多言語ASR - Metaの多言語音声認識フレームワーク

多言語ASRとは?
オムニリンガルASRはMeta社の多言語音声認識フレームワークで、1600以上の言語をカバーし、文字誤り率は10%以下の78%です。 CTCとTransformerデコーダーを組み合わせた70億パラメータのwav2vec 2.0エンコーダーは、未知の言語のゼロサンプル転写をサポートし、新しい言語に適応するために必要なサンプル数はわずかです。言語。このモデルはオープンソースで、350の低リソース言語のコーパスを含んでおり、世界中の絶滅危惧言語のデジタル化と音声技術の導入を促進しています。
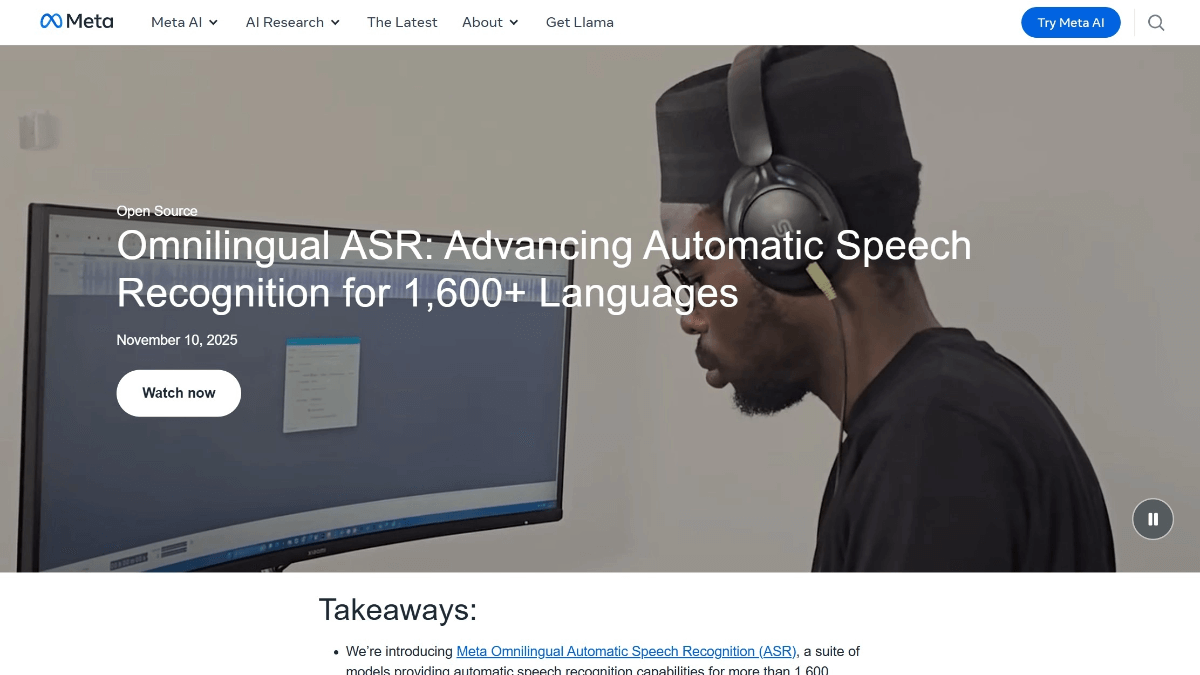
多言語ASRの特徴
- 多言語対応1,600以上の言語をサポートし、低リソース言語や絶滅危惧言語を幅広くカバー。
- 低リソース言語サポート自己教師付き学習とデータ強化技術により、低リソース言語における疎なデータの問題を効果的に解決し、音声認識の閾値を下げる。
- サンプル学習能力ゼロ大規模なコーパスを必要とせず、わずかな例文で新しい言語を書き写すことができるため、対象言語が大幅に拡大する。
- ハイパフォーマンス・アーキテクチャーwav2vec2.0エンコーダーとCTCおよびTransformerデコーダーの組み合わせは、高精度で高性能な音声認識をサポートします。
- オープンソースとコラボレーション音声認識技術を発展させ、絶滅の危機に瀕している言語の保護を支援するために、世界中の開発者や研究者が協力し合うことを促進するために、モデルやデータセットをオープンソース化します。
多言語ASRの主な利点
- 幅広い言語をカバー多くの低リソース言語や絶滅危惧言語を含む1,600以上の言語をサポートし、音声認識における世界の言語カバー率を大幅に向上。
- サンプル学習能力ゼロ数個の音声とテキストのサンプルだけで、未知の言語を書き写すことは、新しい言語を開発するコストを大幅に削減します。
- ハイパフォーマンス・アーキテクチャー70億パラメータのwav2vec 2.0エンコーダと高度なデコーダを使用し、自己教師付き学習と組み合わせることで、高精度な音声認識を実現。
- オープンソースとコミュニティ・サポートモデルやデータセットのオープンソース化により、世界中の開発者や研究者の参加を促し、技術開発や言語保存を促進する。
- 革新的なデータ強化技術モデルの汎化能力を向上させるために、合成音声のような技術を通じて、疎な低リソース言語データの問題を解決する。
- 柔軟なデコーダ選択CTCデコーダーとトランスフォーマーデコーダーの両方のオプションを提供し、さまざまなシナリオの性能と効率のニーズを満たします。
オムニリンガルASRの公式ウェブサイトは?
- プロジェクトのウェブサイト:: https://ai.meta.com/blog/omnilingual-asr-advancing-automatic-speech-recognition/
- GitHubリポジトリ:: https://github.com/facebookresearch/omnilingual-asr
- HuggingFaceモデルライブラリ:: https://huggingface.co/datasets/facebook/omnilingual-asr-corpus
- 技術論文:: https://ai.meta.com/research/publications/omnilingual-asr-open-source-multilingual-speech-recognition-for-1600-languages/
非言語ASRの対象者
- 言語研究者低資源言語や絶滅危惧言語の研究に利用でき、言語保存や言語研究に役立ちます。
- 技術開発者オープンソースの利点を生かした二次開発や統合を行う音声認識アプリケーションの開発に適しています。
- コンテンツクリエーター多言語音声・映像コンテンツの制作を容易にし、迅速な文字起こしや字幕生成を可能にします。
- 教育者言語教育と異文化コミュニケーションを支援する多言語教育リソースの開発を支援する。
- ビジネスユーザーカスタマーサービス、会議記録、その他のシナリオなど、多言語音声認識サービスを必要とする企業に適しています。
- コミュニティおよび非営利団体言語多様性プログラムを支援し、文化交流と言語保護を促進するために利用できる。
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事

コメントはありません