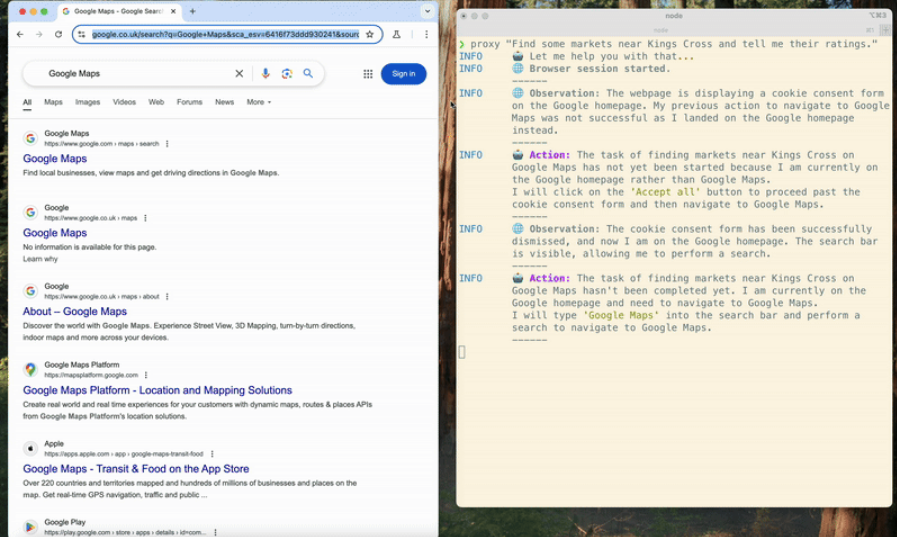
PDF-Extract-Kit:オープンソースツールのPDFコンテンツの複雑な構造を抽出する

はじめに
PDF-Extract-Kitは、OpenDataLabチームによって開発されたオープンソースプロジェクトで、複雑で多様なPDF文書から高品質なコンテンツを効率的に抽出することに重点を置いています。高度な文書解析技術を統合し、レイアウト検出、数式認識、表抽出、OCRなどの機能をサポートし、学術論文、研究報告、金融文書などのシナリオに適用できます。PDF-Extract-Kitは、モジュール設計を採用しており、ユーザーのニーズに応じて柔軟に構成することができ、カスタマイズされた文書処理アプリケーションを簡単に構築することができます。 PDF-Extract-Kitは、ユーザーが最適なモデルを選択するのに役立つ包括的な評価ベンチマークを提供し、常に更新され、最適化されながら、最近の高速化DocLayout-YOLOやStructTableの追加など。-InternVL2-1Bの追加など、常に最適化されています。開発者と研究者の両方が、これを通じて効率的な文書コンテンツ抽出を実現することができます。

機能一覧
- レイアウト検出DocLayout-YOLOのような効率的なモデルをサポートし、見出し、段落、画像、表などの領域を含むPDF内のページレイアウトを認識します。
- 数式認識UniMERNetのような先進的な技術を利用して、文書から数式を抽出・解析し、LaTeX形式に変換します。
- フォーム抽出複雑な表コンテンツの認識と抽出をサポートし、LaTeX、HTML、Markdown形式で出力します。
- OCR処理PaddleOCRなどの技術により、スキャンした文書や画像から編集可能なテキストに変換します。
- モジュラー構成異なるモデルを組み合わせてアプリケーションを素早く構築できる柔軟なプロファイルを提供します。
- 内容評価様々な内蔵PDF解析ベンチマークにより、様々なモデルの有効性を評価することができます。
- 画像とテキストの抽出PDF から画像を抽出し、そのテキストコンテンツを認識するためのサポート。
ヘルプの使用
設置プロセス
PDF-Extract-Kitは複数のオペレーティングシステム(Ubuntu、Windows、macOSなど)に対応しています。以下は詳細なインストール手順です(例:Ubuntu 20.04):
1.環境準備
- Python 3.10がシステムにインストールされていることを確認してください:
sudo apt update sudo apt install python3.10 python3.10-dev python3-pip
- 仮想環境を作成し、起動する:
conda create -n pdf-extract-kit python=3.10 conda activate pdf-extract-kit
2.依存関係のインストール
- コードリポジトリをクローンする:
git clone https://github.com/opendatalab/PDF-Extract-Kit.git cd PDF-Extract-Kit - コアの依存関係をインストールする(GPUがない場合に利用可能)
requirements-cpu.txt):pip install -r requirements.txt銘記するもし
doclayout-yoloインストールに失敗しました:pip3 install doclayout-yolo==0.0.2 --extra-index-url=https://pypi.org/simple
3.モデルの重みをダウンロードする
- モデルファイルをダウンロードするには、公式チュートリアルを参照してください(完全または部分的なダウンロードに対応しています):
- Pythonスクリプトによる自動ダウンロード:
python scripts/download_models_hf.py - またはHugging Faceから手動でダウンロードする:
git lfs install git clone https://huggingface.co/opendatalab/PDF-Extract-Kit-1.0
- Pythonスクリプトによる自動ダウンロード:
- ダウンロードが完了したら、モデルファイルをプロジェクトディレクトリの指定されたパスに配置します。
configs/model_configs.yaml).
4.インストールの検証
- サンプルスクリプトを実行して、環境が動作していることをテストします:
python pdf_extract.py --pdf assets/examples/example.pdf出力は
outputsフォルダー
機能 操作の流れ
レイアウト検出
- PDFファイルの準備処理す る PDF をプ ロ ジ ェ ク ト デ ィ レ ク ト リ に配置 し ます (た と えば
assets/examples/). - 走行レイアウト検査::
- 修正
configs/layout_detection.yamlの入力経路はpdf_path: "assets/examples/example.pdf" output_dir: "outputs/layout_detection" - コマンドを実行する:
python scripts/layout_detection.py --config=configs/layout_detection.yaml
- 修正
- 結果を見るで
outputs/layout_detectionフォルダに保存され、レイアウト領域がラベル付けされた画像とJSONファイルが生成される。
数式認識
- 処方の抽出を実行する::
- デフォルトの設定を使用する:
python pdf_extract.py --pdf your_file.pdf --render --renderパラメータは、数式を簡単に確認できるように画像として表示します。
- デフォルトの設定を使用する:
- 出力を見る数式はLaTeX形式の出力JSONに保存され、学術論文やその他の処理に直接使用することができます。
フォーム抽出
- 執行フォームの識別::
- ダウンロードされていることを確認する
StructTable-InternVL2-1Bモデル - 完全な抽出を実行する:
python pdf_extract.py --pdf your_file.pdf
- ダウンロードされていることを確認する
- 出力フォーマットの選択::
- 設定ファイルの修正
configs/model_configs.yaml設定table_formatというのもlatexそしてhtmlもしかしたらmarkdown.
- 設定ファイルの修正
- 結果表示フォームの内容は、指定されたフォーマットで出力ディレクトリに保存される。
OCR処理
- スキャンしたPDFの処理::
- グラフィカルなPDFの場合は、OCRが有効になっていることを確認してください:
python pdf_extract.py --pdf scan_file.pdf --vis --visパラメータは、認識されたテキストの領域に注釈を付けて、視覚化結果を生成する。
- グラフィカルなPDFの場合は、OCRが有効になっていることを確認してください:
- 出力チェックテキスト内容は編集可能な形式で保存され、画像とテキストの認識結果を一目で見ることができます。
注目の機能操作
モジュラー構成
- コンパイラ
configs/model_configs.yamlパラメータを調整する:img_size画像解像度conf_thres信頼閾値。deviceセレクションcuda(GPU)またはcpu.
- 例
model_args: img_size: 1024 conf_thres: 0.5 device: "cuda"
高性能の最適化
- 大容量デバイス(ビデオメモリ16GB以上)では、バッチ処理を有効にすることができます:
python pdf_extract.py --pdf your_file.pdf --batch-size 128 - バッチ処理に適した50%以上の解析速度向上。
多言語サポート
- セットアップ
langというのもautoOCRモデルは、文書の言語を自動的に認識し、適切なOCRモデルを選択するために使用されます:ocr_args: lang: "auto"
ほら
- ハードウェア要件GPU(NVIDIAカードなど)は処理速度を大幅に向上させることができるため、8GB以上のビデオメモリを搭載することを推奨します。
- 一般的な問題::
- というプロンプトが表示されたら
cv2ランニングpip install opencv-python. - モデルのダウンロードが不完全な場合は、ネットワークを確認するか、ダウンロード方法を変更してください。
- というプロンプトが表示されたら
- 地域支援質問がある場合は、GitHubのDiscussionsやIssuesボードで質問してください。
上記のステップを通じて、ユーザーは簡単にPDF-Extract-Kitを使い始めることができ、複雑なPDFコンテンツの抽出を効率的に完了することができます。
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事


コメントはありません