MiMo-VL - シャオミのオープンソース・マルチモーダルモデル

MiMo-VLとは
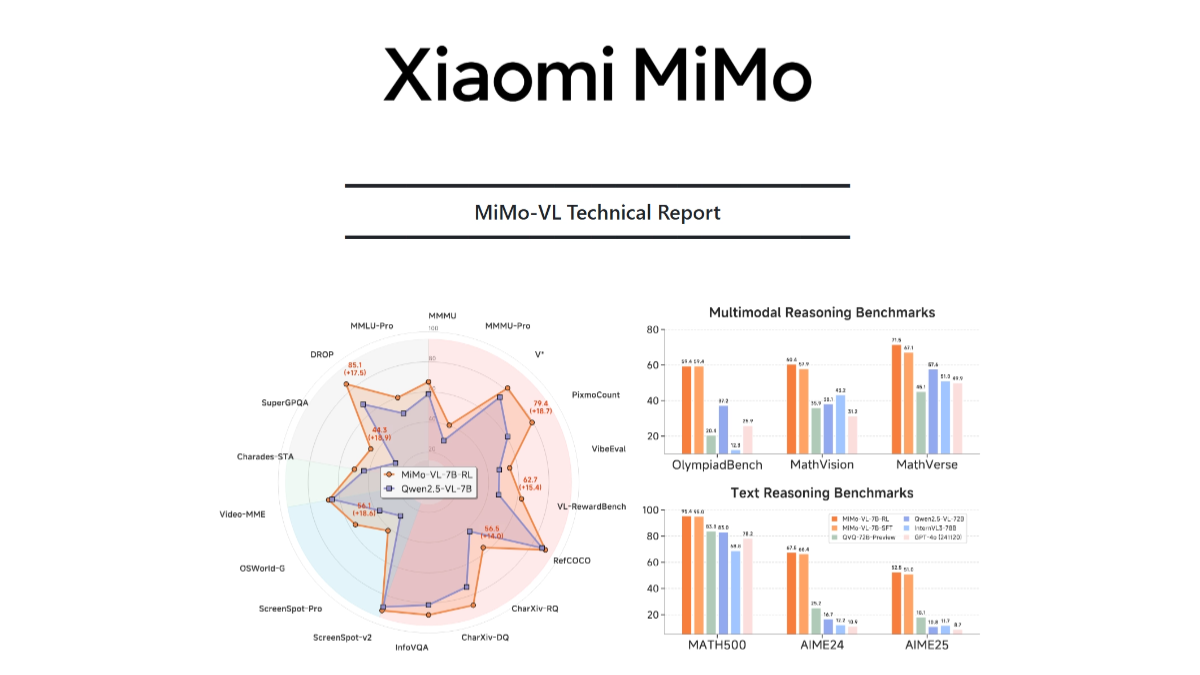
MiMo-VLはシャオミのオープンソースのマルチモーダルグランドモデルで、視覚コーダー、クロスモーダル投影レイヤー、言語モデルで構成されている。視覚コーダーはQwen2.5-ViTに基づいており、ネイティブ解像度の入力をサポートし、より詳細な情報を保持する。言語モデルはシャオミが独自に開発したMiMo-7Bで、複雑な推論に最適化されている。言語モデルはシャオミが独自に開発したMiMo-7Bで、複雑な推論に最適化されている。モデルは多段階の事前学習戦略に基づいており、画像とテキストのペア、ビデオとテキストのペア、GUI操作シーケンスなどのデータタイプをカバーする2.4Tトークンのマルチモーダルデータで学習される。MiMo-VLは、複雑な画像推論、GUIインタラクション、ビデオ理解、長い文書の構文解析において優れた性能を発揮し、例えば、MMMU-valでは66.7%を達成し、Gemma 3 27Bを上回った。OlympiadBenchで59.4%を達成し、72Bモデルを上回った。
MiMo-VLの主な特徴
- 複雑な絵の推理とクイズ複雑な絵の内容を正確に理解し、合理的な説明と回答をする。
- GUIの操作とインタラクション複雑な命令を理解し実行するために、最大10ステップ以上のGUI操作をサポート。
- ビデオと言語理解ビデオの内容を理解し、言語と連動した推論やクイズを行う。
- 長文文書の解析と推論複雑な推論と情報抽出のための長い文書の処理。
- ユーザー・エクスペリエンスの最適化ハイブリッドオンライン強化学習に基づく推論、知覚性能、ユーザーエクスペリエンスの向上。
MiMo-VL公式サイトアドレス
- Githubリポジトリ::https://github.com/XiaomiMiMo/MiMo-VL
- HuggingFaceモデルライブラリ::https://huggingface.co/collections/XiaomiMiMo/mimo-vl
- 技術論文::https://github.com/XiaomiMiMo/MiMo-VL/blob/main/MiMo-VL-Technical-Report
MiMo-VLの使い方
- ハギング・フェイス・プラットフォーム::
- ハギング・フェイス・モデル・ライブラリーへのアクセスMiMo-VLへのアクセスハグ顔モデルライブラリーページ。
- 積載モデルHugging FaceのPythonライブラリを使用してMiMo-VLモデルをロードします。例
from transformers import AutoModelForVision2Seq, AutoProcessor
model = AutoModelForVision2Seq.from_pretrained("XiaomiMiMo/mimo-vl")
processor = AutoProcessor.from_pretrained("XiaomiMiMo/mimo-vl")- 入力データの処理画像、動画、テキストなどの入力データは、プロセッサによって前処理されます。
- 出力の生成処理されたデータをモデルに入力し、モデルの出力を得る。
- GitHubリポジトリ::
- GitHubリポジトリのクローンアクセスGitHubリポジトリその場合、リポジトリをローカルにクローンする。
git clone https://github.com/XiaomiMiMo/MiMo-VL.git- 依存関係のインストール: リポジトリのrequirements.txtファイルに従って、必要なPythonの依存関係をインストールします。
pip install -r requirements.txt- 実行コードサンプルコードを実行したり、アプリケーションを開くには、リポジトリの指示に従ってください。
MiMo-VLの核となる利点
- 強力なマルチモーダル融合能力画像、ビデオ、テキストなどのマルチモーダルデータを処理し、複雑なシナリオを理解する。
- 優れた推論パフォーマンスMMMU-valで66.71 TP3T、OlympiadBenchで59.41 TP3Tなど、いくつかのベンチマークで優れた性能を発揮。
- ユーザー・エクスペリエンスの最適化混合オンライン強化学習(MORL)に基づき、ユーザーのフィードバックに基づいてモデルの動作を動的に調整し、ユーザー体験を向上させます。
- 幅広いアプリケーション・シナリオスマート接客、スマートホーム、科学研究など様々な分野に応用可能。
- オープンソースとコミュニティ・サポート開発者の研究開発を促進するため、オープンソース・コードとコミュニティ・サポートを提供する。
MiMo-VLの対象者
- AI研究者マルチモーダル融合、複雑な推論、視覚、言語理解の分野の研究に重点を置く。
- 開発者とエンジニアスマート接客、スマートホーム、スマートヘルスケアなどのスマートアプリケーションの開発には、マルチモーダル機能の統合が必要です。
- データサイエンティストモデル性能とデータ処理効率を向上させるために、マルチモーダルデータを処理・分析する。
- 教育者と学生例:数学の問題解決、プログラミング学習など。
- 医療関係者診断の効率と精度を向上させるため、医用画像の解析と文章理解を支援する。
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事


コメントはありません