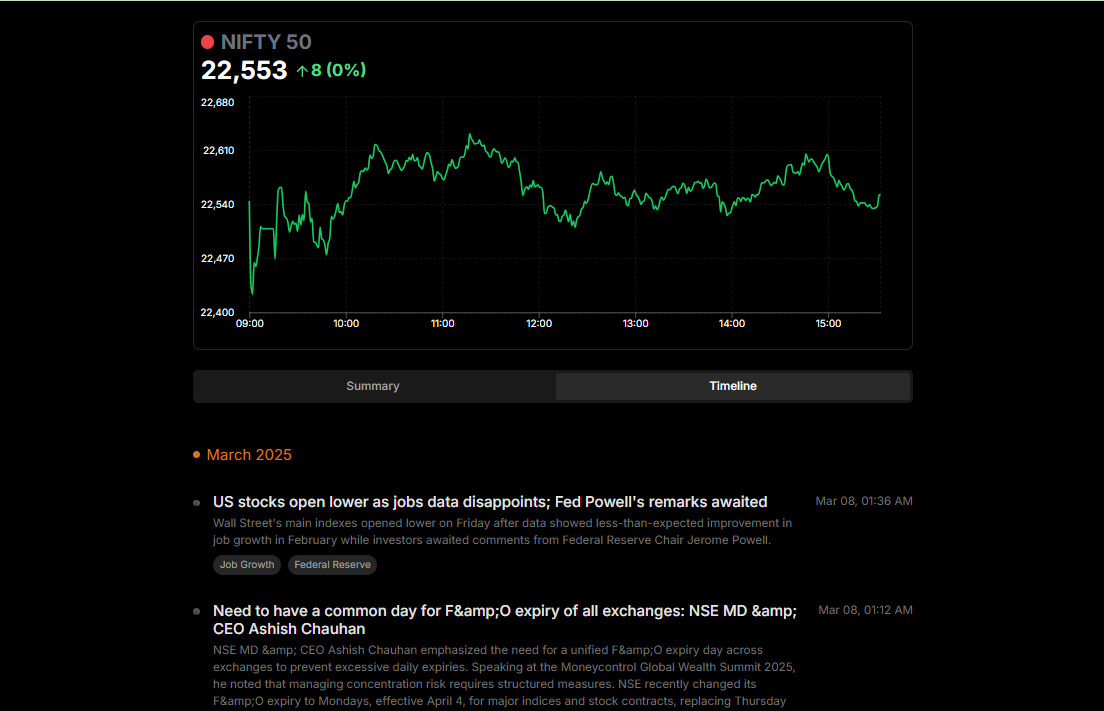
MiMo-V2-TTS - 小米推出的自研语音合成大模型

MiMo-V2-TTS是什么
MiMo-V2-TTS是小米推出的自研语音合成大模型,与MiMo-V2-Pro、MiMo-V2-Omni共同构成小米面向"Agent时代"的三大基础模型矩阵。模型基于自研Audio Tokenizer和多码本语音-文本联合建模架构,经过上亿小时语音数据的大规模预训练与多维度强化学习,实现了高度可控的多粒度语音风格控制。用户可通过自然语言指令精准调节情感表达,支持东北话、四川话、粤语等多种方言演绎,具备高质量歌声合成能力,能在同一模型内实现说、演、唱三位一体。

MiMo-V2-TTS的功能特色
- 多粒度情感控制:支持从整体风格定调到局部情绪表达的精准调节,能在同一句话内完成语气转折和情感递变,真实还原人类说话的自然韵律。
- 自然语言风格指令:用户可用自然语言描述声音风格(如"刚睡醒、略带沙哑""深情、缓慢、近乎耳语"),无需预设标签或固定词汇,模型自动解析语义并映射到声学特征。
- 方言专家:原生支持东北话、四川话、河南话、粤语、台湾腔等多种方言,可进行角色扮演式风格化演绎。
- 跨界歌手:具备高质量歌声合成能力,能准确表达音高和节奏,在同一模型内实现说、演、唱三位一体。
- 副语言事件生成:支持咳嗽、叹息、犹豫填充词("嗯..."、"呃...")、紧张笑声等非语言声音的自然生成,且与上下文无缝融合。
MiMo-V2-TTS的核心优势
- 端到端多粒度情感控制:基于自研Audio Tokenizer和多码本架构,支持从整体风格定调到局部情绪转折的精准调节,能在同一句话内完成语气变化,真实还原人类说话的自然韵律。
- 自然语言风格指令:无需预设标签或固定词汇,用户可直接用自然语言描述声音风格(如"刚睡醒、略带沙哑""深情、缓慢、近乎耳语"),模型自动解析语义并映射到声学特征。
- 方言与多语言能力:原生支持东北话、四川话、河南话、粤语、台湾腔等多种方言,可进行角色扮演式风格化演绎,满足多样化语言社区需求。
- 说演唱三位一体:具备高质量歌声合成能力,能准确表达音高和节奏,在同一模型内实现说话、演绎、唱歌的无缝切换。
- 副语言事件生成:支持咳嗽、叹息、犹豫填充词("嗯..."、"呃...")、紧张笑声等非语言声音的自然生成,且与上下文无缝融合,让AI声音更具人性温度。
- 智能文本解析:自动识别标点符号、语气词和强调标记,无需额外标注或人工干预即可转换为恰当的语音表达,降低使用门槛。
- 多维度强化学习优化:在训练后期引入RL优化,围绕韵律自然度、音质稳定性、字词准确度、音色克隆质量等多维度持续迭代,确保输出质量。
- Agent原生设计:专为AI Agent场景打造,未来将与MiMo-V2-Omni的多模态理解能力深度整合,实现从感知到表达的协同进化。
MiMo-V2-TTS官网是什么
- 公式ウェブサイトアドレス:https://platform.xiaomimimo.com/#/docs/news/v2-tts-release
MiMo-V2-TTS的适用人群
- AI Agent开发者:需要为智能助手、智能座舱、智能家居等场景赋予自然、有情感的声音交互能力,提升用户体验的真实感和沉浸感。
- コンテンツクリエーター:包括有声书制作、播客 narration、短视频配音等领域的创作者,可通过自然语言指令快速生成多样化风格的语音内容。
- 游戏与互动娱乐开发者:需要为游戏角色、虚拟偶像、数字人提供实时语音交互和情感化配音的开发者。
- 方言与本地化内容团队:服务于特定地域用户的产品团队,可利用其原生方言支持能力打造更贴近本地用户的语音体验。
- 无障碍服务提供者:为视障人士、语言障碍群体等提供多样化语音辅助服务的机构或开发者。
- 音乐与音频制作人:需要歌声合成、虚拟歌手演绎等功能的音乐创作者,可利用其说演唱三位一体的能力拓展创作边界。
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事


コメントはありません