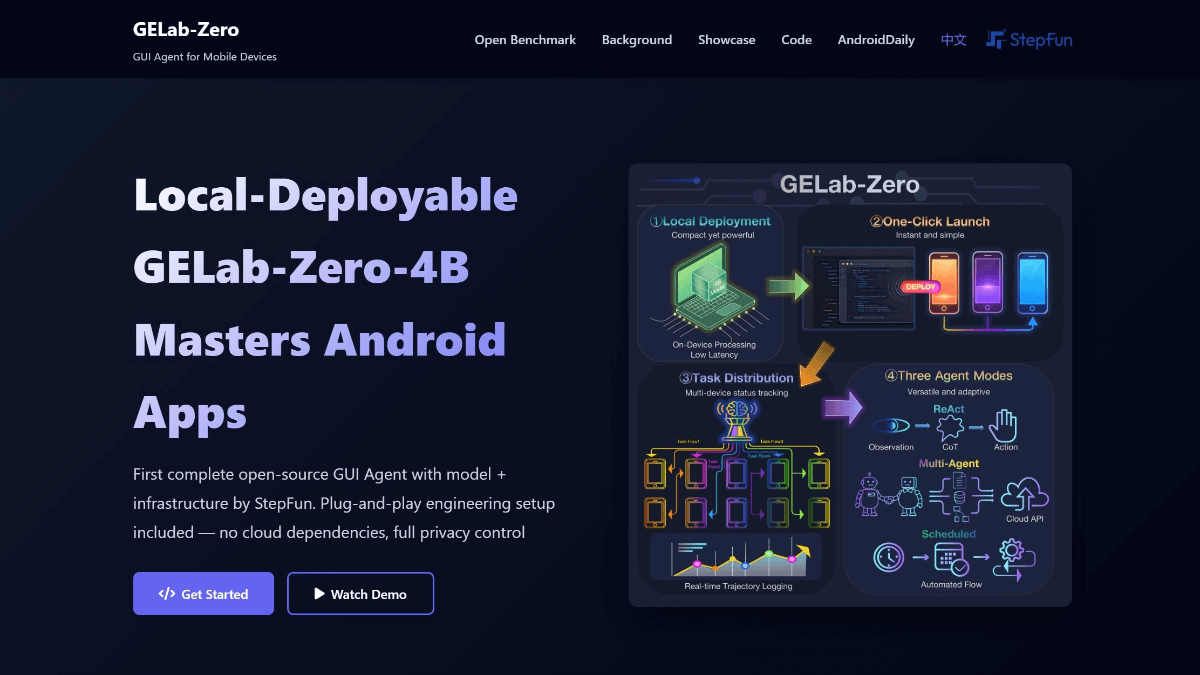
Open-Reasoner-Zero:オープンソースの大規模推論強化学習トレーニングプラットフォーム

はじめに
Open-Reasoner-Zeroは強化学習(RL)研究に特化したオープンソースプロジェクトで、GitHub上のOpen-Reasoner-Zeroチームによって開発されています。効率的でスケーラブルかつ使いやすい学習フレームワークを提供することで、人工知能(AI)分野、特に一般人工知能(AGI)に向けた研究プロセスを加速することを目的としている。このプロジェクトはQwen2.5モデル(7Bおよび32Bパラメータバージョン)をベースとし、OpenRLHF、vLLM、DeepSpeed、Rayなどの技術を組み合わせて、完全なソースコード、学習データ、モデルの重みを提供する。特筆すべきは、DeepSeek-R1-Zeroの30分の1以下の学習ステップで同レベルの性能を達成し、リソースの効率的な利用を実証している点である。このプロジェクトはMITライセンスに基づき、ユーザーが自由に使用・変更できるため、研究者や開発者の共同研究に最適である。

機能一覧
- 効率的な集中学習トレーニングGPUを最大限に活用し、1つのコントローラでトレーニングとジェネレーションをサポートします。
- 完全なオープンソースリソースこのモデルはシンプルで使いやすいツールで、57kの高品質なトレーニングデータ、ソースコード、パラメータ設定、モデルの重みを提供する。
- 高性能モデルのサポートQwen2.5-7BとQwen2.5-32Bをベースとし、優れた推論性能を提供。
- 柔軟な研究枠組みモジュール式の設計のため、研究者は実験を容易に適応させ、拡張することができます。
- Dockerのサポートトレーニング環境の複製性を確保するためにDockerfileを提供する。
- パフォーマンス評価ツールGPQA Diamondのパフォーマンス比較など、ベンチマークデータや評価結果のプレゼンテーションが含まれています。
ヘルプの使用
設置プロセス
Open-Reasoner-Zeroを使用するには、ある程度の技術的知識が必要です。 以下は、LinuxまたはUnixライクなシステムで実行するのに適した、詳細なインストールと操作のガイドです。
環境準備
- 基本的な依存関係のインストール::
- Git、Python 3.8+、NVIDIA GPUドライバー(CUDAサポートが必要)がシステムにインストールされていることを確認してください。
- トレーニング環境を迅速にデプロイするために、Docker(推奨バージョン20.10以上)をインストールします。
sudo apt update sudo apt install git python3-pip docker.io
- プロジェクト・ウェアハウスのクローン::
- ターミナルで以下のコマンドを実行し、プロジェクトをローカルにダウンロードする:
git clone https://github.com/Open-Reasoner-Zero/Open-Reasoner-Zero.git cd Open-Reasoner-Zero - Dockerで環境を設定する::
- このプロジェクトは、トレーニング環境の構築を容易にするDockerfileを提供する。
- プロジェクトのルート・ディレクトリで実行する:
docker build -t open-reasoner-zero -f docker/Dockerfile .- ビルドが完了したら、コンテナを起動する:
docker run -it --gpus all open-reasoner-zero bash- これにより、必要な依存関係がプリインストールされた、GPUをサポートするコンテナ環境に入ります。
- 依存関係の手動インストール(オプション)::
- Dockerを使用していない場合は、依存関係を手動でインストールできる:
pip install -r requirements.txt- OpenRLHF、vLLM、DeepSpeed、および Ray がインストールされていることを確認してください。
機能 操作の流れ
1.トレーニングモデル
- トレーニングデータの準備::
- このプロジェクトには、以下の場所にある57kの高品質なトレーニングデータが含まれている。
dataフォルダー - カスタムデータが必要な場合は、ドキュメントの指示に従ってフォーマットを整理し、置き換えてください。
- このプロジェクトには、以下の場所にある57kの高品質なトレーニングデータが含まれている。
- プライミングトレーニング::
- コンテナまたはローカル環境で以下のコマンドを実行する:
python train.py --model Qwen2.5-7B --data-path ./data- パラメータの説明
--model例:Qwen2.5-7B、Qwen2.5-32B)。--data-pathトレーニングデータのパスを指定する。
- トレーニングログはマスターノード端末に表示され、進捗状況を簡単に確認することができます。
2.パフォーマンス評価
- ベンチマークテストの実行::
- 提供された評価スクリプトを使用して、モデルの性能を比較する:
python evaluate.py --model Qwen2.5-32B --benchmark gpqa_diamond- 出力は、GPQA Diamondなどのベンチマークにおけるモデルの精度を示す。
- 評価レポートを見る::
- このプロジェクトには、パフォーマンスとトレーニング時間のスケーリングを示すチャート(図1や図2など)が含まれています。
docsフォルダーから探す。
- このプロジェクトには、パフォーマンスとトレーニング時間のスケーリングを示すチャート(図1や図2など)が含まれています。
3.修正と拡張
- 調整パラメーター::
- コンパイラ
config.yamlファイルで、学習率やバッチサイズなどのハイパーパラメータを変更する。
learning_rate: 0.0001 batch_size: 16 - コンパイラ
- 新機能の追加::
- このプロジェクトはモジュール式で、次のようなことが可能です。
srcフォルダに新しいモジュールを追加します。例えば、新しいデータ前処理スクリプトを追加します:
# custom_preprocess.py def preprocess_data(input_file): # 自定义逻辑 pass - このプロジェクトはモジュール式で、次のようなことが可能です。
取り扱い上の注意
- ハードウェア要件Qwen2.5-32B トレーニングをサポートするには、最低 24GB のビデオメモリを搭載した GPU(NVIDIA A100 など)を推奨します。
- ログ監視トレーニング中は端末の電源を入れたままにしておき、いつでもログをチェックして問題を解決してください。
- 地域支援質問はGitHubのIssuesか、hanqer@stepfun.com。
実践例
Qwen2.5-7Bに基づいてモデルをトレーニングしたいとします:
- Dockerコンテナに入る。
- うごきだす
python train.py --model Qwen2.5-7B --data-path ./data. - 数時間待ち(ハードウェアによって異なる)、終了したら実行する。
python evaluate.py --model Qwen2.5-7B --benchmark gpqa_diamond. - 出力を見て、パフォーマンスの向上を確認する。
これらの手順により、ユーザーは実験の再現や新機能の開発など、Open-Reasoner-Zeroをすぐに使い始めることができ、効率的に作業を進めることができます。
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事


コメントはありません