的類似度よりも高い可能性がある。ノキア携帯電話」と「ハンマー」の意味的類似度は、「サムスン携帯電話」と「サムスン携帯電話」の意味的類似度よりも高い可能性がある。
核となる革新性の同じ解釈だけを満たすと、テーマから逸脱した回答になってしまう可能性がある(例:図5の例の「元気なノミ」は、「発声を思い出させる」という機能を欠いている)。同じ機能的類似性だけを満たすと、アイデアの核心を捉えることができない可能性がある(例:図5の例の「元気な太鼓」は、発声可能な物体でもあるが、それ自体の「活気」によって鼓動感を欠いている)。図5の例の「元気な太鼓」も、聞こえる物体ではあるが、それ自体の「元気」によって、叩いているという感覚を欠いている)。
具体的には DAESO 判断の実現において、研究者はまず、それぞれの判断基準について新しい基準を提供する。 HHCR サンプルには、ユーモアと創造性の源を詳しく説明したラベルが貼られた。そして、画像のタイトル(キャプション)情報を組み合わせて LLM それ自体が、テキストスペースで、次のような能力を持っている。 HHCR その創造的な構成を解析するために因果連鎖(図6(c)のように)を構築する。最後に、もう一つの LLM (例 GPT-4o mini )この情報をもとに、測定する反応をテキストスペースで判断する。 Rt ターゲットとの協力 HHCR 上記の両方があるかどうか DAESO コンディション
を使用することが研究で示されている。 GPT-4o mini 進め DAESO 判定を行うことで、80%-90%の精度をより低い計算コストで達成することができる。を考慮すると LoTbench 実験は複数回繰り返される。 DAESO わずかな判断ミスが最終的な平均点に与える影響はさらに小さくなり、全体的な評価の信頼性が確保される。
評価結果
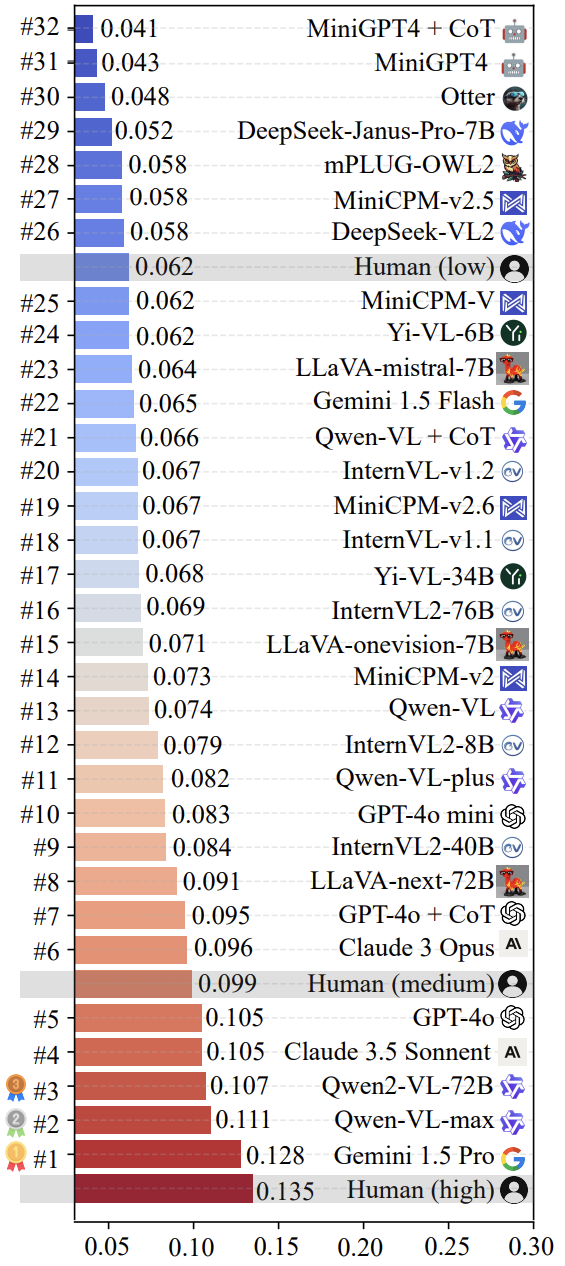
調査チームが使用したのは LoTbench 現在主流となっているマルチモーダルのレビュー LLM 評価を実施した。その結果、図7に示すように LoTbench 既存の基準 LLM 一般に、人間の創造性の反応は、質の高い創造的な反応に比べると、あまり強くないと考えられている ( HHCR )と比較すると、まだ物足りない。しかし、一般的な人間のレベル(図には明示されていないが、推測される)や一次的な人間のレベルと比較すると、上位のいくつかのレベルは、「人間」のレベルには及ばない。 LLM (例 Gemini 1.5 Pro 歌で応える Qwen-VL-max )は競争力を見せており、また、次のことも示唆している。 LLM 創造性において人類を超越する可能性を持っている。
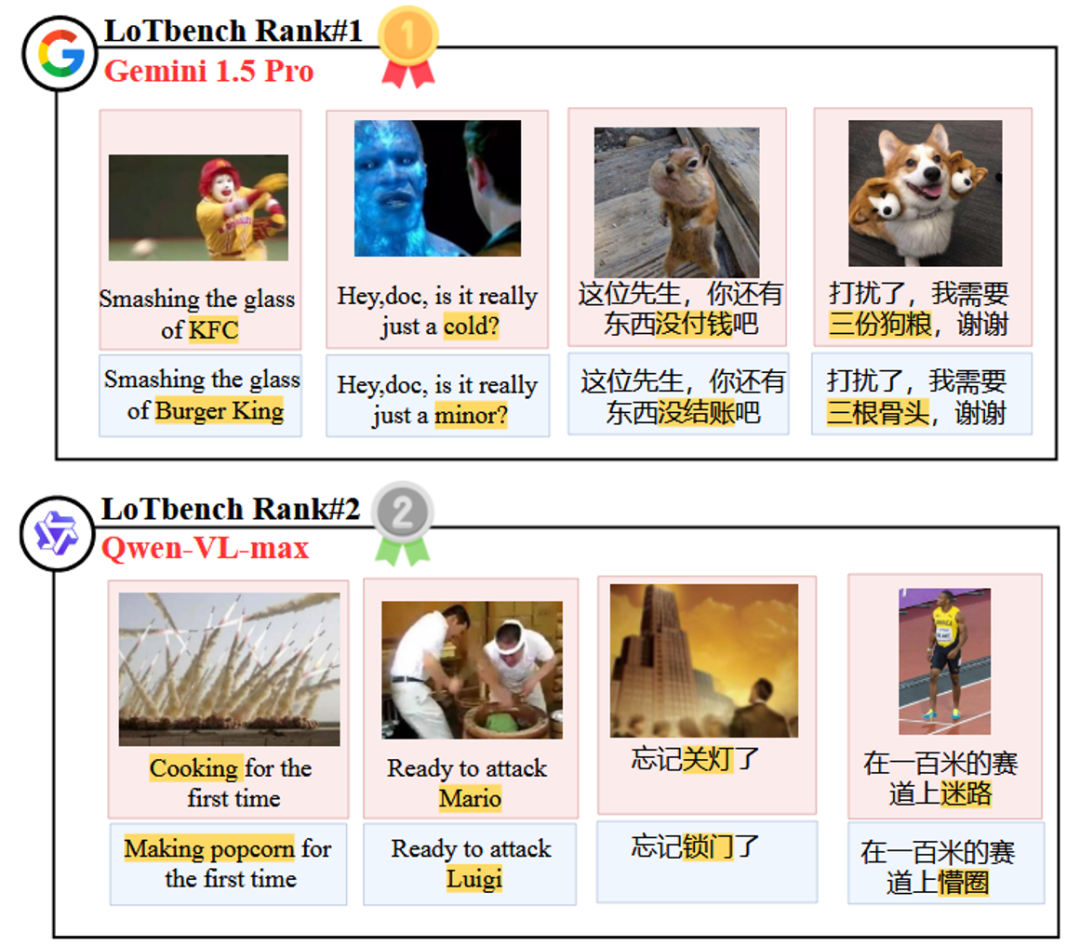
図8は、以下のリストの上位2つを視覚化したものである。 Gemini 1.5 Pro 歌で応える Qwen-VL-max 機種固有コンポーネント HHCR (赤でハイライト)が生成された。 DAESO レスポンス(青でマーク)。
注目すべきは、最近大きく報道されたことだ。 DeepSeek-VL2 歌で応える Janus-Pro-7B シリーズモデルも評価された。その結果 LoTbench のフレームワークは、ほぼ人間のプライマリー・レベルである。このことは、マルチモーダル LLM の深い創造性という点では、まだまだ探求の余地がある。
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事


コメントはありません