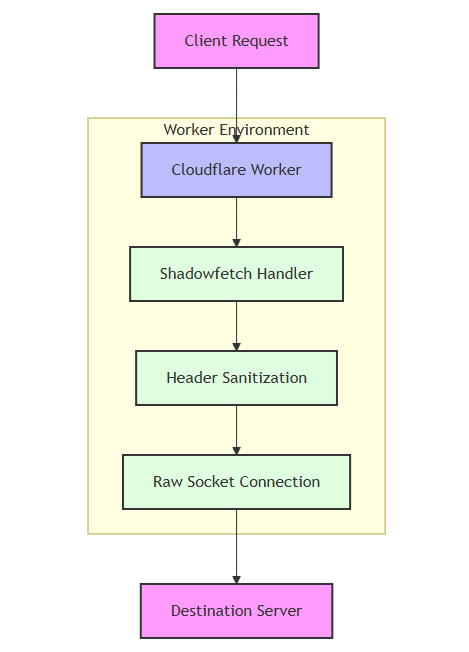
ミストラルOCR:94.89%総合精度、1000ページ/30秒、わずか1ドル

人類の文明の長い歴史の中で、情報の取得・分析方法が飛躍的に進歩するたびに、社会の進歩に大きく貢献してきた。古代の象形文字から、持ち運び可能なパピルス、その後の印刷機の出現、そして今日のデジタル化の波に至るまで、技術革新のひとつひとつが人類の知識の普及範囲とその応用の深さを大きく広げ、ひいては新たな技術革新の肥沃な土壌となってきた。
今日、私たちは、デジタル化された膨大な情報の可能性を解き放つ前例のない機会を得た、エキサイティングな転換点にいる。 業界のデータによると、約90%の組織データがいまだに文書として保存されており、そこにはまだ利用されていない膨大な情報価値が含まれている。これらの眠っているデータ資産を解き放つために、ミストラルAIは ミストラルOCRこれは光学式である。 キャラクター Recognition(光学式文字認識)APIが登場し、文書理解技術が新たなレベルに達した。
Mistral OCRの主な利点
ミストラル 単なる OCR ツールではなく、OCR はドキュメントの理解方法における完全な革命を意味します。市場に出回っている他の OCR モデルと比較して、Mistral OCR は文書の認識と精度が高く、画像、テキスト、表、数式など、文書のあらゆる構成要素を理解することができます。ユーザーは画像や PDF 文書をアップロードするだけで、構造化されたコンテンツが素早く抽出され、グラフィカルで整理された方法で表示されます。
まとめると、Mistral OCRにはいくつかの重要な利点がある:
- 複雑な文書を理解するグラフィックス、複雑な数式、表、LaTeXのような高度なフォーマットが混在するドキュメントを正確に解析します。
- ネイティブの多言語およびマルチモーダル対応追加設定なしで多言語・多モダルのドキュメントを処理する能力を備えています。
- 優れたパフォーマンス指標Mistral OCRは、多くの権威あるベンチマークでトップにランクされています。
- 高速処理Mistral OCRは、このクラスのOCR製品の中で最速の処理速度を誇ります。
- 構造化されたアウトプットを備えた革新的な「プロンプトとしてのドキュメント」モデル文書全体をプロンプトコマンドとしてサポートし、高度に構造化されたデータ結果を出力することができます。
- 柔軟でオプションのあるセルフホスト・ソリューションMistral OCRは、究極のデータセキュリティを求める企業向けに、オプションでセルフホスト型の導入オプションを提供しています。
このような大きな利点を持つ Mistral OCR は、以下を構築するための完璧なソリューションです。 ラグ Mistral OCR は、RAG(Retrieval-Augmented Generation)システム、特にスライドや複雑な PDF ファイルなど、情報量の多いマルチモーダル文書を扱う場合に最適です。現在、ミストラル OCR は ミストラルAI ショーの主役 ル・シャット 強力な文書理解力を数百万人のユーザーに提供する会話AIプラットフォーム採用 apiバージョン ミストラル-ocr-最新 バッチ推論モデルを使用する場合は、さらに費用対効果が高くなります。開発者はMistral AI Developer Platformからすぐに始めることができます。 ラ・プラットフォーム Mistral OCR のパワーを体験してください。将来的には、Mistral OCRはMistral AIのクラウドサービスやパートナーネットワークを通じてより広く展開され、ローカライズされた企業展開をサポートする予定です。
次に、Mistral OCR の核となる技術的な利点を分析し、API を通して Mistral OCR を素早く使い始める方法をご紹介します。
ミストラルOCRのコア・ベネフィット
複雑な文書を深く理解する
Mistral OCR は、その高度なモデルアーキテクチャと学習戦略により、複雑な文書の理解に優れています。Mistral OCR は、グラフィックスが挿入された文書、専門的な数式や高度な表を多数含む学術論文、LaTeX のような複雑な組版システムで作成された文書を正確に解析することができます。図表、グラフ、数式、画像などが散りばめられた情報密度の高い科学論文の場合でも、Mistral OCR は文書の根底にある論理と情報を理解することができます。
Mistral OCR のパワーをより直感的に体験していただくために、Mistral AI チームは特別なデモケースを用意しました。典型的な PDF ドキュメントを Mistral OCR に入力すると、モデルはそこからすべてのテキストと画像情報を抽出し、元のテキストの構造と内容を完全に保持したまま、効率的に Markdown 形式のファイルに変換することに成功しました。興味のある開発者は コラボ・ノート そのプロセスを自分で体験してみよう。
実際のアプリケーションにおける Mistral OCR の文書解析効果をより明確に示すため、Mistral AI チームは多数の PDF 文書とそれに対応する OCR 結果の比較も入念に用意しました。ユーザーは簡単なスライド操作で、元の文書と OCR 結果を自由に切り替えることができ、さまざまな複雑な文書に対応する Mistral OCR の優れた性能を直感的に感じることができます。
テーブル+グラフィック

OCRの結果

フォーミュラ

OCRの結果

ヒンディー語

OCRの結果

通常文書

OCRの結果

アラビア語

OCRの結果

パフォーマンス・ベンチマークにおける優れたパフォーマンス
Mistral OCR の性能レベルを完全に評価するために、Mistral AI チームは一連の厳密なベンチマークテストを実施しました。その結果、Mistral OCR は多くの主要な指標において、市場にある他の主要な OCR モデルを大幅に上回っていることが明らかになりました。特に注目すべきは、Mistral OCR が文書から埋め込まれた画像を正確に抽出する能力に優れていることです。これは現在比較されている他の大規模言語モデル(LLM)では利用できない機能です。公正な評価を行うため、Mistral AI チームは「テキストのみ」のテストセットも社内で作成し、各モデルのベンチマークに使用しました。このテストセットは、モデルの実世界でのパフォーマンスを包括的かつ客観的に見ることができるように、出版された論文やインターネットから入手したPDFを幅広くカバーしています。
以下はベンチマーク結果の詳細データである:
| モデリング | 総合成績 | 数式認識 | 多言語サポート | スキャン文書の認識 | フォーム認識 |
|---|---|---|---|---|---|
| グーグル ドキュメントAI | 83.42 | 80.29 | 86.42 | 92.77 | 78.16 |
| アジュールOCR | 89.52 | 85.72 | 87.52 | 94.65 | 89.52 |
| ジェミニ-1.5-Flash-002 | 90.23 | 89.11 | 86.76 | 94.87 | 90.48 |
| ジェミニ-1.5-Pro-002 | 89.92 | 88.48 | 86.33 | 96.15 | 89.71 |
| ジェミニ-2.0-フラッシュ-001 | 88.69 | 84.18 | 85.80 | 95.11 | 91.46 |
| GTPT-4O-2024-11-20 | 89.77 | 87.55 | 86.00 | 94.58 | 91.70 |
| ミストラル OCR 2503 | 94.89 | 94.29 | 89.55 | 98.96 | 96.12 |
上記のデータから明らかなように、ミストラルOCRはすべての主要業績指標、特に総合成績とフォーム認識において、大きなリーダーシップを発揮している。
ネイティブの多言語処理機能
Mistral AI の開発当初から、グローバルユーザーへのサービスは重要な開発目標でした。そのため、強力な多言語処理能力を構築することは、Mistral AI 製品開発の中核戦略の一つであり、Mistral OCR は、数千もの異なるテキスト、フォント、言語をシームレスに解析し、正確に理解し、効率的に転記することで、この点で新境地を開拓し、あらゆる大陸の言語と文化を包括的にカバーしています。この優れた多言語適応性は、異なる言語地域の文書を扱うグローバルな事業を展開する多国籍企業や、特定の言語市場に焦点を当て、местныйユーザーにサービスを提供するローカリゼーション企業にとって戦略的に重要です。
次の表は、多言語ファジーマッチ生成タスクにおけるMistral OCRのベンチマーク結果です:
| モデリング | ファジィ・マッチングの生成精度 |
|---|---|
| グーグル-ドキュメント-AI | 95.88% |
| ジェミニ-2.0-フラッシュ-001 | 96.53% |
| アジュールOCR | 97.31% |
| ミストラル OCR 2503 | 99.02% |
テストデータによると、ミストラルOCRは多言語のファジーマッチ生成でも優れた性能を発揮し、その性能指標は他の主流OCR製品を上回っており、その強力な多言語処理能力を改めて裏付けています。
異なる言語におけるMistral OCRの性能を評価するため、Mistral AIチームはさらに詳細な言語別ベンチマークテストも実施しました:
| 多言語主義 | アジュールOCR | グーグルドックAI | ジェミニ-2.0-フラッシュ-001 | ミストラル OCR 2503 |
|---|---|---|---|---|
| ロシア語(ru) | 97.35% | 95.56% | 96.58% | 99.09% |
| フランス語 | 97.50% | 96.36 | 97.06% | 99.20% |
| ヒンディー語 | 96.45% | 95.65 | 94.99% | 97.55% |
| 中国語(zh) | 91.40% | 90.89% | 91.85% | 97.11% |
| ポルトガル語 (pt) | 97.96% | 96.24 | 97.25% | 99.42% |
| ドイツ語 (de) | 98.39% | 97.09% | 97.19 | 99.51% |
| スペイン語 (es) | 98.54% | 97.52 | 97.75 | 99.54% |
| トルコ語(tr) | 95.91% | 93.85 | 94.66% | 97.00% |
| ウクライナ語 | 97.81% | 96.24 | 96.70% | 99.29% |
| イタリア語 | 98.31% | 97.69 | 97.68 | 99.42% |
| ルーマニア語(ro) | 96.45% | 95.14 | 95.88% | 98.79% |
サブ言語テストの結果から、ミストラルOCRは様々な言語の認識精度で高いパフォーマンスを示しており、特に中国語の認識ではミストラルOCRの優位性は明らかです。
極めて高速な文書処理能力
Mistral OCR の軽量設計は、優れたパフォーマンスの追求と相まって、競合製品よりもはるかに高速です。標準的なシングルノード構成では、Mistral OCR は毎分最大 2000 ページを処理できます。この驚異的な文書処理速度は、大量の文書処理を必要とする高負荷のアプリケーションシナリオでも効率的なシステム運用を保証し、継続的な学習とパフォーマンスの最適化をサポートします。
「ドキュメント・アズ・プロンプトと構造化出力
ミストラルOCRのもう一つの革新的な特徴は、次のようなものだ。 「プロンプトとしての文書 モデル。 この機能により、ユーザーはより強力で正確な情報抽出のために、プロンプト入力として文書全体を直接モデル化することができます。ユーザーは Mistral OCR に、文書から特定の情報を抽出し、JSON などの事前に定義されたフォーマットで構造化データを出力するよう指示することができます。この構造化された出力は、下流のアプリケーションやワークフローとの統合を容易にします。例えば、ユーザーは抽出されたデータを直接関数呼び出しやインテリジェントエージェントの構築に使用することができます。 ノートブックの例 これにより、ユーザーは「プロンプトとしての文書」機能をすぐに使い始めることができる。
柔軟なセルフホスト・デプロイメント・オプション
Mistral OCR は、一部の企業や組織が極めて厳格なデータプライバシーとセキュリティの要件を持っているという事実を認識し、セルフホスト型の導入オプションを提供しています。セルフホスト型の導入オプションを選択された方は、Mistral OCR を完全に自社のインフラストラクチャ上に導入することができ、すべての機密データや機密情報が常に自社の安全な管理された環境で取り扱われ、最も厳しい規制コンプライアンスやデータセキュリティ基準を満たすことができます。セルフホストデプロイメントをお考えの組織の方は、お気軽に Mistral AI までお問い合わせください。
Mistral OCR API を使い始める
Mistral OCR APIは非常に使いやすく、Mistral AIはPythonとTypescriptでSDKを提供し、開発者がすぐに統合できるようにcurlリクエストのサンプルも提供しています。
ドキュメントOCRプロセッサ
Mistral OCRのコア機能は、ドキュメントOCRプロセッサーによって駆動されます。このプロセッサーは、Mistral AIの最新OCRモデルであるmistral-ocr-latestに基づいて構築されており、PDFドキュメントからテキストと構造化コンテンツを正確に抽出します。
主な特徴::
- 構造化コンテンツ抽出テキストコンテンツを抽出する際、ドキュメントの元の構造や階層関係はそのまま保持されます。
- フォーマットされた情報の保持見出し、段落、リスト、表など、文書内のさまざまな書式情報を正確に認識し、保持する能力。
- マークダウン形式の出力結果は、二次的な解析とレンダリングのために、クリーンで使いやすいMarkdownフォーマットで表示されます。
- 複雑なレイアウト処理マルチカラムのテキストや混合コンテンツの組版など、さまざまな複雑なドキュメントレイアウトを簡単に処理できます。
- 高精度・大規模加工高い認識精度を確保しながら、大量文書のバッチ処理に対応。
- 幅広い文書フォーマットをサポートPDF、画像、ユーザーがアップロードした文書など、複数の入力形式をサポートしています。
ドキュメントOCRプロセッサは、抽出されたテキストコンテンツを返すだけでなく、ドキュメントの構造に関するメタデータも含んでいるため、開発者は認識されたドキュメントコンテンツをプログラムで簡単に操作することができます。
PDF文書OCR
以下のコード例は、Mistral OCR API を使って PDF 文書を処理する方法を示しています:
import os
from mistralai import Mistral
api_key = os.environ["MISTRAL_API_KEY"]
client = Mistral(api_key=api_key)
ocr_response = client.ocr.process(
model="mistral-ocr-latest",
document={
"type":"document_url",
"document_url":"https://arxiv.org/pdf/2201.04234"
},
include_image_base64=True
)
OCRのためにPDF文書をアップロードする
Mistral OCR API は、OCR 処理のために PDF ファイルをアップロードすることもサポートしています。
ファイルのアップロード
まず、PDFファイルをMistral AIのファイルサービスにアップロードする必要があります:
from mistralai import Mistral
import os
api_key = os.environ["MISTRAL_API_KEY"]
client = Mistral(api_key=api_key)
uploaded_pdf = client.files.upload(
file={
"file_name":"uploaded_file.pdf",
"content":open("uploaded_file.pdf","rb"),
},
purpose="ocr"
)
文書検索
アップロードに成功すると、アップロードされたファイルに関する情報を取得できます:
client.files.retrieve(file_id=uploaded_pdf.id)
id='00edaf84-95b0-45db-8f83-f71138491f23' object='file' size_bytes=3749788 created_at=1741023462 filename='uploaded_file.pdf' purpose='ocr' sample_type='ocr_input' source='upload' deleted=False num_lines=None
署名URLの取得
アップロードされたファイルに安全にアクセスするには、ファイルの署名URLを取得することができます:
signed_url = client.files.get_signed_url(file_id=uploaded_pdf.id)
OCR結果の取得
最後に、アップロードされたPDFファイルのOCR結果を取得するには、署名URLをドキュメントアドレスとして使用します:
import os
from mistralai import Mistral
api_key = os.environ["MISTRAL_API_KEY"]
client = Mistral(api_key=api_key)
ocr_response = client.ocr.process(
model="mistral-ocr-latest",
document={
"type":"document_url",
"document_url": signed_url.url,
}
)
画像OCR
Mistral OCR API は、画像の直接 OCR もサポートしています。
URL画像OCR
OCR認識は、画像のURLから直接実行できます:
import os
from mistralai import Mistral
api_key = os.environ["MISTRAL_API_KEY"]
client = Mistral(api_key=api_key)
ocr_response = client.ocr.process(
model="mistral-ocr-latest",
document={
"type":"image_url",
"image_url":"https://media-cldnry.s-nbcnews.com/image/upload/t_fit-560w,f_avif,q_auto:eco,dpr_2/rockcms/2023-11/short-quotes-swl-231117-02-33d404.jpg"
}
)
Base64エンコードされた画像OCR
あるいは、画像をBase64エンコードして、OCR認識用のAPIに渡すこともできる:
import base64
import requests
import os
from mistralai import Mistral
defencode_image(image_path):
"""Encode the image to base64."""
try:
withopen(image_path,"rb")as image_file:
return base64.b64encode(image_file.read()).decode('utf-8')
except FileNotFoundError:
print(f"Error: The file {image_path} was not found.")
returnNone
except Exception as e:# Added general exception handling
print(f"Error: {e}")
returnNone
# Path to your image
image_path ="path_to_your_image.jpg"
# Getting the base64 string
base64_image = encode_image(image_path)
api_key = os.environ["MISTRAL_API_KEY"]
client = Mistral(api_key=api_key)
ocr_response = client.ocr.process(
model="mistral-ocr-latest",
document={
"type":"image_url",
"image_url":f"data:image/jpeg;base64,{base64_image}"
}
)
ドキュメント理解機能
Mistral OCR の文書理解機能は、強力な OCR テクノロジーと大規模言語モデリング(LLM)を深く統合した革新的なアプリケーションです。自然言語で文書コンテンツと対話する能力をユーザーに提供し、自然言語による質問を通して、文書から情報や洞察を効率的に引き出すことができます。
文書理解のワークフローは、主に次の2つのステップで構成されます。::
- ファイル処理まず、構造化されていない文書は、OCR技術によって文書内のテキスト、構造、書式情報を抽出し、機械可読形式に変換されます。
- 言語モデル理解大規模言語モデルは、抽出された文書内容の詳細な分析と理解を提供します。ユーザは自然言語で質問や情報要求を行うことができ、モデルは文書の文脈や本質的な関連性を理解し、文書内容に基づいて正確な回答を与える。
文書理解のためのキー・コンピテンシー::
- 文書内容に基づくQ&A文書の特定の内容に関する自然言語の質問に答えることができる。
- 情報抽出と要約文書から重要な情報を抽出し、簡潔な要約を作成します。
- 文書分析と洞察潜在的な洞察や知識を発見するために、文書の内容を詳細に分析する。
- 複数文書の照会と比較複数の文書にまたがる情報照会と内容比較をサポート。
- コンテキストを意識した対応より正確で適切な回答ができるようになる。
ドキュメント理解のための代表的なアプリケーションシナリオ::
- 科学論文や技術文書の分析大量の科学論文や技術文書を迅速に分析・理解。
- ビジネス文書情報抽出契約書や報告書などのドキュメントから重要な情報を効率的に抽出します。
- 法的文書作成および契約処理複雑な法律文書や契約条項の処理と分析を支援する。
- ドキュメントクイズアプリの構築情報検索の効率化を目指した知的文書質問応答システムの開発。
- 文書ワークフローの自動化文書レビューや情報入力など、文書ベースのさまざまなワークフローを自動化します。
次のコード例は、自然言語を使ってPDF文書と対話し、文書の最後の文が何かを尋ねる方法を示しています:
import os
from mistralai import Mistral
# Retrieve the API key from environment variables
api_key = os.environ["MISTRAL_API_KEY"]
# Specify model
model ="mistral-small-latest"
# Initialize the Mistral client
client = Mistral(api_key=api_key)
# Define the messages for the chat
messages =[
{
"role":"user",
"content":[
{
"type":"text",
"text":"what is the last sentence in the document"
},
{
"type":"document_url",
"document_url":"https://arxiv.org/pdf/1805.04770"
}
]
}
]
# Get the chat response
chat_response = client.chat.complete(
model=model,
messages=messages
)
# Print the content of the response
print(chat_response.choices[0].message.content)
# Output:
# The last sentence in the document is:\n\n\"Zaremba, W., Sutskever, I., and Vinyals, O. Recurrent neural network regularization. arXiv:1409.2329, 2014.
アプリケーション事例
Mistral OCR の強力な文書理解機能は、さまざまな業界の実際のアプリケーションで大きな価値を引き出し、企業や組織が大量の文書データを実用的な知識やソリューションに変換するのに役立っています。現在、Mistral OCR は以下の主要分野で大きな成果を上げています:
研究のデジタル変革数多くのトップクラスの研究機関が、Mistral OCRを使って大量の科学論文やジャーナルをAIに適したデータ形式に変換し、さまざまな下流のインテリジェント分析エンジンへのシームレスなアクセスを可能にする実験を始めています。これにより、研究コラボレーションの効率が大幅に向上し、研究ワークフローが大幅に加速されました。
文化遺産のデジタル保存と伝達多くの文化遺産保護団体や非営利団体が、貴重な歴史的文書や遺物をデジタル化して永久保存し、文化遺産を広く普及・共有するために、ミストラルOCR技術を積極的に採用しています。
顧客サービスのインテリジェントなアップグレード顧客サービス部門もミストラルOCRの応用を積極的に模索しており、複雑な製品マニュアルやユーザーマニュアルを構造化されたインデックス可能な知識ベースに変換することで、顧客対応時間を大幅に短縮し、顧客サービスの質とユーザー満足度を向上させようとしている。
業界を超えた文学のためのAIイネーブルメントMistral OCRは、様々な業種の企業が、大量の技術文書、エンジニアリング図面、강의メモ、プレゼンテーション、規制当局への提出書類などを、インデックスを付けて検索可能なAIフレンドリーなフォーマットに変換し、文書に埋め込まれた知識やインテリジェンスを活用することで、組織の生産性を向上させるのに役立っています。
今すぐMistral OCRのパワーを体験してください!
今すぐ Mistral OCR のパワーを体験してください!Mistral OCR の文書理解機能は、Le Chat プラットフォームで無料で体験できます。Mistral AI チームは、ユーザーからの貴重なフィードバックを楽しみにしており、Mistral OCR モデルの最適化と性能向上のための反復作業を続けていきます。戦略的パートナーシップ・プログラムの一環として、Mistral AI は特定のユーザー向けにローカル展開オプションも提供しています。
その他のリソース
Mistral OCR の使用方法や高度なヒントについては、以下のリソースをご参照ください:
- ツール使用と文書理解クックブック: https://colab.research.google.com/github/mistralai/cookbook/blob/main/mistral/ocr/document_understanding.ipynb
- バッチOCRクックブック: https://colab.research.google.com/github/mistralai/cookbook/blob/main/mistral/ocr/batch_ocr.ipynb
- 構造化OCRクックブック: https://colab.research.google.com/github/mistralai/cookbook/blob/main/mistral/ocr/structured_ocr.ipynb
これらのクックブックでは、開発者が Mistral OCR の機能をより深く理解し、応用できるように、詳細なコードサンプルとハンズオンガイドを提供しています。
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事


コメントはありません