
モデル量子化とは:FP32、FP16、INT8、INT4データ型の説明

道しるべ
AI技術の広大な星空の中で、ディープラーニングモデルはその優れた性能で多くの分野の革新と発展を牽引している。しかし、モデル規模の継続的な拡大は諸刃の剣のようなもので、性能を向上させる一方で、演算需要の急増とストレージの圧迫をもたらす。特にリソースに制約のあるアプリケーションシナリオでは、モデルの展開と運用が厳しい課題に直面する。
このジレンマに直面し、「量子化」と呼ばれる技術が登場した。これは繊細なメスのようなもので、モデルサイズを巧みに縮小し、計算速度を向上させ、モデル精度の許容範囲内でエネルギー消費量を大幅に削減する。量子化技術は、モデル内の高精度FP32データを低精度INT4データに変換することができ、モデルの「スリム化」と「高速化」を実現する。本記事では、量子化の原理と方法、そしてディープラーニング分野での応用について分析し、初心者でも簡単にその本質を理解できるようにする。
1.数値表現の基礎
1.1 2進数から10進数への変換
デジタル世界の要であるコンピューター・サイエンスでは、データはすべて2進数で保存される。二進法は「0」と「1」の2つの数字だけで構成されているのに対し、私たちが日常的に使っている十進法は「0」から「9」までの10個の数字で構成されている。この2つのシステム間の変換は、異なる言語間の翻訳のようなもので、コンピュータにおけるデータ表現を理解する鍵となる。
この変換プロセスは、10進数の "全体 "を2進数の "構成要素 "に分解するのと似ている。その手順は以下の通りである:
13 2で割ると商は6、余りは1(2進数の最下位桁)
6を2で割ると商は3となり、余りは0となる。
3÷2、商1、余り1
1÷2、商は0、余りは1(2進数の最上位桁)
残差は下から上に表示されている:
↑1
↑0
↑1
↑1
バイナリ結果を取得:1101
逆に、2進数1101を10進数に戻すのは、「部分」を組み立て直して「全体」を作るようなものである。右から左へ、各ビットの重みは2の累乗で増加し、一番右のビットの重みは 、 、 、 、と左へ続く。したがって、2進数の1101は10進数に変換すると、1×+1×+0×+1×=8+4+0+1=13となる。
1.2 浮動小数点数と整数の違い
(i) 整数型(INT)
INTはIntegerの略で、整数の種類を表す。整数とは、その名の通り、1、2、3などの小数部を含まない数値のことである。
INT4は4ビットの2進数で整数を表し、INT8は8ビットの2進数で整数を表す。ビット数によって整数表現の範囲が決まる。
4ビットの2進数は最大1つの異なる数値を表すことができるため、INT4で表現できる整数の範囲は限られている。符号付きINT4の場合、その範囲は通常-8から7まで、符号なしINT4の場合、その範囲は0から15までである。 8ビットの2進数は=256の異なる数を表すことができるため、-128から127までのINT8、および0から255までの符号なしINT8についても同様である。
(浮動小数点型(FP)
FPはFloating Pointの略で、浮動小数点型である。整数とは対照的に、浮動小数点数は小数部分を持つ数値を表すのに使われる。
浮動小数点数は、符号ビット、指数ビット、仮数ビットで構成される。たとえば32ビット浮動小数点数(FP32)は、1符号ビット、8指数ビット、23仮数ビットで構成される。この巧妙な設計により、浮動小数点数は、非常に小さな数値から巻尺のような非常に大きな数値まで、非常に広い範囲の値を表すことができる。
例えば、FP32は非常に小さい数(約)と非常に大きい数(約)を表すことができる。INT8(8ビット整数)は-128から127までの整数しか表すことができません。この違いは、固定長の定規(整数)とスケーラブルな巻き尺(浮動小数点数)で長さを測ることに似ており、浮動小数点数は数値表現の柔軟性と範囲の点で整数よりはるかに優れています。
(iii) よく使われるデータ型
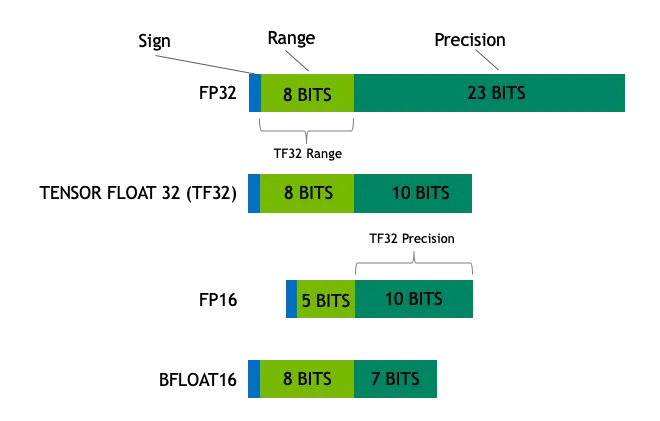
ディープラーニングや汎用コンピューティングにおける一般的なデータ型には、以下のようなものがある:
- Float32 (FP32)FP32演算は、その汎用性の高さからモデルの学習と推論を支配しており、さまざまなハードウェアで広くサポートされている。
- フロート16(FP16)FP16は16ビットの半精度浮動小数点数であり、FP32に比べて精度は低下するが、メモリフットプリントが大幅に削減され、計算速度が大幅に向上する。FP16は数値表現の範囲が比較的狭く、オーバーフローやアンダーフローのリスクがある。しかしロス・スケーリング このようなテクニックを応用することで、これらの問題を効果的に軽減することができる。
- BFloat16 (BF16)BF16 も 16 ビット浮動小数点フォーマットです。BF16は、FP32と同じ8ビットの指数ビットを保持するため、FP32と同じダイナミック・レンジを持つが、末尾ビットが7ビットしかなく、FP16よりも精度が劣るという特徴がある。しかし、BF16は末尾ビットが7ビットしかないため、FP16よりも精度が劣る。 BF16は、値の範囲が広いシナリオで優れた性能を発揮するが、精度に敏感なタスクではトレードオフが生じる可能性がある。
- イント8INT8は8ビットの整数型で、数値表現の範囲は限られていますが、メモリフットプリントは非常に小さくなっています。 INT8は主にモデルの定量化技術で使用され、高精度なFP32またはFP16からINT8にモデルパラメータを変換することで、必要なストレージ容量とモデルの計算複雑度が大幅に削減され、リソースに制約のあるデバイスへのモデルの効率的な展開への道が開かれます。
2.量的概念
2.1 定量的定義
定量化とは、モデルのデータを高精度な表現から低精度な表現に変換することを指す。画質とファイルサイズのトレードオフディープラーニングにおいて量子化とは、高精度の画像を低精度のJPEG画像に圧縮するプロセスであり、画像の主要な情報を保持したままファイルサイズを大幅に削減する。ディープラーニングの分野では、定量化は通常、モデルの重みと活性化値をFP32(32ビット浮動小数点)からFP16(16ビット浮動小数点)、あるいはINT8(8ビット整数)またはそれ以下の精度に減らすことを指す。
FP32は小さな値から大きな値まで計測できる高精度なものさしだが、その高精度の性質上、ストレージのオーバーヘッドが大きく、計算速度も比較的遅い。
FP16は半精度浮動小数点フォーマットで、値を表現するのに必要なバイナリ・ビットはわずか16ビット(符号ビット1、指数ビット5、仮数ビット10)です。FP32と比較すると、FP16は精度を犠牲にして記憶領域を半分にし、計算効率を向上させたもので、精度と効率のバランスが取れた、少し太めの目盛りのようなものである。
INT8は8ビットの整数型で、-128から127の範囲の整数のみを表すことができる。 INT8はメモリー占有率が非常に低く、計算速度が非常に速いという利点があるが、数値精度も最も低い。 INT8は整数だけをカウントする単純なカウンターに似ているが、高速で便利である。
2.2 定量的な目的
定量化の中心的な目的はモデルのストレージ要件と計算の複雑さを軽減同時に、精度の損失を許容範囲内に抑えることを目指す。具体的には、定量化は以下の目的を達成することを目指す:
ストレージ要件の削減現代のディープラーニングモデル、特にパラメータサイズが巨大なモデルは、数億から数千億のパラメータを持つことが多く、ストレージスペースを圧迫している。FP32モデルを例にとると、各パラメータは4バイトの記憶領域を占有する。このモデルをFP16に数値化すると、各パラメーターに必要なのはわずか2バイトとなり、必要なストレージ容量は半分になる。モデルをさらにINT8に数量化すると、各パラメーターは1バイトで済み、記憶容量は75%削減できます。
計算効率の向上定量化されたモデルは、推論段階での計算負荷が大幅に軽減されるため、推論速度が向上する。例えば、FP32モデルをGPU上で実行する場合、計算速度はメモリ帯域幅によって制限される可能性があります。一方、FP16やINT8モデルでは、ハードウェアが低精度計算のアクセラレーションを最適化しているため、計算速度を大幅に向上させることができます。量子化によってもたらされる性能向上は、エッジ・デバイスやモバイル・デバイスなど、計算リソースが限られているシナリオにおいて特に重要です。
消費電力の削減モデル・コンピューティング・リソース要件の削減は、エネルギー消費の削減に直結します。モバイル機器や組み込みシステムにとって、消費電力は重要な考慮事項です。定量化技術は、モデルの消費電力を効果的に削減し、デバイスの寿命を延ばし、放熱要件を削減することができます。
帯域幅の削減分散コンピューティングシステムでは、モデルサイズの縮小はデータ転送帯域幅の縮小を意味する。マルチサーバーシナリオでは、定量的モデルをより高速に分散・同期させることができるため、全体的なデータ転送効率が向上します。
3.INT4、INT8 定量化
3.1 INT4 と INT8 の表現範囲
INT4とINT8はどちらも、コンピュータシステムにおいてデータをバイナリ形式で保存する整数型の数値化手法であるが、数値表現の範囲と精度が異なる。
- INT8INT8は8ビットの整数型で、表現範囲は-128~127である。 これは8ビット・カウンターに例えることができ、各ビットは0か1のどちらかになり、異なる整数値は異なる0/1の組み合わせで表現できる。例えば記名 INT8は-128から127の範囲の中位を意味し、2進数の11111111は10進数の-1を意味する。 もしそれが符号なし(つまり、プラス記号やマイナス記号に関係なく絶対値) INT8は0から255までの範囲で、この場合11111111は10進数で255を表し、多くのアプリケーション・シナリオのニーズを満たすのに十分である。例えば、画像処理におけるピクセル値は通常0から255までの範囲であり、INT8で効果的に表現できる。
- INT4INT4は4ビットの整数型で、INT8よりも表現範囲が-8~7と小さい。 INT4は、数値範囲を犠牲にして、メモリフットプリントを小さくし、計算を高速化している。 INT4は、数値範囲は限定されているが、「フットプリント」が小さく、資源効率が高い、小さなカウンターのようなものである。よりリソース効率が高い。軽量なニューラル・ネットワークのレイヤーのような、精度の要求が比較的緩いアプリケーション・シナリオでは、INT4の数値化を使用することで、ストレージと計算コストを大幅に削減できます。例えば、軽量な画像分類モデルをモバイルで展開する場合、モデルパラメータと中間計算結果をINT4フォーマットで保存・計算することで、メモリフットプリントを削減し、推論を高速化することができる。
3.2 定量式とその例
量子化のプロセスは、基本的に高精度浮動小数点数マップから低精度整数への変換です。FP32からINT8への量子化を例にとると、量子化の式は以下のようになる:
は元の浮動小数点数である。
は量化された整数である。
はスケーリング係数で、浮動小数点数を整数範囲にマッピングするために使用される。
小数点以下を四捨五入することを示す。
結果がINT8の範囲、すなわち[-128, 127]に限定されることを示す。
スケーリングファクターの計算
スケール・ファクターは通常、浮動小数点数の絶対値の最大値として計算される。浮動小数点数の集合があると仮定すると、その手順は以下のようになる:
- 浮動小数点数のグループの最大絶対値を求める:
- スケーリングファクターを計算する: .
実際には、Max Quantization、Mean-Std Quantizationなど、スケーリングファクターを計算する方法がいくつかある。 Max Quantizationは、テンソルの最大絶対値を用いてスケーリング係数を計算するもので、実装は簡単ですが、外れ値の影響を受けやすいかもしれません。 Mean-Std Quantisationは、データの平均と標準偏差の情報を使用して、よりロバストな方法でスケーリングファクターを決定しますが、計算の複雑さが若干高くなります。適切なスケーリングファクター計算方法を選択するには、精度と計算オーバーヘッドのトレードオフが必要です。
典型例
浮動小数点数のセット[-0.5, 0.3, 1.2, -2.1]があると仮定して、以下は量子化プロセスのステップ・バイ・ステップのデモンストレーションである:
1.絶対値の最大値を計算する:
2.スケーリングファクターの計算:
3.各浮動小数点数を数値化する:
- 0.5の場合。
- 0.3の場合。
- 1.2の場合。
- 2.1について
最終的に定量化されたINT8表現は[-1, 1, 4, -7]である。
以上のステップを通じて、量子化技法が浮動小数点数をどのように整数に変換するかがよくわかる。量子化処理によって精度が低下することは避けられないが、スケーリングファクターを賢く選択することで、ストレージと計算コストを大幅に削減しながら、モデルのパフォーマンスレベルを最大化することができる。 量子化誤差をさらに低減するために、ゼロ点量子化を導入することもできます。 ゼロ点量子化では、量子化式にゼロ点オフセットを追加します。これにより、浮動小数点のゼロを整数のゼロに正確にマッピングできるようになり、特に活性化値にゼロが多数存在する場合に、量子化精度が向上します。
4.FP8、FP16、FP32の定量化
4.1 FP8、FP16、FP32 表現
FP8、FP16、FP32は、コンピュータに2進数形式で格納される浮動小数点数だが、ビット幅が異なるため、範囲と精度が異なる。
FP32
FP32は、標準的な32ビット浮動小数点フォーマットとして、以下の3つの部分から構成される:
- 符号ビット(1ビット)0は正の数、1は負の数を表す。
- 指数桁(8桁)これは、FP32 が非常に小さな値から非常に大きな値まで表現できるようにするためである。
- 下1桁(23ビット)末尾の桁数が多いほど高精度。
FP32は、塵のような小さなスケールから山のような広大な距離まで測定できる高精度の巻尺のようなものだ。 FP32は、科学計算や金融モデリングなど、高い精度が要求される分野では欠かせないデータ型である。
FP16

FP16は、FP32の半分の16ビットのメモリしか使用しない半精度浮動小数点フォーマットである:
- 符号ビット(1ビット)正の値と負の値を識別する。
- 指数桁(5桁)値の大きさの範囲を定義する。
- 下1桁(10桁)数値精度を決定する。
FP16は、FP32に比べ、目盛りが少し太い直定規のようなもので、精度は落ちるが、記憶容量や計算効率の面で有利である。 FP16は、高い計算速度とメモリ帯域幅を必要とするディープラーニングモデルのトレーニングと推論に一般的に使用されています。 特にGPUアクセラレーションシナリオでは、FP16はTensor Coreなどのハードウェアアクセラレーションユニットをフルに活用し、大幅な性能向上を達成することができる。
FP8
FP8は、主にディープラーニング(深層学習)の分野で使用されている低精度浮動小数点数フォーマットで、効率的な計算を目的としている:
- 符号ビット(1ビット)正の値と負の値を識別する。
- 指数桁(3桁または4桁): 値の大きさの範囲を定義する(FP8 のバリエーションが 2 つある)。
- 下1桁(4桁または3桁)数値精度(インデックスの桁数に相当)を決定する。
FP8の数値表現の範囲と精度はさらに低下するが、メモリフットプリントが小さく、計算速度が速いという利点がある。FP32が精密な巻き尺で、FP16が目盛りが少し太い直定規だとすると、FP8はより精密な巻き尺ということになる。 センチメートルの目盛りがついたシンプルな定規のようなものだ。加えて、測定範囲と精度はさらに低下するが、与えられた状況下で測定タスクを迅速に実行することはできる。 FP8は極めて精度の低いデータ型であるため、リアルタイム推論やエッジコンピューティングなど、極端なレイテンシとスループットが要求されるシナリオで大きな可能性を示す。 しかし、FP8を応用するとハードウェアやアルゴリズムに対する要求も高くなり、精度を確保するために特別なハードウェア・サポートや定量化ストラテジーが必要となる。
4.2 定量化のプロセスと計算式
量子化とは、高精度浮動小数点数を低精度浮動小数点数または整数に変換するプロセスである。FP32からFP16への量子化を例にとると、量子化の式は以下のようになる:
は元の浮動小数点数である。
は数値化された低精度浮動小数点数である。
はスケーリング係数で、浮動小数点数を低精度の範囲にマッピングするために使用される。
最も近い値への丸めを示す。
スケーリングファクターの計算
スケール・ファクターは通常、浮動小数点数の絶対値の最大値として計算される。浮動小数点数の集合があると仮定すると、その手順は以下のようになる:
- 浮動小数点数のグループの最大絶対値を求める:
- スケーリングファクターを計算: , はターゲット低精度フォーマットの最大値。絶対値で表すことができる.FP16の場合、この値はおよそ 65504.
INT8 定量化と同様に、FP16 定量化におけるスケーリング係数はさまざまな方法で計算することができ、さまざまな精度および性能要件に応じて選択することができる。 さらに、FP16 量子化は混合精度トレーニング(MPT)と併用されることが多い。 モデルの学習プロセスにおいて、FP16は計算量の多い演算(行列の乗算、畳み込みなど)に使用され、FP32はより高い精度が要求される演算(損失計算、勾配更新など)に使用されます。
典型例
FP32浮動小数点数のセット[-0.5, 0.3, 1.2, -2.1]があると仮定して、FP32をFP16に数値化する手順を以下に示す:
1.絶対値の最大値を計算する:
2.スケーリングファクターの計算:
3.各浮動小数点数を数値化する:
- 0.5の場合。
- 0.3の場合。
- 1.2の場合。
- 2.1について
最終的に定量化されたFP16は[-0.5, 0.3, 1.2, -2.1]で表される。
上記のステップを通して、量子化技術がどのように高精度浮動小数点数を低精度浮動小数点数に変換するかを観察することができます。数値化は確かに精度の低下をもたらしますが、スケーリング係数を賢く選択することで、ストレージと計算コストを削減しながら、モデルの性能をできる限り維持することができます。 FP16量子化の精度をさらに向上させるために、動的量子化を使用することができる。 動的量子化は、推論プロセス中に入力データの実際の範囲に応じてスケーリング係数を動的に調整することで、データ分布の変化にうまく適応し、量子化誤差を低減します。
5.定量的応用と利点
5.1 ディープラーニングへの応用
定量化技法はディープラーニングにおいて幅広い有望な応用があり、特にモデルの学習と推論の段階でその価値が高まっている。以下は、ディープラーニングにおける定量化技術の主な応用例である:
モデルトレーニングの加速
モデルのトレーニング段階では、FP16やFP8のような低精度データ型を使って計算することで、トレーニングプロセスを大幅に高速化することができます。例えば、NVIDIA HopperアーキテクチャGPUは、FP8精度でのTensor Core演算をサポートしています。FP8トレーニングは、従来のFP32トレーニングよりも2~3倍高速になります。このトレーニングの高速化は、パラメータ・サイズが大きいモデルにとって特に重要であり、トレーニング時間と計算リソースの消費を大幅に削減します。 例えば、GPT-3のような大規模な言語モデルを学習する場合、FP16またはBF16の混合精度学習を使用することで、学習時間を大幅に短縮し、計算リソースを大幅に節約することができます。
には インフレクションAI 例えば、Inflection-2は、5,000個のNVIDIA HopperアーキテクチャーGPUでFP8混合精度トレーニング戦略を使用してトレーニングされ、合計FLOPsの浮動小数点演算を行いました。Inflection-2は、多くの標準的なAI性能ベンチマークにおいて、同じくトレーニング計算カテゴリに属するGoogleのフラッグシップモデルPaLM 2よりも優れた性能優位性を示しました。多くの標準的な AI 性能ベンチマークにおいて、Inflection-2 は、同じトレーニング計算カテゴリに属する Google のフラッグシップモデル PaLM 2 を大幅に上回る性能を示しました。
モデル推論の最適化
モデルの推論段階において、量子化技術はモデルのストレージ要件と計算複雑度を大幅に削減し、推論効率を向上させることができる。例えば、FP32モデルをINT8に数値化することで、モデルのストレージ容量を75%削減し、推論速度を数倍に向上させることができる。これは、計算リソースやストレージ容量が限られていることが多いエッジデバイスやモバイルデバイスにディープラーニングモデルを展開する上で非常に重要です。 例えば、携帯電話上で画像認識モデルを展開する場合、モデルをINT8として定量化することで、モデルサイズを効果的に縮小し、メモリ消費量を削減し、推論速度を高速化し、ユーザーエクスペリエンスを向上させることができる。
例えば、GoogleはNVIDIAチームと緊密に協力し、TensorRT-LLM最適化技術をGemmaモデルに適用し、FP8テクノロジーと組み合わせて推論アクセラレーションを実現しました。実験結果によると、推論にHopper GPUを使用した場合、FP8はFP16と比較して3倍以上のスループット向上を達成しています。
モデルの圧縮と展開
定量化技術はモデルの圧縮と展開にも使用できます。高精度モデルを低精度モデルに定量化することで、モデルサイズを効果的に縮小することができ、リソースに制約のある環境でのモデル展開が可能になります。例えば、ゼロイチ用いる NVIDIAのハードウェアとソフトウェアを組み合わせた技術スタックは、大規模モデルFP8のトレーニングと検証を完了し、BF16と比較して大規模モデルのトレーニングスループットが1.3倍向上しました。 INT8やFP16/FP8の量子化だけでなく、INT4や、BNN(Binary Neural Network)やTNN(Ternary Neural Network)のようなさらに低ビットの量子化手法もあります。 これらの超低ビット量子化手法は、モデルを極限まで圧縮することができますが、通常は精度が大きく損なわれるため、モデルのサイズと速度に極端な要求があるシナリオに適しています。
さらに、定量化されたモデルは、特定のハードウェアアクセラレーション技術の助けを借りて、さらに強化することができる。例えば、NVIDIA 変圧器 エンジンは、PyTorch、JAX、PaddlePaddleなどの主流のディープラーニングフレームワークに統合されており、定量的モデルの推論をハードウェアレベルで効率的にサポートしている。 NVIDIA GPUに加え、ARMアーキテクチャのCPUやモバイルNPUなど、他のハードウェアプラットフォームも定量計算用に最適化・高速化されており、定量モデルを広く展開するためのハードウェア基盤を提供しています。
5.2 長所と限界
ゆうせい
計算効率の向上FP16とFP8は、FP32に比べて計算スループットが数倍高い。この高速化効果は、大規模モデルの学習と推論において特に顕著である。
より低い保管条件定量化技術により、モデルのストレージ容量を大幅に削減することができます。例えば、FP32モデルをINT8に数値化することで、ストレージ容量を75%削減することができます。
消費電力の削減: 低精度コンピューティングは、より少ない計算資源を必要とするため、デバイスの消費電力を削減します。モバイル機器や組込みシステムでは、消費電力は重要な設計上の考慮事項です。定量化されたモデルは、デバイスのバッテリ寿命を延ばし、放熱要件を低減するのに役立ちます。
モデルの最適化定量化技術は、学習と推論におけるモデルの最適化と圧縮を促進し、展開コストをさらに削減します。例えば、FP8を適用することで、モデルはトレーニング段階でより洗練された定量化ストラテジーを探索できるようになり、モデルの全体的な効率が向上する。
制限
精度の低下これは、特に非常に精度の低いフォーマット(FP8など)を使用する場合に顕著であり、与えられたタスクにおけるモデルの性能低下につながる可能性があります。精度の低下は、スケーリング係数を注意深く選択するなどの手段によってある程度軽減することができますが、精度の低下を完全になくすことはしばしば困難です。 量子化による精度低下を軽減するために、量子化を考慮した学習(Quantization-Aware Training:QAT)を利用することができる。 QATは、モデルの学習過程で量子化操作をシミュレートし、量子化誤差を考慮に入れて学習することで、量子化に対してよりロバストなモデルを学習する。 QATは通常、定量化モデルの精度を大幅に向上させることができますが、トレーニングコストはそれに応じて増加します。
ハードウェア・サポートすべてのハードウェア・プラットフォームが低精度計算を完全にサポートしているわけではありません。例えば、FP8やFP16の計算には特定のハードウェア(NVIDIA HopperアーキテクチャGPUなど)が必要になることが多い。ハードウェア・プラットフォームが低精度計算に最適化されていない場合、量子化の利点は十分に発揮されません。 低精度コンピューティングの普及に伴い、FP16、BF16、さらにはFP8といった低精度データ型をサポートするハードウェア・プラットフォームが増え始めている。
複雑性の増大定量化プロセスそのものが、モデル開発を複雑化させる可能性がある。例えば、定量化プロセスでは、スケーリン グ係数のきめ細かな計算が必要となり、モデルの追加的なキャリブレーションや微調整が必要となる場合がある。これはモデル開発と展開の難易度を確実に高める。 定量化展開の複雑さを軽減するために、NVIDIA TensorRTやQualcomm AI Engineなど、多くの自動定量化ツールやプラットフォームが業界に登場しており、開発者が迅速かつ容易に定量化し、ターゲットとなるハードウェアプラットフォームにモデルを展開できるようになっている。
アプリケーションシナリオ量子化技術はすべての応用シナリオに適しているわけではない。非常に高い精度を必要とするタスク(科学計算、金融モデリングなど)では、量子化は許容できない精度の損失につながる可能性があります。 精度を重視するタスクの場合、精度と効率のバランスを取るために、モデル内の異なるレイヤーやパラメータに異なる定量化精度を適用する、例えば主要なレイヤーやパラメータにはFP32やFP16、その他のレイヤーやパラメータにはINT8以下の精度を適用する、混合精度定量化戦略を試すことができる。
要約すると、ディープラーニング分野のキーテクノロジーである量子化技術は、計算効率の向上、ストレージ要件の削減、消費電力の削減において大きな可能性を示している。しかし、定量化技術には、精度の低下やハードウェア依存性などの限界もある。したがって、実用的なアプリケーションでは、モデルの性能と効率の最適なバランスを達成するために、特定のアプリケーション要件とシナリオ特性に従って定量化戦略を慎重に選択する必要があります。 今後、ハードウェアとアルゴリズムの絶え間ない発展により、定量的技術はディープラーニングの分野でより重要な役割を果たし、より幅広いシーンでの人工知能の応用を促進し、根付かせるだろう。
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事



コメントはありません