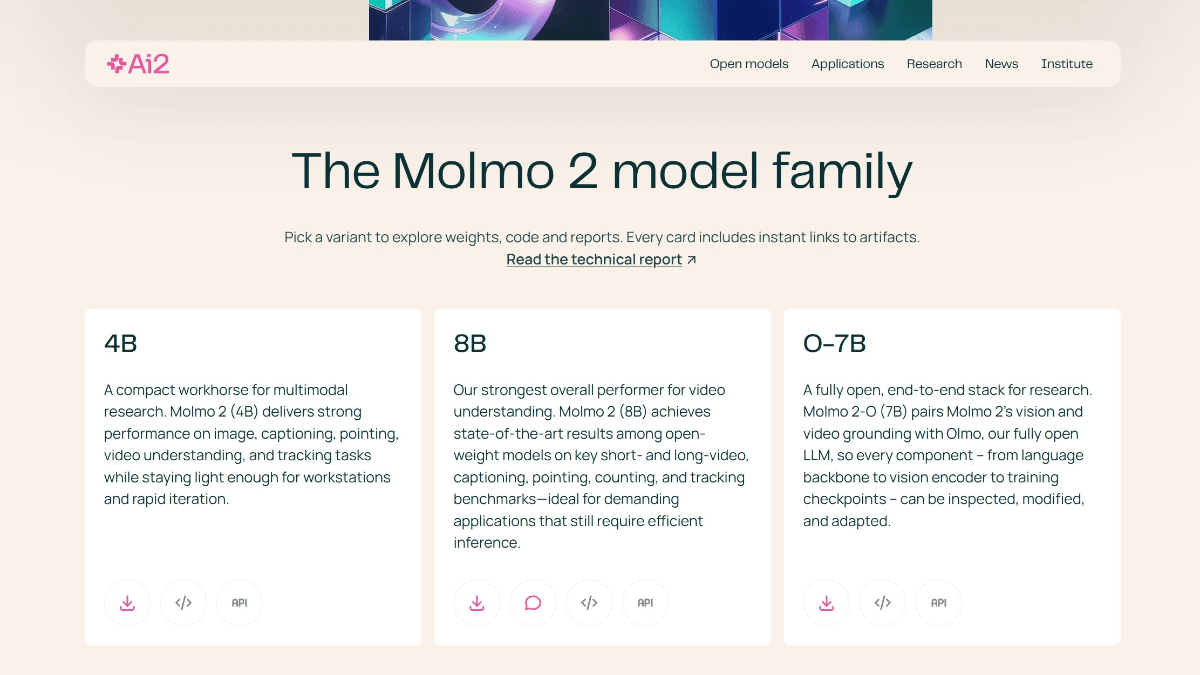
MLX-Audio: AppleのMLXフレームワークをベースにした音声合成ツール

はじめに
MLX-Audioは、AppleのMLXフレームワーク上で開発されたオープンソースツールで、音声合成(TTS)と音声合成(STS)機能に重点を置いています。MシリーズチップなどのApple Siliconのコンピューティングパワーを活用し、効率的で高速な音声合成ソリューションを提供します。テキストを自然で滑らかな音声に変換することも、既存の音声をもとに新しい音声を生成することも、MLX-Audioはすべて行うことができる。GitHubユーザーのBlaizzy(カヌマ王子)によって開発されたこのツールは、開発者、研究者、個人ユーザーに、macOS上で動作する高性能な音声生成オプションを提供することを目的としている。オープンソースのプロジェクトであるため、ユーザーは自由にダウンロード、修正、コードの提供が可能であり、ローカライズされた音声処理を必要とするアプリケーションシナリオに最適である。
機能一覧
- 音声合成 (TTS)入力されたテキストを素早く自然な音声に変換します。
- 音声対音声(STS)既存の音声サンプルに基づいて新しい音声コンテンツを生成します。
- 効率的な推論Apple Silicon用に最適化され、高速なスピーチ生成パフォーマンスを提供します。
- マルチモデル対応様々なニーズに対応するため、事前にトレーニングされた様々な音声合成モデルをサポートしています。
- オープンソースのカスタマイズ完全なソースコードが提供され、ユーザーは必要に応じて機能を調整したり、モデルを最適化することができます。
- ローカルオペレーションクラウドに依存することなく、個人所有の端末ですべての操作を行えるため、プライバシーが保護される。
ヘルプの使用
設置プロセス
MLX-AudioはPythonベースのツールで、GitHubリポジトリからのコードと必要なPythonライブラリに依存する簡単なインストールプロセスです。詳しいインストール手順は以下の通りです:
- 環境への準備
- システム要件:macOS(M1、M2などのMシリーズチップを搭載したデバイスに推奨)。
- Python 3.8以降をインストールする(Homebrewを推奨):
brew install python). - Gitをインストールする(リポジトリの複製用):
brew install git.
- クローンMLX-オーディオウェアハウス
ターミナルを開き、以下のコマンドを入力してソースコードをダウンロードする:git clone https://github.com/Blaizzy/mlx-audio.git
ダウンロードが完了したら、プロジェクト・ディレクトリに移動する:
cd mlx-audio
- 依存関係のインストール
プロジェクトは通常requirements.txtファイルに必要なPythonライブラリがリストされています。以下のコマンドを実行してインストールしてください:pip install -r requirements.txtこのファイルがない場合は、公式のREADMEを参照されたい。
mlx(アップルの機械学習フレームワーク)や、以下のようなオーディオ処理ライブラリだ。numpyもしかしたらsoundfile. - インストールの確認
インストールが完了したら、簡単なテストコマンドを実行して、環境が正しく設定されていることを確認する:python -m mlx_audio.tts.generate --text "Hello, world"成功すれば、生成されたスピーチを聞くか、カレントディレクトリにオーディオファイルが生成されます。
MLX-Audioの使い方
MLX-Audioでは、コマンドラインインターフェース(CLI)とPythonスクリプトの2つの使用方法があり、以下に主な機能の操作の流れを詳しく説明します。
音声合成 (TTS)
これは、テキストを音声に変換するMLX-Audioの中核機能です。
- 手続き::
- 準備したテキスト例:"Hello, welcome to MLX-Audio experience"(こんにちは、MLX-Audio体験へようこそ)。
- コマンド実行ターミナルに入力してください:
python -m mlx_audio.tts.generate --text "你好,欢迎体验 MLX-Audio" --output "welcome.wav"--text入力テキストを指定します。--output出力オーディオファイルの名前を指定します(オプション、デフォルトではカレントディレクトリに生成されます)。
- 検査結果: コマンド実行後、生成されたオーディオファイル(例えば
welcome.wav)がカレントディレクトリに保存され、プレーヤーで開いて音声を聞くことができます。
- 高度なオプション::
- モデルの指定:複数のモデルがサポートされている場合、それらは
--model例えばパラメータ選択:python -m mlx_audio.tts.generate --text "Hello" --model "model_name" - スピーチのスピードやピッチの調整:READMEやコードの説明によっては、追加のパラメーターがサポートされている場合があります(例:以下のようなもの)。
--speedもしかしたら--pitch)、実現によって異なる。
- モデルの指定:複数のモデルがサポートされている場合、それらは
音声対音声(STS)
この機能により、ユーザーは既存の音声に基づいて新しい音声コンテンツを生成することができる。
- 手続き::
- 入力音声の準備WAV形式のオーディオ・ファイル(例えば、以下のようなもの)があることを確認してください。
input.wav)を携帯電話で録画したり、他の情報源から入手することができる。 - コマンド実行次のコマンドを入力してください:
python -m mlx_audio.sts.generate --input "input.wav" --output "output.wav"--input入力音声ファイルのパスを指定します。--output出力ファイルのパスを指定する。
- 検査結果として保存されます。
output.wavその効果をプレーヤーで確認することができます。
- 入力音声の準備WAV形式のオーディオ・ファイル(例えば、以下のようなもの)があることを確認してください。
- ほら::
- 入力音声の質は出力に影響しますので、クリアな録音をお勧めします。
- 生成されたコンテンツをカスタマイズする必要がある場合、追加のパラメータが必要になることがあります。
カスタム開発
MLX-Audioはオープンソースのプロジェクトであるため、ユーザーはより多くの機能を実現するためにコードを変更することができます。
- 動く::
- プロジェクトフォルダーを開き、テキストエディタ(VS Codeなど)を使って
mlx_audioディレクトリ内のPythonファイル。 - 新しい音声モデルの追加や生成ロジックの調整など、必要に応じてコードを修正する。
- 保存してテストを実行する:
python your_script.py
- プロジェクトフォルダーを開き、テキストエディタ(VS Codeなど)を使って
機能操作プロセスの詳細
高速スピーチ生成
- 取るツールの効果をすぐに試したい。
- ワークフロー::
- ターミナルを開き
mlx-audioカタログ - 簡単なTTSコマンドを入力する:
python -m mlx_audio.tts.generate --text "测试语音生成" - 数秒待つと(テキストの長さとデバイスの性能によります)、オーディオファイルが自動的に生成されます。
- ターミナルを開き
- 結局デフォルトの名前のオーディオファイルを生成します。
output.wav)、直接再生すればいい。
長いテキストの処理
- 取る記事を音声に変換する必要がある。
- ワークフロー::
- テキストをファイルとして保存する。
text.txt)、内容は複数の段落になることもある。 - コマンドを使ってファイルを読み込む:
python -m mlx_audio.tts.generate --file "text.txt" --output "article.wav"--fileテキストファイルのパスを指定する(プロジェクトがこのパラメータをサポートしていることを確認する。サポートしていない場合は、Pythonスクリプトでファイルを読み込んで呼び出す)。
- 生成された
article.wav声が自然で流暢であることを保証する。
- テキストをファイルとして保存する。
バッチ生成
- 取る複数のテキストの音声を生成する必要があります。
- ワークフロー::
- 簡単なPythonスクリプトを書く。
batch_generate.py):from mlx_audio.tts import generate texts = ["文本1", "文本2", "文本3"] for i, text in enumerate(texts): generate(text=text, output=f"output_{i}.wav") - スクリプトを実行する:
python batch_generate.py - 複数のオーディオファイルが生成されていないかチェックする。
- 簡単なPythonスクリプトを書く。
チップ
- パフォーマンス最適化M-Seriesシリコンデバイスで実行する場合は、最適な速度を得るために、他の高負荷タスクがリソースを占有していないことを確認してください。
- デバッグの問題エラーが発生した場合は(依存関係が見つからないなど)、ターミナルの出力を確認し、プロンプトに従って不足しているライブラリをインストールしてください。
- 地域支援機能が明確でない場合は、GitHubにIssueを提出するか、既存のディスカッションをご覧ください。
これらのステップにより、ユーザーは簡単な音声生成から複雑なアプリケーションの開発まで、MLX-Audioを簡単に使い始めることができます。
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事


コメントはありません