Ming-UniAudio - Antオープンソースユニファイドオーディオマルチモーダル生成モデル

Ming-UniAudioとは?
Ming-UniAudioは、Ant Groupのオープンソース統合音声マルチモーダル生成モデルであり、テキスト、音声、画像、動画の混合入出力をサポートします。マルチスケールトランスフォーマとミックスドエキスパート(MoE)アーキテクチャを採用し、モダリティを意識したルーティング機構によってクロスモーダル情報を効率的に扱い、計算効率を大幅に向上させます。このモデルは、音声合成、声紋クローニング、多方言生成、音声とテキストのクロスモーダルタスクで優れた性能を発揮し、高品質なリアルタイム生成が可能である。オープンソースの特徴は、マルチモーダル技術の開発と実用化イノベーションを促進するために、研究コミュニティにスケーラブルなソリューションを提供する。
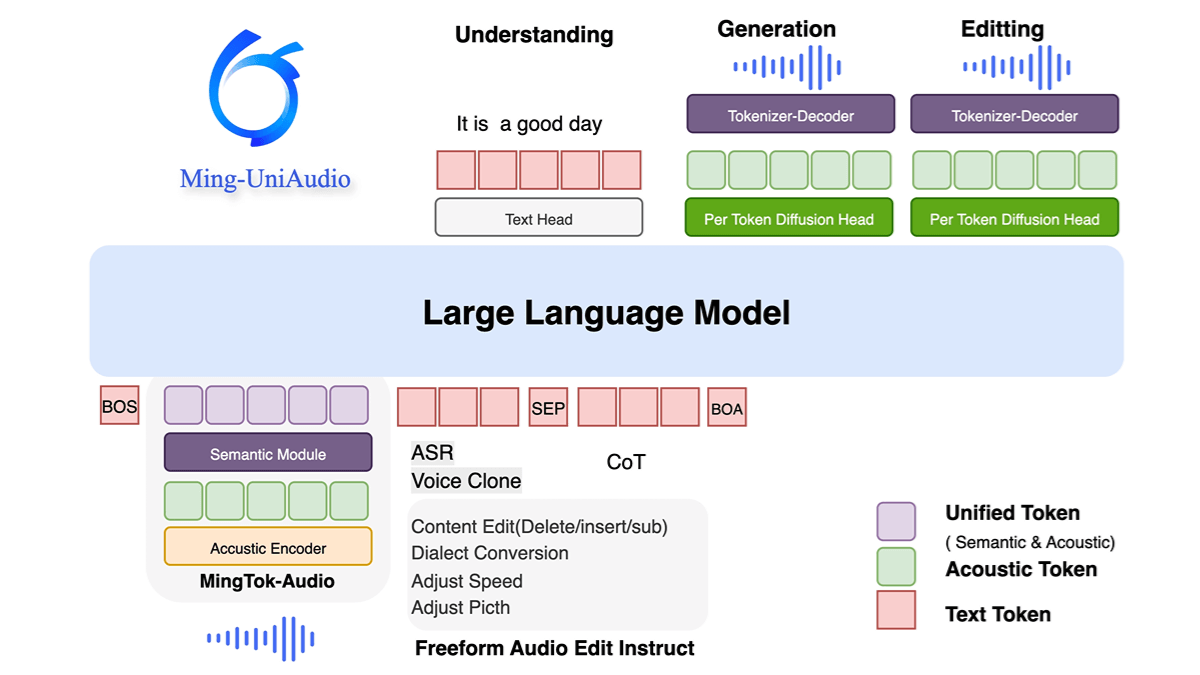
明・ユニオーディオの特徴
- 統一されたマルチモーダル処理音声、テキスト、画像、ビデオの混合入力と生成をサポートし、モダリティを超えた統一的なモデリングとインタラクションを実現します。
- エンド・ツー・エンドの音声合成とクローニング高品質の音声生成、多方言のクローン作成、パーソナライズされた声紋のカスタマイズ。
- マルチミッション合同訓練LLMと組み合わせた離散シーケンスのトークン化により、複数の音声タイプを処理。
- 効率的なコンピューティング・アーキテクチャマルチスケールトランスフォーマー構造の採用により、コーデック設計を最適化し、発電効率と品質を向上。
Ming-UniAudioの核となる利点
- 統一されたマルチモーダル処理能力音声、テキスト、画像、ビデオの混合入力と生成をサポートし、複数の独立したモデルに依存することなく、単一のモデルを通じてモダリティを超えた統一されたモデリングとインタラクションを可能にします。
- 効率的なコンピューティング・アーキテクチャマルチスケールトランスフォーマーとMoE(Mixed Expert)設計は、モーダル特有のルーティングメカニズムと組み合わされ、計算効率とリソースの利用を大幅に改善する。
- 高品質の音声合成とクローニング統合された高度な音声デコーダーは、多方言の音声生成、パーソナライズされた声紋のカスタマイズ、リアルタイム応答をサポートし、音声の自然さと適応性に優れています。
- マルチタスク協調最適化離散シーケンス・トークナイゼーションと段階的学習ストラテジーにより、知覚タスクと生成タスクを同時に最適化し、音声理解やテキスト生成などのベンチマークテストでトップレベルに到達。
- オープンソースとスケーラビリティ完全にオープンなコードとモデル・ウェイトは、コミュニティにおける更なる研究開発をサポートし、マルチモーダル技術とアプリケーション・イノベーションの普及を促進する。
Ming-UniAudioの公式ウェブサイトは?
- プロジェクトのウェブサイト:: https://xqacmer.github.io/Ming-Unitok-Audio.github.io/
- Githubリポジトリ:: https://github.com/inclusionAI/Ming-UniAudio
- HuggingFaceモデルライブラリ:: https://huggingface.co/inclusionAI/Ming-UniAudio-16B-A3B
明・ユニオーディオが向いている人
- AI研究開発者音声、テキスト、画像、ビデオのハイブリッド処理と生成タスクには、統一されたマルチモーダルモデルが必要である。
- 音声技術アプリケーター音声合成、音声クローン、多方言生成に焦点を当てる。
- マルチモーダル製品チーム知覚能力と生成能力を実世界のアプリケーションに統合するために、効率的なコンピューティングアーキテクチャとオープンソースソリューションを求めています。
- コンピューティング・リソースの最適化要求者モデルの効率性についての懸念、リソースの利用を改善するためのモーダルルーティングメカニズムとMoEの使用の必要性。
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事


コメントはありません