
MiniMax-M1 - MiniMaxのオープンソース推論モデル

MiniMax-M1とは
MiniMax-M1はMiniMaxチームによるオープンソースの推論モデルで、Mixed Expert Architecture(MoE)とLightning Attentionメカニズムの組み合わせに基づいており、総パラメータ数は4560億。このモデルは100万 トークン MiniMax-M1は長いコンテキストの入力と80,000トークンの出力を持ち、長い文書や複雑な推論タスクに適しています。miniMax-M1は、ソフトウェアエンジニアリング、長いコンテキストの理解、ツールの使用などのタスクにおいて、いくつかのオープンソースモデルを凌駕しています。このモデルの効率的な計算能力とロバストな推論能力により、次世代の言語モデリングエージェントの強力な基盤となります。

MiniMax-M1の主な特長
- ロングコンテクスト処理最大100万トークンの入力と8万トークンの出力をサポートし、長い文書、長いレポート、学術論文、その他の長いテキストコンテンツを効率的に処理することができ、複雑な推論タスクに適しています。
- 効率的な推論計算リソースの割り当てを最適化し、推論コストを削減し、高いパフォーマンスを維持するために、40Kと80Kの2種類の推論バジェットを提供。
- 多分野にわたるタスクの最適化数学的推論、ソフトウェア工学、長い文脈の理解、ツールの使用などのタスクに優れています。
- 関数呼び出し構造化された関数呼び出しをサポートし、外部関数呼び出しパラメータを識別して出力することができます。
ミニマックス-M1の性能
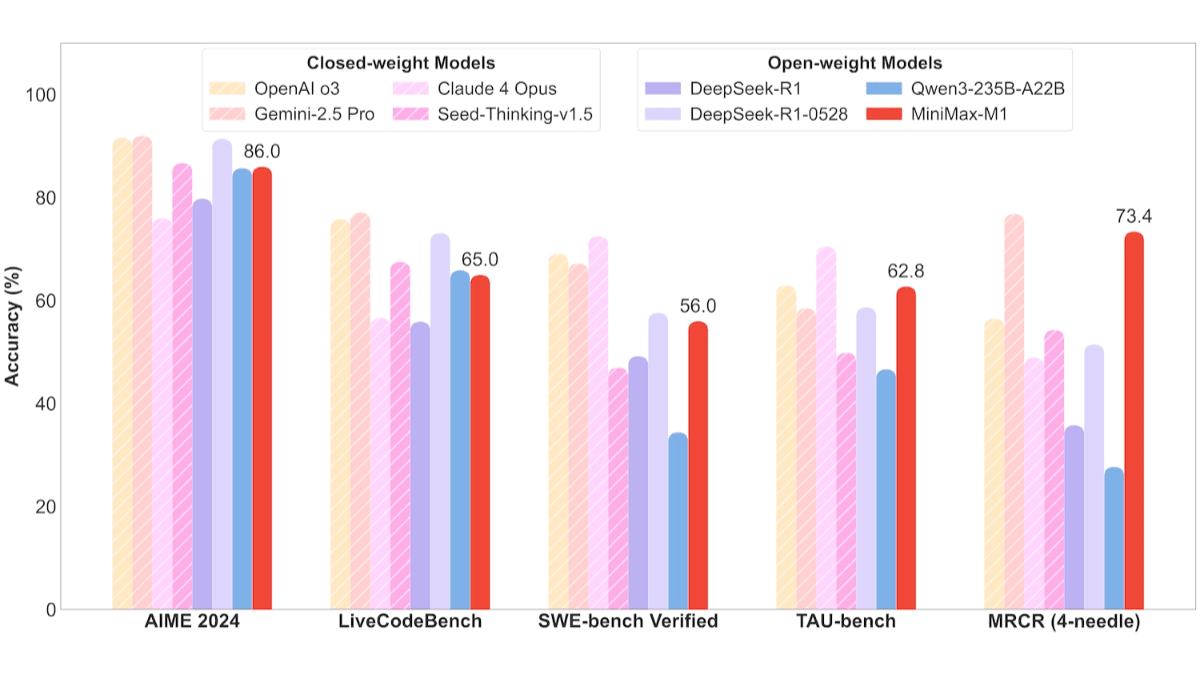
- ソフトウェア・エンジニアリング業務SWE-benchベンチマークでは、MiniMax-M1-40kが55.6%、MiniMax-M1-80kが56.0%を達成し、DeepSeek-R1-0528の57.6%にわずかに及ばず、他のオープンソースモデルを大きく上回りました。
- 長い文脈理解課題MiniMax-M1は、何百万ものコンテキストウィンドウに依存しており、長時間のコンテキスト理解タスクにおいて、すべてのオープンソースモデルを凌駕し、OpenAI o3やClaude 4 Opusを上回り、Gemini 2.5 Proに次いで世界第2位となりました。
- ツール使用シナリオTAUベンチテストでは、MiniMax-M1-40kがGemini-2.5 Proを上回り、すべてのオープンソースモデルをリードしました。
MiniMax-M1の公式ホームページアドレス
- GitHubリポジトリ::https://github.com/MiniMax-AI/MiniMax-M1
- HuggingFaceモデルライブラリ::https://huggingface.co/collections/MiniMaxAI/minimax-m1
- 技術論文::https://github.com/MiniMax-AI/MiniMax-M1/blob/main/MiniMax_M1_tech_report.pdf
MiniMax-M1の使い方
- APIコール::
- 公式ウェブサイトを見るミニマックスへ 公式サイトアカウントに登録し、ログインしてください。
- APIキーの取得パーソナルセンターまたはデベロッパーページでAPIキーをリクエストしてください。
- APIの使用公式のAPIドキュメントに従って、HTTPリクエストに基づいてモデルを呼び出します。例えば、Pythonのrequestsライブラリを使ってリクエストを送信します:
import requests
url = "https://api.minimax.cn/v1/chat/completions"
headers = {
"Authorization": "Bearer YOUR_API_KEY",
"Content-Type": "application/json"
}
data = {
"model": "MiniMax-M1",
"messages": [
{"role": "user", "content": "请生成一段关于人工智能的介绍。"}
]
}
response = requests.post(url, headers=headers, json=data)
print(response.json())- ハグする顔の使い方::
- ハギング・フェイス・ライブラリのインストールトランスフォーマーやトーチなどの依存関係がインストールされていることを確認する。
pip install transformers torch- 積載モデルHugging Face HubからMiniMax-M1モデルをロードします。
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "MiniMaxAI/MiniMax-M1"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
input_text = "请生成一段关于人工智能的介绍。"
inputs = tokenizer(input_text, return_tensors="pt")
output = model.generate(**inputs, max_length=100)
print(tokenizer.decode(output[0], skip_special_tokens=True))- ミニマックスアプリまたはウェブで使用::
- ウェブへのアクセスMiniMax Webサイトにログインし、ページ上で質問やタスクを入力すると、モデルが直接答えを生成します。
- アプリをダウンロード携帯電話にMiniMax APPをダウンロードし、同様の操作を行ってください。
MiniMax-M1の製品価格
- APIコールの推論コスト価格::
- 0-32k 入力長::
- 投入コスト0.8ドル/100万トークン。
- 出力コストトークンは8ドル/ミリオン。
- 32k-128k 入力長::
- 投入コストトークン120万ドル
- 出力コスト100万トークンあたり16ドル。
- 128k-1M 入力長::
- 投入コストトークン:240ドル/ミリオン
- 出力コスト100万トークンあたり24ドル。
- 0-32k 入力長::
- APPとウェブ::
- 利用無料MiniMax APPとウェブは無制限の無料アクセスを提供し、一般ユーザーや技術的背景を持たないユーザーに適しています。
MiniMax-M1コアの利点
- ロングコンテクスト処理能力最大100万トークンの入力と最大8万トークンの出力をサポートしており、長い文書や複雑な推論タスクの処理に適している。
- 効率的な推論パフォーマンス計算資源を最適化し、推論コストを削減するために、40Kと80Kの2つの推論バジェットバージョンを、ライトニングアテンションメカニズムと組み合わせて提供する。
- 多分野にわたるタスクの最適化ソフトウェア・エンジニアリング、長い文脈の理解、数学的推論、ツールの使用など、多様なアプリケーション・シナリオに適応する能力に優れています。
- 先進技術アーキテクチャハイブリッドエキスパートアーキテクチャ(MoE)と大規模強化学習(RL)トレーニングに基づき、計算効率とモデル性能を向上。
- 高品質・低価格柔軟な価格戦略を提供し、APPとウェブへの無料アクセスを提供することで、利用への障壁を低くしている。
MiniMax-M1の対象者
- 開発者ソフトウェア開発者は、コード生成、コード構造の最適化、プログラムのデバッグ、コードドキュメントの自動生成などを効率的に行うことができます。
- 研究者・学者長い学術論文を処理し、文献レビューや複雑なデータ分析を行い、モデルを使ってアイデアを素早く整理し、報告書を作成し、調査結果を要約する。
- コンテンツクリエーターMiniMax-M1は、長編コンテンツの作成に必要な人たちが、アイデアを出したり、ストーリーのアウトラインを書いたり、テキストを修正したり、長編小説を作成したりする際に使用します。
- 学童明確な解決策を提供し、執筆をサポートする。
- ビジネスユーザー企業は、インテリジェント・カスタマー・サービス、データ分析ツール、ビジネス・プロセス・オートメーションなどの自動化ソリューションにそれらを統合する。
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事



コメントはありません