
MinerU2.5 - 上海AI研究所と北京大学のオープンソース文書解析モデル

MinerU2.5とは?
MinerU2.5は、上海人工知能研究所と北京大学のチームによって共同開発された、高解像度の文書画像解析を効率的に処理することに重点を置いた非連成視覚言語モデルである。第一段階では、低解像度のサムネイルから文書の構造と読み順を素早く特定し、第二段階では、本来の解像度にトリミングした後、重要な領域を正確に認識する。このモデルはわずか1.2Bだが、8K文書でも高い精度を維持することができ、シングルカードRTX 4090の処理速度の測定値は最大2.12ページ/秒と、類似のソリューションよりも大幅に優れている。独自性は、OTSL中間言語によるHTMLシーケンス長の圧縮や、長い数式構造のイリュージョンの問題を解決する原子数式分解・再編成技術など、表や数式などの複雑な要素の特別な最適化にも反映されている。
MinerU2.5の特徴
- 効率的な2段構文解析アーキテクチャ第一段階は、ダウンサンプリングされた画像のグローバルレイアウトを分析し、文書内のテキストブロック、表、数式、その他の構造要素を迅速に特定することである。第二段階は、計算オーバーヘッドと細部の保持のバランスを効果的にとるために、高解像度領域の細粒度のコンテンツをネイティブ解像度でのみ特定することである。
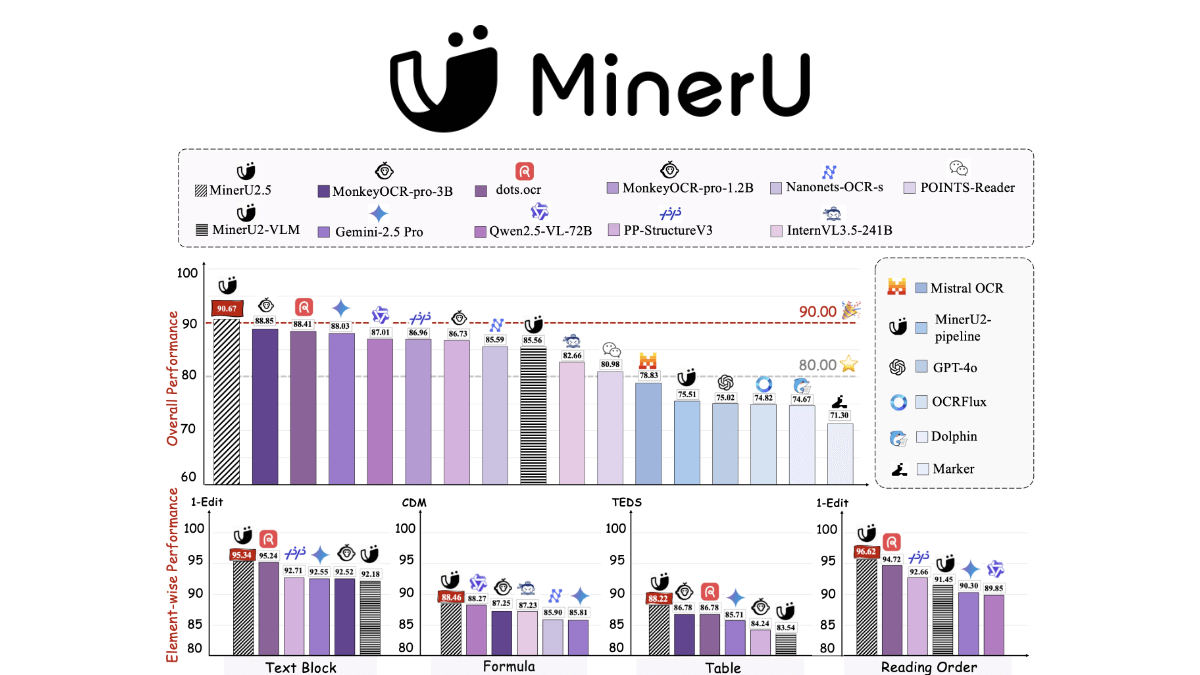
- 優れた精度と性能パラメータ数は1.2Bに過ぎないが、OmniDocBenchやolmOCR-benchなどの権威あるベンチマークにおける総合的な構文解析精度は、OmniDocBenchやolmOCR-benchを上回っている。 ジェミニ 2.5 Pro、GPT-4o、Qwen2.5-VL-72Bなどのトップレベルの汎用マルチモーダル・マクロモデルや、dots.ocrやMonkeyOCRなどのプロフェッショナルな文書解析ツールを大きくリードしています。
- 複雑なシーンに対応する強力な能力マルチモーダル融合アーキテクチャにより、テキスト認識と視覚レイアウト分析を深く統合し、表行の欠落、傾いたテキスト、複雑な数式など、従来のOCRが失敗するシナリオに効果的に対処することができます。その性能は、複数カラムのレイアウト、イラストの干渉、ファジー歪み、低解像度スキャンなどの過酷な条件下でも安定しており、中国語、英語、日本語、韓国語など20以上の言語の混合配列認識をサポートしています。
- 極めて実用的で効率的な展開このモデルは小型で統合が容易であり、RTX 3090や4090のようなコンシューマー向けグラフィックカードで1.7~2ページ/秒の高速構文解析を実現しているため、RAG(検索機能拡張世代)知識ベース構築や大規模文書抽出のような実世界での展開に理想的である。
- 構造化されたアウトプットによる包括的なタスクサポートレイアウト解析:レイアウト解析をマルチタスク問題に革新的に再構築し、1回の推論で文書要素の位置、カテゴリー、回転角度、読み順を同時に予測。Markdown、JSON、その他の構造化フォーマットへの解析結果の出力をサポートし、その後の処理やアプリケーションに利用できます。
MinerU2.5の主な利点
- 高度な2段階構文解析アーキテクチャデカップリング戦略が採用されており、第一段階では、ダウンサンプリングされた画像に対して効率的なグローバルレイアウト解析を行い、文書構造要素を特定する。第二段階では、ネイティブ解像度の高解像度領域に対してきめ細かなコンテンツ認識を行い、計算オーバーヘッドと詳細保持のバランスを効果的にとる。
- 優れたパフォーマンスOmniDocBench、olmOCR-benchおよびその他の権威あるベンチマークにおいて、その包括的な構文解析精度は、Gemini 2.5 Pro、GPT-4o、Qwen2.5-VL-72Bなどのトップクラスの一般的なマルチモーダルラージモデルを包括的に上回り、dots.ocr、MonkeyOCR、PP-などの専門的な文書構文解析ツールにも大きく勝っています。StructureV3などの専門的な文書解析ツールを大きく引き離しています。
- 強化されたマルチタスク・パラダイムレイアウト解析をマルチタスク問題として再定義することで、文書要素の位置、カテゴリ、回転角度、読み順を同時に予測し、回転した要素の解析などの複雑な課題を効果的に解決します。
- 極めて実用的で効率的このモデルは小型で統合が容易であり、民生用グラフィックスカードで毎秒1.7ページの高速構文解析を実現できる。これは、RAG(Retrieval Augmented Generation)知識ベース構築、大規模文書抽出などの実用的な応用シナリオに最適である。
MinerU2.5公式ウェブサイトとは何ですか?
- HuggingFaceモデルライブラリ:: https://huggingface.co/opendatalab/MinerU2.5-2509-1.2B
- arXivテクニカルペーパー:: https://arxiv.org/pdf/2509.22186
MinerU2.5の対象者
- 企業デジタル化・知識管理チーム大量の契約書、報告書、アーカイブ、その他の紙文書をデジタル化するタスクに対処する必要がある企業に適しており、スキャン文書、PDF、その他の非構造化データのライブラリへの解析を効率的に完了し、RAG(Retrieval Augmented Generation)知識ベースの構築効率を大幅に向上させることができます。
- 開発者とAIエンジニアリングチームこのモデルは完全にオープンソースで、リファレンスサイズが小さく(1.2B)、コンシューマー向けグラフィックスカード(RTX 4090など)での展開をサポートしており、大規模なクローズドソースAPIに依存することなく、高性能なOCR機能を製品に統合したいと考えている開発者やエンジニアリングチームに最適です。
- 研究機関および学界文書理解、マルチモーダル・マクロモデリングなどの学術研究のための強力なオープンソースのベースラインモデルを提供します。
- 金融、法律、政府機関MinerU2.5は、多数の複雑な構造のフォーム、契約書、帳票を処理する必要がある複雑な組版やフォーム行の欠落があるシナリオで優れた性能を発揮し、高精度の構造化情報抽出の厳しい要件を満たします。
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事


コメントはありません