OpenAIリリース:AI推論モデルのアプリケーションとベストプラクティス

業界のリーダーであるopenAIは、主に2種類のモデルファミリーを提供している:推論モデル (推論モデル)と GPTモデル (GPTモデル)がある。前者は、以下のようなoシリーズに代表されるモデルである。 o1 歌で応える o3-mini後者は、GPTファミリーのモデルで知られている。 GPT-4o.この2種類のモデルの違いと、それぞれが得意とする応用シナリオを理解することは、AIの可能性を十分に活用する上で非常に重要である。
この記事では、それについて掘り下げていく:
- OpenAIの推論モデルとGPTモデルの主な違い。
- OpenAIの推論モデルの使用を優先するタイミング。
- 最適なパフォーマンスを発揮するために、推論モデルを効果的にキューイングする方法。
先日、マイクロソフトのエンジニアが OpenAI O1およびO3-mini推論モデルのためのヒントエンジニアリング 両者のアプリケーションの違いを比較することは可能である。
推論モデルとGPTモデル:戦略家と実行者
OpenAIのoシリーズの推論モデルは、お馴染みのGPTモデルとは対照的に、異なるタイプのタスクにおいて独自の強みを発揮し、異なるキューイング戦略を必要とする。 この2つのタイプのモデルは、単純に優れているとか劣っているとかではなく、能力の焦点が異なることを理解することが重要です。これは、深い推論を必要とする複雑化するアプリケーションのニーズに対応するために、モデルの能力の境界を拡大するOpenAIの継続的な努力を反映しています。
OpenAIは、社内でPlannersというコードネームで呼ばれているoシリーズのモデルを、より長く、より深く考えるように特別に訓練し、戦略策定、複雑な問題計画、大量のあいまいな情報に基づく意思決定などの分野で優れた能力を発揮できるようにした。 これらのモデルが高い精度と正確さでタスクをこなす能力は、数学、科学、工学、金融サービス、法律サービスなどの専門分野など、従来は人間の専門家に頼っていた分野に理想的です。
一方、OpenAIのGPTモデル(内部的なコードネームは "Workhorses")は、より低レイテンシーでコスト効率が高く、タスクを直接実行するために設計されています。 特に、絶対的な正確さよりもスピードとコスト効率が重要なシナリオでは、Oシリーズモデルを使用して問題解決のためのマクロ戦略を策定し、GPTモデルの助けを借りて特定のサブタスクを効率的に実行します。 この役割分担は、プランニングと実行を分離したAIモデル設計思想の成熟度を反映している。
正しいモデルの選び方 ニーズを理解する
モデルを選択する際に重要なのは、アプリケーションシナリオの中核となる要件を定義することです:
- スピードとコスト。 スピードとコスト効率を優先するのであれば、通常、GPTモデルの方がより高速で経済的な選択となる。
- 明確に定義されたタスク。 目標が明確で、タスクの境界線が明確に定義されているアプリケーションでは、GPTモデルは実行タスクに優れている。
- 正確性と信頼性。 極めて高い精度と信頼性が要求されるアプリケーションには、信頼性の高いoシリーズが最適です。
- 複雑な問題解決。 高い曖昧さと複雑さに直面しても、oシリーズは効果的に対処することができる。
そのため、スピードとコストを第一に考慮し、ユースケースが主に単純で明確に定義されたタスクである場合は、OpenAIのGPTモデルが理想的です。 しかし、精度と信頼性が重要で、複雑で多段階の問題を解決するのであれば、OpenAIのoシリーズのモデルの方が適しているかもしれません。
Oモデルファミリーはエージェントのプランニングと意思決定を担当する「プランナー」として機能し、GPTモデルファミリーは特定のタスクの実行を担当する「エクゼキューター」として機能します。 この組み合わせ戦略は、両方のタイプのモデルの長所をフルに活用します。

例えば、OpenAIのGPT-4oとGPT-4o miniモデルは、カスタマーサービスシナリオで使用することができます。顧客情報は、まず注文の詳細を分類し、注文の問題点と返品ポリシーを特定するために使用され、これらのデータポイントはo3-miniモデルに供給されます。
推論モデルの応用シナリオ:複雑さと曖昧さを得意とする
OpenAIは、お客様とのコラボレーションや社内での観察を通じて、推論モデルの成功する典型的な適用パターンをいくつか開発しました。 以下に挙げる適用シナリオは、全てを網羅するものではなく、OpenAIのo-seriesモデルをより良く評価し、テストするための実用的なガイドです。
1.曖昧なタスクのナビゲート:断片的な情報から意図を理解する
推論モデルは、情報が不完全であったり散在していたりするタスクを処理するのが特に得意である。 限られた情報しかない場合でも、推論モデルはユーザーの真の意図を効果的に理解し、指示の曖昧さを適切に処理することができる。 推論モデルは通常、無分別な推測をしたり、自ら情報のギャップを埋めようとしたりせず、むしろタスクの要求が正確に理解されるよう、積極的に明確な質問を投げかけることは特筆に値する。 これは、不確実性や複雑なタスクに対処する際の推論モデルの利点を示す良い例である。
OpenAIのマルチエージェントプラットフォームであるMatrixは、複雑な文書を効率的に処理し、詳細で構造化された有益な回答を生成することができます。 例えば、o1は、支払能力に制限のあるクレジット契約で利用可能な金額を、簡単なプロンプトで簡単に特定することができます。 これほどのパフォーマンスを達成したモデルは他にありません。 52%の集中的なクレジット契約複合キューイングテストにおいて、o1は他のモデルと比較してより有意な結果を達成しました。"
-法律・金融分野向けAIナレッジプラットフォーム企業Hebbia社
2.情報検索:干し草の山から針を見つける、場所を特定する
大量の非構造化情報に直面したとき、推論モデルは強力な情報理解力を発揮し、質問に最も関連する情報を正確に抽出することができる。 このことは、情報検索や重要情報フィルタリングにおいて、特に大規模なデータセットを扱う場合に、推論モデルが優れた性能を発揮することを強調している。
AI財務インテリジェンス・プラットフォームであるエンデックスは、「企業買収を深く分析するために、o1モデルは、契約に悪影響を及ぼす可能性のある条項を見つける目的で、契約書やリース契約を含む数十の企業文書をレビューするために使用されました。 このモデルには、重要な条項にフラグを立てるという任務が課せられていた。 その際、o1は脚注にある重要な「支配権の変更」条項を鋭く特定した。その条項とは、会社が売却されることになった場合、7500万ドルの融資を直ちに返済しなければならないというものであった。o1の細部へのこだわりも、重要な条項の特定には欠かせなかった。 o1の細部への高い注意力により、OpenAIのAIエージェントは、ミッションクリティカルな情報を正確に特定することで、金融専門家の業務を効果的にサポートすることができます。"
--AIファイナンシャル・インテリジェンス・プラットフォーム、エンデックス
3.関係性の発見とニュアンスの特定:データの価値をより深く掘り下げる
OpenAIは、推論モデルが、法的契約書、財務諸表、保険金請求書など、数百ページにも及ぶ高密度で構造化されていない文書の分析に特に優れていることを発見した。 これらのモデルは、複雑な文書から情報を抽出し、異なる文書間の関連付けを行い、データに暗黙的に含まれる事実に基づいて推論的な決定を下すことに効果的である。 このことは、推論モデルが複雑な文書の処理や深い情報のマイニングにおいて大きな優位性を持つことを示している。
税務調査のためのAIプラットフォームであるBlue Jは、「税務調査では、最終的に説得力のある結論を形成するために、複数の文書から情報を統合する必要があることがよくあります。 GPT-4oモデルをo1モデルに置き換えた後、OpenAIは、o1が文書間の相互作用に関する推論に優れており、単一の文書では明らかにならない論理的な結論を導き出せることを発見しました。 その結果、o1モデルに切り替えることで、OpenAIはエンドツーエンドのパフォーマンスが4倍向上しました。"
--税制調査AIプラットフォームBlue J
推論モデルは、ニュアンスの異なるポリシーやルールを理解し、それを特定のタスクに適用して合理的な結論を導き出すことに長けている。
財務分析の分野では、アナリストはしばしば株主の権利に関連する複雑な状況を扱う必要があり、関連する法的複雑性を深く理解する必要があります。 OpenAIは、さまざまなベンダーの約10のモデルを、困難ではあるが共通の質問を使ってテストしました:資金調達の行動は、既存株主にどのような影響を与えるのか? この質問には、資金調達前後の企業評価に関する推論と、複雑な循環希薄化への対処が必要です。 OpenAIは、o1とo3-miniモデルがこの問題を完璧に解決することを発見した! これらのモデルは、10万ドルの株主に対する資金調達行動の影響を詳細に示す明確な計算表まで生成しました。"
--投資管理AIプラットフォームBlueFlame AI
4.多段階の代理店計画:運営のための戦略計画、成功のための戦略
推論モデルは、エージェントのプランニングと戦略策定において重要な役割を果たす。 OpenAIは、推論モデルが "プランナー "として位置づけられた場合、複雑な問題に対する詳細な複数ステップの解決策を生成できることを確認しています。 その後、システムは、待ち時間と知能に対する様々な要求に基づいて、各ステップを実行するために最も適切なGPTモデル(「実行者」)を選択し、割り当てることができます。 これは、推論モデルが戦略立案のための「頭脳」として、GPTモデルが実行のための「手足」として機能し、モデルを組み合わせて使用することの利点をさらに示している。
製薬業界向けのAIナレッジ・プラットフォームであるArgon AIは、「OpenAIは、o1モデルをエージェント・インフラストラクチャのプランナーとして使用し、ワークフロー内の他のモデルをオーケストレーションして、マルチステップのタスクを効率的に完了できるようにしています。 OpenAIは、o1モデルが適切な種類のデータを選択し、大規模で複雑な問題をより小さく管理可能なモジュールに分解することに非常に優れているため、他のモデルが特定の実行に集中できることを発見しました"
--製薬業界向けAI知識プラットフォーム「Argon AI
o1モデルは、OpenAIのAIワーキングアシスタントであるLindyの多くのエージェントワークフローを強力にサポートします。 このモデルは、ユーザーのカレンダーや電子メールから重要な情報を抽出するために関数コールを使用することができ、会議のスケジュール、電子メールの送信、および日常的なタスクの他の側面の管理を自動的に支援します。 OpenAIは、問題を引き起こしていたリンディの過去のエージェントステップをすべてo1モデルに切り替え、リンディのエージェント機能がほぼ一晩で完璧になったことを確認しました。"
--Lindy.AI, 仕事AIアシスタント
5.視覚的推論:画像の背後にある情報を洞察する
今日現在o1 は、視覚的な推論機能をサポートする唯一の推論モデルである。 o1 とともに GPT-4o との間に有意な差がある。o1 複雑な構造の図表や画質の悪い写真など、最も困難な視覚情報でも効果的に扱うことができる。 このことは o1 視覚情報処理分野における独自の優位性。
AIマーチャント・モニタリング・プラットフォームのSafetykitは、「OpenAIは、高級宝飾品のレプリカ、絶滅危惧種、規制品目を含む何百万ものオンライン商品のリスクとコンプライアンス・レビューの自動化に取り組んでいます。 OpenAIの最も困難な画像分類タスクでは、GPT-4oモデルの精度は50%にとどまりました。
o1このモデルは、OpenAIの既存のプロセスに変更を加えることなく、最大88%という驚異的な精度を達成しています。"-AIマーチャント・モニタリング・プラットフォーム「Safetykit
OpenAI独自の内部テストでも、以下のことが示されている。o1 モデルは、非常に詳細な建築図面から備品や材料を特定し、包括的な部品表を生成することができる。 OpenAIによって観察された最も驚くべき現象のひとつはo1 例えば、建築図面のあるページの凡例を、明示的な指示なしに別のページに正確に適用することができます。 下の例では、"4x4のPT木製柱 "に対してo1 このモデルは、凡例に基づいて「PT」が「加圧処理」を意味することを正しく識別することができた。 これは o1 複雑な視覚情報理解や文書横断的推論において、このモデルの威力を発揮する。

6.コードレビュー、デバッグ、品質向上:卓越性の追求、コードの最適化
推論モデルはコードレビューと改善に優れており、特に大規模なコードベースを扱うのに適している。 推論モデルのレイテンシが比較的高いことから、コードレビュータスクは通常バックグラウンドで実行される。 このことは、レイテンシにもかかわらず、推論モデルが、特に高いリアルタイム性能を必要としないシナリオにおいて、コード解析と品質管理において重要な用途を持つことを示唆している。
AIコードレビューのスタートアップCodeRabbitは、「OpenAIは、GitHubやGitLabなどのコードホスティングプラットフォーム上で自動化されたAIコードレビューサービスを提供している。 コードレビュープロセスは本質的にレイテンシーに左右されないが、複数のファイルにわたるコード変更を深く理解する必要がある。 o1モデルが優れているのはこの点で、人間のレビュアーが簡単に見逃してしまうようなコードベースの微妙な変更を確実に検出します。 oシリーズのモデルに切り替えた後、OpenAIでは製品のコンバージョンが3倍増加しました。"
-AIコードレビューのスタートアップ、CodeRabbit社
たとえ GPT-4o 歌で応える GPT-4o mini モデルは低遅延コーディングのシナリオに適しているかもしれないが、OpenAIは次のようにも見ている。 o3-mini このモデルは、レイテンシーに左右されないコード生成のユースケースに優れている。 つまり o3-mini また、特に高いコード品質が要求され、レイテンシーに比較的寛容なアプリケーション・シナリオでは、コード生成の分野でも可能性がある。
AIによるコード補完の新興企業 コーディウム 困難なコーディング作業に直面しても
o3-miniモデルはまた、一貫して高品質で決定的なコードを生成することが可能であり、問題が十分に定義されている場合には、非常に頻繁に正しい解を与える。 他のモデルは、小規模で迅速なコードの反復にしか適さないかもしれない。o3-miniモデルは、複雑なソフトウェア設計システムの計画と実行を専門としている。"--AI主導のコード拡張スタートアップ、Codeium
7.モデル評価とベンチマーキング:客観的評価とベスト・オブ・ベストの選択
OpenAIはまた、推論モデルが他のモデル応答のベンチマークや評価において優れた性能を発揮することも発見した。 データ検証は、特にヘルスケアのようなデリケートな分野において、データセットの品質と信頼性を確保するために非常に重要です。 伝統的な検証方法は、事前に定義されたルールやパターンに依存していますが、次のような方法は、データセットの品質と信頼性を保証する上で非常に重要です。 o1 歌で応える o3-mini このような高度なモデルは、コンテキストを理解し、それについて推論することができるため、より柔軟でインテリジェントな検証手法を可能にする。 このことは、推論モデルが他のモデルの出力の質を評価する「審判」として機能することを示唆しており、AIシステムの反復的最適化にとって重要である。
AI評価プラットフォームのBraintrustは、「多くの顧客が、評価プロセスの一環としてBraintrustプラットフォームのLLM-as-a-judge機能を利用している。 例えば、ヘルスケア企業は次のようなツールを使うかもしれません。
gpt-4oこのようなマスターモデルを使って、患者の病歴の問題を要約し、そしてo1モデルを使って抄録の質を評価しています。 あるBraintrustの顧客は4oレフェリーとしてモデルを使用した場合のF1スコアは0.12であった。o1モデリング後、F1スコアは0.74に跳ね上がった!これらのユースケースでは、以下のことが判明した。o1モデルの推論力は、特に最も難しく複雑な採点作業において、出来上がった結果のニュアンスをとらえる上で大きな変化をもたらす"--AI評価プラットフォームBraintrust
推論モデルを効果的に促すコツ:シンプルさが第一
推論モデルは、明確で簡潔なプロンプトを受け取ったときに、最高のパフォーマンスを発揮する傾向がある。 伝統的なキュー・エンジニアリングの手法の中には、モデルに「ステップ・バイ・ステップで考える」ように指示するものがありますが、パフォーマンスを向上させるのに有効でない場合があり、時には逆効果になることさえあります。 ここでは、いくつかのベストプラクティスを紹介します。また、キュー・エンジニアリングの例を参考にすることもできます。
- 開発者メッセージはシステムメッセージに取って代わる。 をとおして
o1-2024-12-17バージョン以降、推論モデルは、モデル仕様に記述された命令チェーンの動作に適合させるため、従来のシステムメッセージではなく、開発者メッセージをサポートするようになった。 - プロンプトはシンプルで直接的なものにしましょう。 推論モデルは明確で簡潔な指示を理解し、それに反応することが得意である。 したがって、複雑なキューエンジニアリング技術よりも、明確で直接的な指示の方が推論モデルにとって効果的です。
- 思考の連鎖を避けるヒント 推論モデルはすでに内部で推論機能を持っているので、「ステップバイステップで考えなさい」とか「推論プロセスを説明しなさい」と促す必要はない。 この冗長なプロンプトは、かえってモデルのパフォーマンスを低下させる可能性がある。
- 区切り記号を使用して、明瞭性を高める。 Markdown、XMLタグ、セクションの見出しなどのセパレータを使用して、入力の異なる部分を明確にラベル付けすることで、モデルが異なるセクションの内容を正確に理解するのに役立ちます。
- 少ないサンプルの手がかりを検討する前に、ゼロサンプルの手がかりを優先する。 推論モデルは通常、少ないサンプル例を必要とせずに良い結果を出します。 そのため、まずは例なしでサンプル数ゼロのヒントを書いてみることをお勧めします。 出力結果に対してより複雑な要求がある場合は、入力と希望する出力の例をヒントに含めるとよいでしょう。 しかし、その例がプロンプトの指示と矛盾しないようにすることが重要です。
- 明確で具体的な指導を行う。 モデルからの回答範囲を制限するような明確な制約がある場合(例えば、「500ドル以下の予算で解決策を提案する」)、プロンプトにその制約を明確に記述します。
- 最終目標の明確化。 指示では、成功した回答を判断する基準をできるだけ具体的に記述し、成功基準が満たされるまで推論と反復を続けるようモデルに促します。
- Markdownフォーマットコントロール。 をとおして
o1-2024-12-17バージョン1から、APIの推論モデルはデフォルトでMarkdownフォーマットを含むレスポンスを生成しないようになりました。 モデルにMarkdownフォーマットをレスポンスに含ませたい場合は、文字列Formatting re-enabled.
推論モデルAPIの使用例
推論モデルは、その「思考」プロセスに特徴がある。従来の言語モデルとは異なり、推論モデルは内部で深く考え、答えを出す前に長い推論の連鎖を構築する。OpenAIの公式説明にもあるように、これらのモデルはユーザーに応答する前に深く考える。このメカニズムにより、推論モデルは、複雑なパズルの解き方、コーディング、科学的推論、エージェントのワークフローにおける複数ステップのプランニングなどのタスクに優れた能力を発揮する。
OpenAIのGPTモデルと同様に、OpenAIは異なるニーズを満たすために2つの推論モデルを提供しています:o3-mini このモデルは、より小型でより速いスピードが特徴だ。 トークン コストも比較的低い。 o1 一方、モデルは、より強力な問題解決のために、より大きなスケールと若干遅いスピードをトレードオフにする。o1 モデルは一般的に、複雑なタスクを扱うときにより質の高い応答を生成し、ドメイン間でより優れた一般化性能を示す。
クイックスタート
開発者がすぐに始められるように、OpenAIは使いやすいAPIインターフェースを提供しています。ここでは、推論モデルをチャットの完了に使用するクイックスタートの例を示します:
チャットでの推論モデルの使用
import OpenAI from "openai";
const openai = new OpenAI();
const prompt = `
编写一个 bash 脚本,该脚本接收一个以字符串形式表示的矩阵,
格式为 '[1,2],[3,4],[5,6]',并以相同的格式打印转置矩阵。
`;
const completion = await openai.chat.completions.create({
model: "o3-mini",
reasoning_effort: "medium",
messages: [
{
role: "user",
content: prompt
}
],
});
console.log(completion.choices[0].message.content);
from openai import OpenAI
client = OpenAI();
prompt = """
编写一个 bash 脚本,该脚本接收一个以字符串形式表示的矩阵,
格式为 '[1,2],[3,4],[5,6]',并以相同的格式打印转置矩阵。
"""
response = client.chat.completions.create(
model="o3-mini",
reasoning_effort="medium",
messages=[
{
"role": "user",
"content": prompt
}
]
);
print(response.choices[0].message.content);
curl https://api.openai.com/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-d '{
"model": "o3-mini",
"reasoning_effort": "medium",
"messages": [
{
"role": "user",
"content": "编写一个 bash 脚本,该脚本接收一个以字符串形式表示的矩阵,格式为 \"[1,2],[3,4],[5,6]\",并以相同的格式打印转置矩阵。"
}
]
}'
推論の強度:モデルにおける思考の深さをコントロールする
上記の例ではreasoning_effort このパラメータ(これらのモデルの開発中は親しみを込めて "ジュース "と呼ばれる)は、応答を生成する前に推論計算をどの程度行うかモデルを導くために使用される。ユーザーはこのパラメータに lowそしてmedium もしかしたら high 3つの値のうちの1つ。どこでlow モデルはスピードとトークン・コストの削減に重点を置いている。 high モードは、モデルによるより深く包括的な推論を促しますが、トークンの消費と応答時間が増加します。デフォルト値は mediumその目的は、スピードと推論精度のバランスを達成することである。開発者は、実際のアプリケーションシナリオのニーズに応じて推論強度を柔軟に調整し、最適なパフォーマンスと費用対効果を実現することができます。
推論の仕組み:モデルの "思考 "プロセスの徹底分析
推論モデルは、従来の入力と出力のトークンに加えて トークンについての推論 この概念。これらの推論トークンは、モデルの「思考プロセス」に類似しており、モデルはこれらを使用して、ユーザーのキューに対する理解を分解し、答えを生成するための複数の可能な経路を探索する。推論トークンの生成が完了した後にのみ、モデルは最終的な答え、ユーザーから見える補完トークンを出力し、コンテキストから推論トークンを破棄します。
次の図は、ユーザーとアシスタントの間のマルチステップダイアログの例である。対話の各ステップにおいて、入力トークンと出力トークンは保持され、推論トークンはモデルによって破棄される。
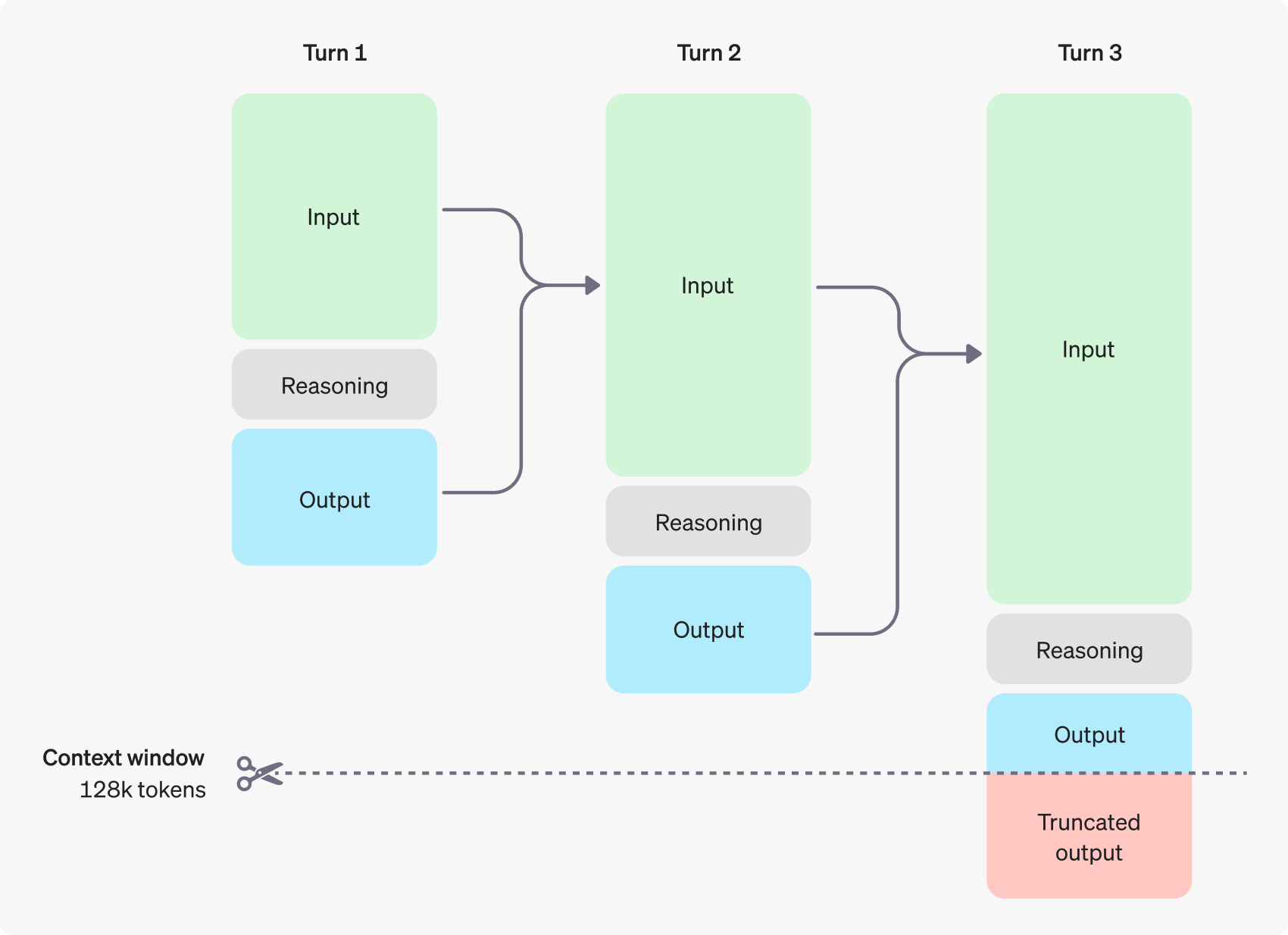
推論トークンはAPIインターフェースからは見えませんが、モデルのコンテキストウィンドウを占有し、トークンの総使用量にカウントされます。したがって、実際には、開発者は推論トークンの影響を考慮し、モデルのコンテキストウィンドウとトークン消費を適切に管理する必要があります。
コンテクスチュアル・ウィンドウの管理:モデルに十分な "考える余地 "を確保する
問題の複雑さにもよりますが、モデルは数百から数万の推論トークンを生成する必要があるかもしれません。 completion_tokens_details フィールドで、特定のリクエストに対してモデルによって使われた推論トークンの正確な数を見ることができます:
{
"usage": {
"prompt_tokens": 9,
"completion_tokens": 12,
"total_tokens": 21,
"completion_tokens_details": {
"reasoning_tokens": 0,
"accepted_prediction_tokens": 0,
"rejected_prediction_tokens": 0
}
}
}
様々なモデルのコンテキスト・ウィンドウの長さは、モデル・リファレンス・ページで利用することができる。コンテキスト・ウィンドウの適切な評価と管理は、推論モデルが効果的に機能するために不可欠です。
コスト管理:トークン消費の微調整と最適化
推論モデルのコストを効果的に管理するために、ユーザーは max_completion_tokens このパラメータは、推論トークンや補完トークンを含め、モデルによって生成されるトークンの総数を制限します。
以前のモデルではmax_tokens このパラメータは、モデルによって生成されるトークン数と、ユーザーに見えるトークン数の両方を制御する。ただし、推論モデルの場合、内部推論トークンが導入されるため、モデルによって生成されるトークン の総数が、最終的にユーザーに見えるトークンの数を上回ることがあります。
アプリケーションによっては max_tokens パラメータがAPIから返されるトークンの数と一致するように、OpenAIは特別な max_completion_tokens この明示的なパラメータ設定は、新しいモデルを使用する既存のアプリケーションのスムーズな移行を保証し、潜在的な互換性の問題を回避します。これまでのすべてのモデルではmax_tokens パラメータの機能に変更はない。
推論のためのスペースを確保する:「思考」の中断を避ける
生成されたトークンの数がコンテキスト・ウィンドウの制限に達した場合、またはユーザーが設定した max_completion_tokens の値で、APIはチャット完了レスポンスを返します。 finish_reason フィールドは length.これは、モデルがユーザーから見える補完トークンを生成する前に起こる可能性があります。つまり、ユーザーは入力トークンと推論トークンにお金を払わなければならないかもしれませんが、最終的に目に見える応答を受け取ることはありません。
上記を避けるには、常にコンテキストウィンドウに十分なスペースを確保するか、あるいは max_completion_tokens openAIは、これらの推論モデルを最初に試すときに、推論と出力プロセス用に少なくとも25,000トークンのスペースを確保することを推奨している。ユーザーがプロンプトに必要な推論トークンの数に慣れるにつれて、このバッファーサイズは、よりきめ細かいコスト制御のために適宜調整することができます。
ヒント:推論モデルの可能性を引き出す
推論モデルとGPTモデルのプロンプトを表示する際に、ユーザーが認識する必要がある重要な違いがいくつかあります。全体として、推論モデルは、高レベルのガイダンスのみが提供されるタスクに対して、より良い結果を与える傾向がある。これはGPTモデルとは対照的で、GPTモデルは通常、非常に正確な指示を受けた場合に良い結果を出します。
- 経験豊富な先輩のような推論モデル -- 何を達成したいかを伝えるだけで、ユーザーは自律的に具体的な詳細を解決してくれる。
- GPTモデルはジュニア・アシスタントに近い -- 具体的なアウトプットを作成するための明確で詳細な指示があるときに、最も効果的に機能する。
推論モデルを使用するためのベストプラクティスの詳細については、OpenAIの公式ガイドを参照してください。
ヒント例:応用シナリオの実演
コーディング(コードのリファクタリング)
OpenAIのoシリーズのモデルは、強力なアルゴリズム理解とコード生成機能を示しています。次の例は、o1モデルを使用して特定の基準にリファクタリングする方法を示しています。 反応 コンポーネント
コード手直し
import OpenAI from "openai";
const openai = new OpenAI();
const prompt = `
指令:
- 给定以下 React 组件,修改它,使非小说类书籍显示红色文本。
- 回复中仅返回代码
- 不要包含任何额外的格式,例如 markdown 代码块
- 对于格式,使用四个空格缩进,并且不允许任何代码行超过 80 列
const books = [
{ title: 'Dune', category: 'fiction', id: 1 },
{ title: 'Frankenstein', category: 'fiction', id: 2 },
{ title: 'Moneyball', category: 'nonfiction', id: 3 },
];
export default function BookList() {
const listItems = books.map(book =>
<li>
{book.title}
</li>
);
return (
<ul>{listItems}</ul>
);
}
`.trim();
const completion = await openai.chat.completions.create({
model: "o3-mini",
messages: [
{
role: "user",
content: prompt,
},
],
});
console.log(completion.usage.completion_tokens_details);
from openai import OpenAI
client = OpenAI();
prompt = """
指令:
- 给定以下 React 组件,修改它,使非小说类书籍显示红色文本。
- 回复中仅返回代码
- 不要包含任何额外的格式,例如 markdown 代码块
- 对于格式,使用四个空格缩进,并且不允许任何代码行超过 80 列
const books = [
{ title: 'Dune', category: 'fiction', id: 1 },
{ title: 'Frankenstein', category: 'fiction', id: 2 },
{ title: 'Moneyball', category: 'nonfiction', id: 3 },
];
export default function BookList() {
const listItems = books.map(book =>
<li>
{book.title}
</li>
);
return (
<ul>{listItems}</ul>
);
}
"""
response = client.chat.completions.create(
model="o3-mini",
messages=[
{
"role": "user",
"content": prompt
}
]
);
print(response.choices[0].message.content);
コード(プロジェクト計画)
OpenAIのoシリーズモデルは、マルチステッププロジェクトプランの開発にも適しています。次の例では、o1モデルを使用して、Pythonアプリケーションの完全なファイルシステム構造を作成し、必要な機能を実装するPythonコードを生成する方法を示します。
Pythonプロジェクトの計画と作成
import OpenAI from "openai";
const openai = new OpenAI();
const prompt = `
我想构建一个 Python 应用程序,它可以接收用户的问题,并在数据库中查找答案。
数据库中存储了问题到答案的映射关系。如果找到密切匹配的问题,则检索匹配的答案。
如果没有找到,则要求用户提供答案,并将问题/答案对存储在数据库中。
为我创建一个目录结构计划,我需要这个结构,然后完整地返回每个文件中的代码。
只在开头和结尾提供你的推理过程,不要在代码中穿插推理。
`.trim();
const completion = await openai.chat.completions.create({
model: "o3-mini",
messages: [
{
role: "user",
content: prompt,
},
],
});
console.log(completion.usage.completion_tokens_details);
from openai import OpenAI
client = OpenAI();
prompt = """
我想构建一个 Python 应用程序,它可以接收用户的问题,并在数据库中查找答案。
数据库中存储了问题到答案的映射关系。如果找到密切匹配的问题,则检索匹配的答案。
如果没有找到,则要求用户提供答案,并将问题/答案对存储在数据库中。
为我创建一个目录结构计划,我需要这个结构,然后完整地返回每个文件中的代码。
只在开头和结尾提供你的推理过程,不要在代码中穿插推理。
"""
response = client.chat.completions.create(
model="o3-mini",
messages=[
{
"role": "user",
"content": prompt
}
]
);
print(response.choices[0].message.content);
STEM研究
OpenAIのoシリーズモデルは、STEM(科学、技術、工学、数学)研究において優れたパフォーマンスを発揮しています。これらのモデルは、基本的な研究タスクをサポートするように設計されたプロンプトに対して、しばしば印象的な結果をもたらします。
基礎科学の研究に関する問題提起
import OpenAI from "openai";
const openai = new OpenAI();
const prompt = `
为了推进新型抗生素的研究,我们应该考虑研究哪三种化合物?
为什么我们应该考虑它们?
`;
const completion = await openai.chat.completions.create({
model: "o3-mini",
messages: [
{
role: "user",
content: prompt,
}
],
});
console.log(completion.choices[0].message.content);
from openai import OpenAI
client = OpenAI();
prompt = """
为了推进新型抗生素的研究,我们应该考虑研究哪三种化合物?
为什么我们应该考虑它们?
"""
response = client.chat.completions.create(
model="o3-mini",
messages=[
{
"role": "user",
"content": prompt
}
]
);
print(response.choices[0].message.content);
公式例
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事



コメントはありません