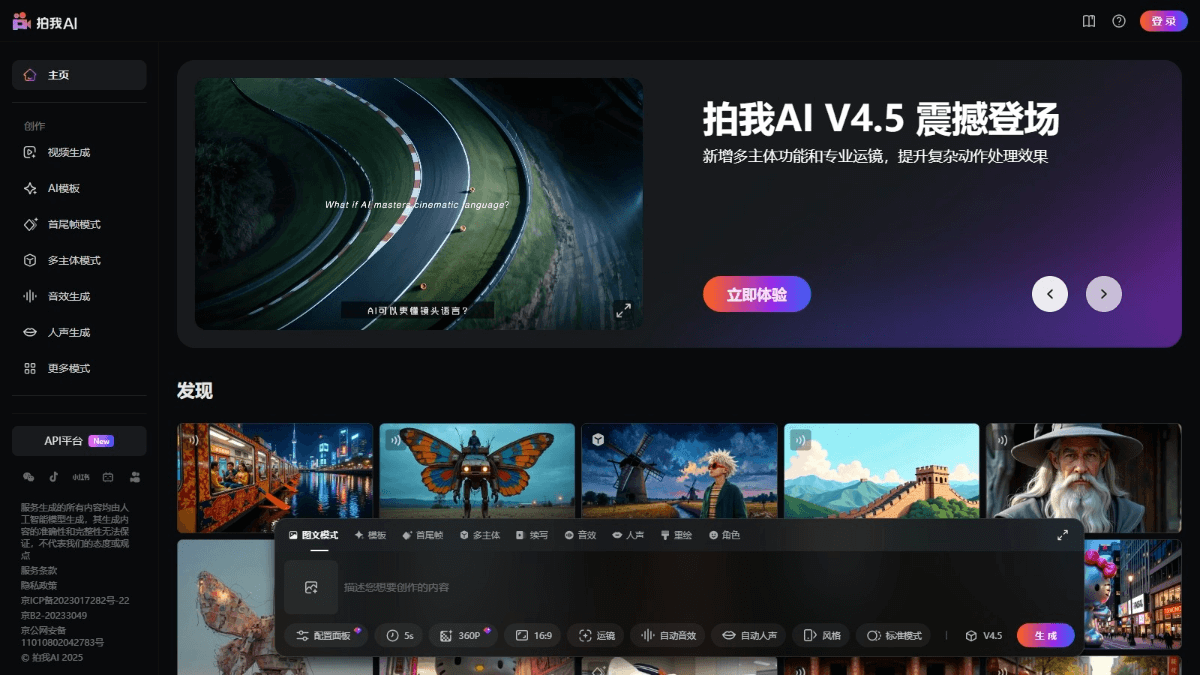
MTEB:テキスト埋め込みモデルの性能を評価するベンチマーク

はじめに
MTEB (Massive Text Embedding Benchmark)はembeddings-benchmarkチームによって開発され、GitHubでホストされているオープンソースプロジェクトで、テキスト埋め込みモデルの包括的な性能評価を提供することを目的としています。mtebは、33種類のモデルのテストを通じて、様々なタスクにおける異なるモデルの性能差を明らかにし、開発者が特定のアプリケーションに適した埋め込みモデルを選択するのに役立ちます。このプロジェクトはオープンソースコードを提供しており、ユーザは自由にテストを実行したり、公開リーダーボードに新しいモデルを投稿することができます。

アクセス:https://huggingface.co/spaces/mteb/leaderboard

機能一覧
- マルチタスク評価サポート意味的テキスト類似度(STS)、検索、クラスタリングなど、幅広い応用シナリオをカバーする8つの埋め込みタスクを収録。
- 多言語データセット112の言語をサポートし、グローバルなアプリケーション開発に適した多言語モデルのテスト機能を提供します。
- モデル・パフォーマンス・ランキング33モデルのテスト結果を表示するリーダーボードを内蔵し、簡単に比較・選択できます。
- カスタマイズされたモデルテストユーザは、評価を実行するためのわずかなコードで、カスタム組込みモデルをインポートすることができます。
- キャッシュ埋め込み機能大規模実験のリピートテスト効率を最適化する埋め込み結果キャッシングをサポート。
- 柔軟なパラメータ調整試験の柔軟性を高めるために、バッチサイズ調整などのコーディングパラメータ設定を提供します。
- オープンソース・サポートソースコードはすべて公開されており、ユーザーは必要に応じて機能を変更したり拡張したりすることができます。
- コミュニティの拡張性新しいタスク、データセット、モデルの提出をサポートし、継続的にテストを充実させる。
ヘルプの使用
設置プロセス
MTEBはPythonベースのツールで、導入と実行にはプログラミング環境が必要です。以下は詳細なインストール手順です:
1.環境準備
- オペレーティングシステムWindows、MacOS、Linuxに対応しています。
- パイソン版Python 3.10以上が必要です。
python --versionチェックする。 - GitツールGitHubからソースコードを取得する際に使用するので、事前にインストールしておくことをお勧めします。
2.コードベースのクローン化
ターミナルを開き、以下のコマンドを実行してMTEBのソースコードを取得する:
git clone https://github.com/embeddings-benchmark/mteb.git
cd mteb
これでプロジェクトがローカルにダウンロードされ、プロジェクト・ディレクトリに入ります。
3.依存関係のインストール
MTEBはいくつかのPythonライブラリのサポートを必要とするため、競合を避けるために依存関係をインストールする前に仮想環境を作成することを推奨します:
python -m venv venv
source venv/bin/activate # Linux/MacOS
venv\Scripts\activate # Windows
次に、コアの依存関係をインストールする:
pip install -r requirements.txt
リーダーボードのインターフェイスを実行するには、Gradioもインストールする必要がある:
pip install mteb[gradio]
4.インストールの検証
以下のコマンドを実行して、利用可能なタスクをチェックし、インストールが成功することを確認する:
mteb --available_tasks
タスクリストに戻れば、環境設定は完了です。
使用方法
MTEBの中核機能はテキスト埋め込みモデルの評価であり、主な操作手順は以下の通りである:
機能1: 既存モデルを評価するための事前構築タスクの実行
MTEBは既存のモデル(例えばSentenceTransformerモデル)の直接テストをサポートする。例えば、Banking77Classificationタスクにおける "average_word_embeddings_komninos "モデルの性能評価:
mteb -m average_word_embeddings_komninos -t Banking77Classification --output_folder results/average_word_embeddings_komninos --verbosity 3
-mモデル名を指定する。-tタスク名を指定する。--output_folder結果を保存するパスを指定します。--verbosity 3詳細ログを表示します。
結果は、各タスクのスコアを含む指定されたフォルダに保存される。
機能2:カスタムモデルのテスト
独自のモデルをテストしたければ、単純なインターフェイスを実装すればいい。SentenceTransformerを例にとってみよう:
from mteb import MTEB
from sentence_transformers import SentenceTransformer
# 加载模型
model = SentenceTransformer("average_word_embeddings_komninos")
# 定义评估任务
evaluation = MTEB(tasks=["Banking77Classification"])
# 运行评估
evaluation.run(model, output_folder="results")
実行後、結果は「results」フォルダに保存される。
特徴3:キャッシュ埋め込みによる効率の最適化
繰り返しのテストでは、埋め込み値の二重カウントを避けるためにキャッシュを有効にすることができる:
from mteb.models.cache_wrapper import CachedEmbeddingWrapper
# 包装模型以启用缓存
model_with_cache = CachedEmbeddingWrapper(model, cache_path="cache_embeddings")
evaluation.run(model_with_cache)
キャッシュ・ファイルは、タスク名で指定されたパスに保存される。
機能4:リーダーボードの表示
現在のモデルランキングを見るには、公式リーダーボードをご覧いただくか、ローカルに展開してください:
git clone https://github.com/embeddings-benchmark/leaderboard.git
cd leaderboard
pip install -r requirements.txt
python app.py
ブラウザからのアクセス http://localhost:7860リアルタイムのリーダーボードを見ることができる。
機能5:新しいタスクの追加
ユーザーは、タスク・クラスを継承することによってMTEBを拡張することができる:
from mteb.abstasks.AbsTaskReranking import AbsTaskReranking
class CustomReranking(AbsTaskReranking):
@property
def description(self):
return {
"name": "CustomReranking",
"description": "自定义重排序任务",
"type": "Reranking",
"eval_splits": ["test"],
"eval_langs": ["en"],
"main_score": "map"
}
evaluation = MTEB(tasks=[CustomReranking()])
evaluation.run(model)
操作技術
- マルチGPUサポート検索タスクには、マルチGPUアクセラレーションを使用できます:
pip install git+https://github.com/NouamaneTazi/beir@nouamane/better-multi-gpu
torchrun --nproc_per_node=2 scripts/retrieval_multigpu.py
- 選択部分集合特定のタスクのサブセットのみが評価される:
evaluation.run(model, eval_subsets=["Banking77Classification"])
- バッチサイズの調整コーディング速度の最適化
evaluation.run(model, encode_kwargs={"batch_size": 32})
以上の手順で、ユーザーは簡単にMTEBを使い始め、モデル評価や機能拡張を完了することができます。
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事


コメントはありません