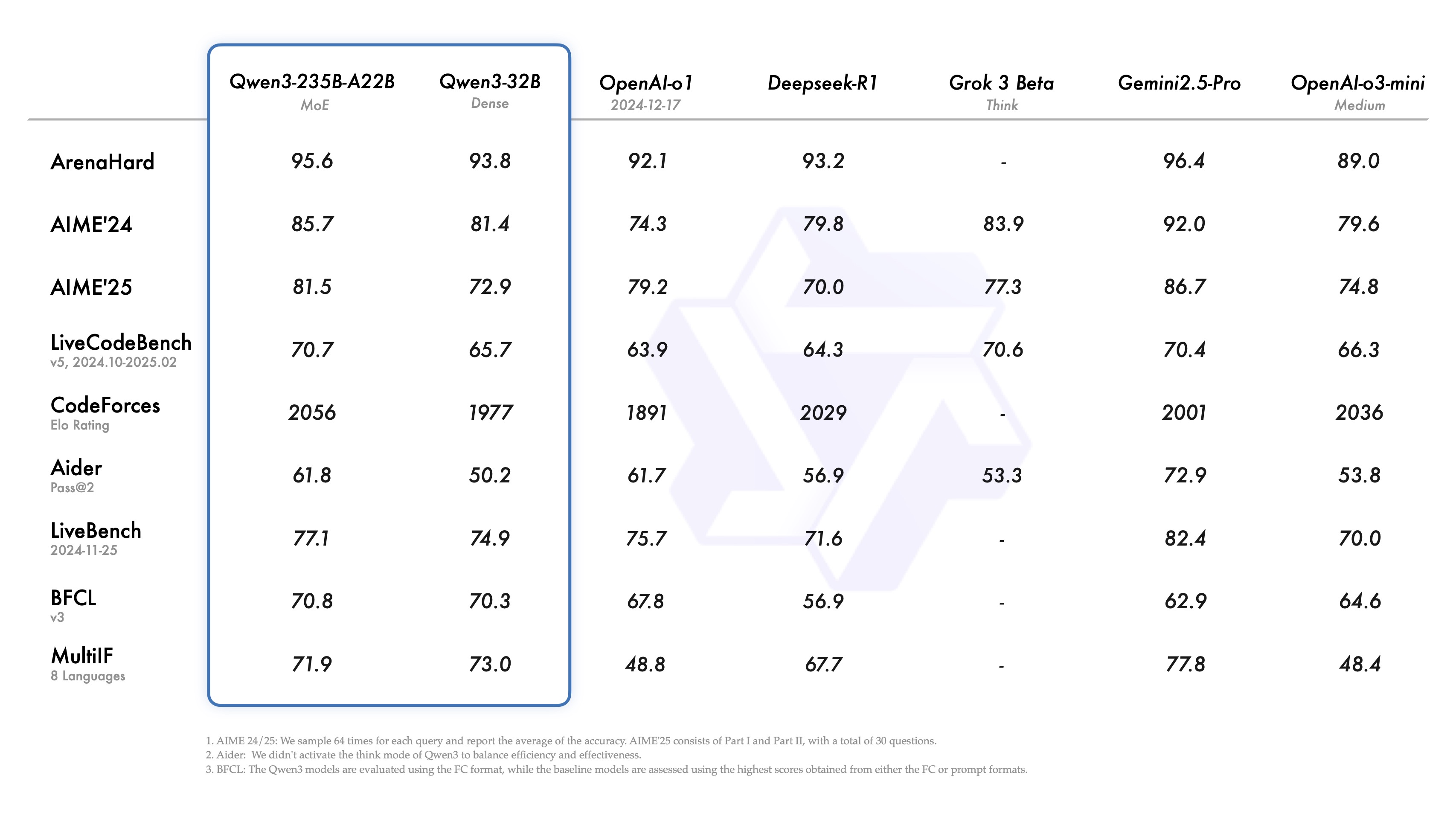
音声合成プロジェクトのベスト10を徹底レビュー

-オープンソースの音声合成(TTS)プロジェクト:リアルな "音声 "を注入するアプリケーション用
人工知能の波の中で、Text-to-Speech(TTS)技術は、デジタル世界と人間の感覚をつなぐ重要な架け橋となっている。インテリジェント・アシスタントにおける人間と機械の対話から、ナビゲーション・システムにおける音声ガイダンス、読書支援に至るまで、TTS技術はそのユニークな魅力で書き言葉の限界を打ち破り、情報伝達をより直感的で効率的なものにしている。
オープンソースの精神が、TTS技術の急速な発展を後押ししている。より多くの開発者や研究者がオープンソースコミュニティに参加し、TTSエコシステムの構築と改善に取り組んでいます。この記事では、知名度の高いオープンソースTTSプロジェクトに焦点を当て、その技術的特徴と応用の可能性を分析し、読者が幅広い選択肢の中から自分のニーズに最も適した「音」エンジンを見つけられるよう手助けする。
オープンソースTTSプロジェクトの概要
以下は、それぞれの長所を持つ一連のオープンソースTTSプロジェクトの紹介である。言語カバレッジ、音色の忠実度、機能性などの点で異なっています:
1.ChatTTS:対話シナリオのための自然な音声合成
プロジェクトの特徴 ChatTTS 会話シナリオにおける音声合成の効果を最適化することに重点を置き、その中核となる強みは以下の通りです。中国語と英語の優れた混合文脈処理歌で応えるマルチトーカーシミュレーション.ChatTTSは中国語、英語、日本語を含む6つの言語構成をサポートし、中国語と英語が混在するテキストをスムーズかつ自然に合成することができます。マルチスピーカー機能により、ChatTTSは異なるキャラクターの声をシミュレートすることができ、対話システムに豊かな表現力を与えます。
想定される応用シナリオ インテリジェントなカスタマーサービスシステム、会話AIアシスタント、多言語学習ツール、オーディオブック作成など。
アドバンテージだ: 会話シーンの最適化、自然でスムーズな中国語と英語の混読、複数の話者トーンのサポート。
注目すべき側面 極端な音質を追求するプロジェクトに比べ、ChatTTSは対話の自然さや機能性に重点を置いており、特定のシナリオで音質性能に差が出る可能性がある。

GitHubアドレス: https://github.com/2noise/ChatTTS
2.IMSトウカン:言語の壁を越えた合成機能
プロジェクトの特徴IMSトゥーカン による幅広い言語サポートは、7,000を超える言語の音声を合成できるという謳い文句で知られている。この素晴らしい言語カバレッジは、グローバルなアプリケーションの構築に理想的です。またIMS Toucanにはマルチスピーカー音声合成この機能は、さまざまな話者の声の特徴をシミュレートし、豊富な音色を提供することができる。
想定される応用シナリオ アプリケーションのグローバル展開、多言語教育プラットフォーム、希少言語音声リソース開発、言語研究など。
アドバンテージだ: 非常に高い言語カバレッジ、複数話者のサポート、活発なオープンソースコミュニティ。
注目すべき側面 このような幅広い言語サポートは、より少ない言語に特化したモデルほど、特定の言語における音質の洗練度が高くないことを意味するかもしれない。ターゲット言語に対するサポートの有効性を評価するために、実用的なテストを行うことが推奨される。
文本转语音工具-1")
GitHubアドレス: https://github.com/DigitalPhonetics/IMS-Toucan
3.フィッシュ・スピーチ:中国語音声合成の習得
プロジェクトの特徴 魚のスピーチ 専門中国語、英語、日本語音声合成、特に中国語音声処理その性能は傑出している。同プロジェクトは、トレーニングに約15万時間の3ヶ国語データを使用したおかげで、音声合成の品質が実際の人間に近いことを強調している。フィッシュ・スピーチは、アプリケーション・シナリオが主に中国語で、音声の自然さと表現力に高い要求がある場合、チェックする価値がある。
想定される応用シナリオ 中国語音声アシスタント、中国語コンテンツ作成プラットフォーム、中国語オーディオブック、中国語音声ナビゲーション。
アドバンテージだ: オープンソースコミュニティによる高い自然性とフレンドリーな中国語サポートで、優れた品質の中国語音声合成を実現。
注目すべき側面 言語サポートは、中国語、英語、日本語を中心としている。

GitHubアドレス: https://github.com/fishaudio/fish-speech
4.FunAudioLLM:LLMを利用した音声対話の新しいモデル
プロジェクトの特徴 FunAudioLLMはアリババによってオープンソース化されており、その革新性はTTS技術と大規模言語モデリング(LLM)の深い統合にあります。人々とLLMの間の、より自然でスムーズな音声対話.高品質な音声生成に焦点を当てるだけでなく、LLMアプリケーションにおける音声理解と生成の相乗効果を強調し、次世代の音声対話パラダイムを探求している。ここで特に興味深いのは コージーボイス また、優れた高速ボイスクローニング機能を備えている。
想定される応用シナリオ 新世代のスマート・スピーカー、高度な音声対話機能を備えたスマート・アシスタント、LLMベースの対話システム、スマート・ホーム・コントロール・センター。
アドバンテージだ: アリ社の強力な技術力に支えられたLLMは、革新的な方向性と相まって、よりインテリジェントな音声対話体験を実現することが期待されている。
注目すべき側面 比較的新しいプロジェクトであるため、モデルの成熟度と安定性はまだ発展途上であり、洗練されていない可能性がある。

GitHubアドレス: https://github.com/FunAudioLLM
5.Parler-TTS:軽量音声と定型音声の融合
プロジェクトの特徴 パーラーTTS フォーカスけいりょうきゅう歌で応えるスタイリッシュな音声合成.Parler-TTSは、対象話者の性別、ピッチ、スピード、その他の個人化された特徴を模倣し、話者のスタイルを指定しながら、高品質で自然な音声を生成します。これにより、Parler-TTSは、リソースに制約のあるデバイスでも効率的に動作し、音声合成によりパーソナルで表現力豊かなタッチを与えることができます。
想定される応用シナリオ モバイルアプリケーション、組込みシステム、パーソナライズされた音声を必要とするアプリケーション、音声クローニングやスタイル移行研究など。
アドバンテージだ: このモデルは軽量で、消費リソースが少なく、定型化された音声生成をサポートし、話者の音色特性を模倣することができる。
注目すべき側面 軽量モデルであるため、極限の音質を求めると大型モデルには劣るかもしれない。

GitHubアドレス: https://github.com/huggingface/parler-tts
6.F5-TTS:リアルタイムで効率的なゼロサンプル音のクローニング
プロジェクトの特徴 F5-TTS 上海交通大学とケンブリッジ大学が共同でオープンソース化したもの。ゼロサンプルのサウンドクローニング歌で応えるリアルタイム音声合成.その推論リアルタイムレートは0.15に達し、合成速度はリアルタイムよりはるかに速く、レイテンシに敏感なアプリケーションのニーズを満たすことができます。さらに、F5-TTSは以下の機能をサポートしています。スピーチコントロール歌で応える言語/方言間のスムーズな移行RTF=0.15は、1秒間の音声を合成するのに0.15秒しかかからないことを意味します。 Real-Time Factor 0.15」とは、通常、Real-Time Factor (RTF)のことで、値が小さいほど合成が速くなります。RTF=0.15とは、1秒間の音声を合成するのに0.15秒しかかからないことを意味します。
想定される応用シナリオ リアルタイムボイスインタラクションシステム、ゲームキャラクターアフレコ、ライブインタラクティブアプリケーション、多言語会議システム、インスタント音声翻訳など。
アドバンテージだ: ゼロサンプルの音声クローニング、制御されたスピーチレート、言語間のスムーズな移行をサポートし、リアルタイム推論は高速です。
注目すべき側面 ゼロサンプルクローンの音質とクローニングは、リファレンスオーディオの音質に影響される場合があります。

GitHubアドレス: https://github.com/SWivid/F5-TTS
7.MaskGCT:非自己回帰的アーキテクチャによる汎用ゼロサンプルTTS
プロジェクトの特徴 マスクGCT は完全非自己回帰的パワフルなTTSモデルもある。ゼロサンプル特徴豊富な機能を備え、以下をサポートしている。異言語翻訳・ダビング、音声クローニング、言語変換、感情制御非自己回帰型アーキテクチャにより、合成品質を保証しながら高速化・効率化を実現。非自己回帰型アーキテクチャにより、合成品質を保証しながら、より高速で効率的な生成が可能であり、また、多様な機能により、より幅広い応用シーンでの利用が可能です。
想定される応用シナリオ 多言語映画吹替、音声コンテンツローカリゼーション、パーソナライズ音声カスタマイズサービス、音声著作権保護技術、感情音声インタラクションシステム、異言語コミュニケーションツールなど。
アドバンテージだ: 非自己回帰的アーキテクチャ、高速生成、豊富な機能性、クロスランゲージのサポート、音声クローン、感情コントロール、その他多くの高度な機能。
注目すべき側面 機能はより複雑で、その高度な機能を完全に使いこなすには、ある程度の技術的スキルが必要になるかもしれない。
-1")
GitHubアドレス: https://github.com/open-mmlab/Amphion/tree/main/models/tts/maskgct
8.OuteTTS(旧Smol TTS):LLaMaアーキテクチャ用の軽量で柔軟なTTS
プロジェクトの特徴 OuteTTS (スモールTTSとも呼ばれる)に基づく。 LLaMa建築になるように作られた。ゼロサンプル音声クローニングモデル。OuteTTSの主な特徴は、軽量で柔軟性があり、導入や使用が簡単であることです。OuteTTSは、ゼロサンプルのクローニングを素早く試してみたいが、複雑すぎるモデルは使いたくないという開発者にとって、価値あるエントリーレベルのオプションです。
想定される応用シナリオ 軽量アプリケーションの迅速な開発、プロトタイピング、パーソナル音声アシスタントのカスタマイズ、音声クローン技術の実験など。
アドバンテージだ: LLaMaアーキテクチャに基づくこのモデルは、軽量で導入が容易であり、ゼロサンプル音声クローニングをサポートしている。
注目すべき側面 軽量モデルのため、音質や機能の豊富さは比較的制限されることがある。 OuteTTSやSmol TTSという名称のアイテムがしばしば登場するが、これは同じアイテムを指している。
GitHubアドレス: https://github.com/edwko/OuteTTS
9.ココロ:少ない参考文献数、多言語対応のコンパクトモデル
プロジェクトの特徴 ココロ は、わずか8,200万個のパラメータを持つ比較的小さなオープンソースのTTSモデルであり、比較的小さな音声データセットで学習されている。モデルのサイズが小さいにもかかわらず、Kokoroは以下のような優れた結果を示している。多言語サポート多言語TTS分野における小型モデルの可能性を示している。Kokoroは、リソースに制約のある環境で多言語TTS機能を展開する必要がある場合に、実行可能な選択肢となり得る。
想定される応用シナリオ 低リソース・デバイス・アプリケーション、組み込みシステム、迅速に展開可能な多言語機能、コスト重視のTTSソリューションなど。
アドバンテージだ: このモデルは、参加者数が少なく、必要なリソースが少なく、多言語に対応し、展開が容易である。
注目すべき側面 モデルのサイズとトレーニングデータの量に制限され、音質と自然さはより大きなモデルには及ばないかもしれない。

GitHubアドレス: https://github.com/hexgrad/kokoro
10.ラッサ:高忠実度ゼロサンプル音声クローニング技術
プロジェクトの特徴 ルラサ は香港科学技術大学のオープンソースのオーディオラボである。ゼロサンプル音声クローニングとTTSモデリングLlasaはプレーンテキストからの音声生成と、与えられた参照音声を用いた高精度なクローニングの両方をサポートしています。Llasaは、平文からの音声生成と、与えられた参照音声を用いた高精度な音声クローニングの両方をサポートしている。音声クローニングの忠実さと自然さLlasaは、ゼロサンプル条件下で極めてリアルな音色再現を目指したボイスクローニング技術です。ボイスクローン技術に高いクオリティを求めるのであれば、Llasaは研究・応用する価値がある。
想定される応用シナリオ 高精度ボイスクローニング、キャラクターアフレコ、ボイスカスタマイズ、パーソナライズドボイスコンテンツ生成、ボイスコンテンツ著作権保護、エモーショナルボイス合成など。
アドバンテージだ: 香港科学技術大学オーディオ研究所が技術力を駆使して製作した、自然で類似性の高い高品質なゼロサンプル音声クローン。
注目すべき側面 モデルサイズが大きくなると(10億パラメータレベル)、計算リソースへの要求が高くなる可能性がある。

モデルのダウンロードアドレス https://huggingface.co/HKUSTAudio/Llasa-1B
自分に合ったオープンソースTTSプロジェクトを選ぶには?
非常に多くの優れたオープンソースTTSプロジェクトが存在するため、ニーズに合ったものを選ぶことが重要です。ここでは、十分な情報を得た上で決定するのに役立つ、いくつかの重要な考慮事項について説明します:
- 対象言語: どの言語をサポートする必要がありますか?ターゲット言語をサポートしているプロジェクトが優先されます。
- 声質と自然さ: 合成音声の音質や自然さについて、どのようなことを期待しますか?各プロジェクトが提供するデモを聴いて、さまざまなモデルの音声効果を視覚的に把握し、主観的評価指標(MOS - Mean Opinion Scoreなど)と客観的評価データを組み合わせて総合的に評価することをお勧めします。
- 機能特性の要件: ゼロサンプルクローニング、マルチスピーカー、エモーションコントロール、スピーチレート調整などの高度な機能が必要ですか?実際のニーズに基づいて、適切な機能を備えたアイテムをお選びください。
- パフォーマンスと効率の考慮: あなたのアプリケーション・シナリオにはリアルタイム性が必要ですか?モデルの推論速度とリソース消費にはどのような制限がありますか?例えば、リアルタイムの対話型アプリケーションでは、推論速度が速いモデルを選択する必要があり、リソースに制約のあるデバイスでは、軽量モデルを検討する必要があります。
- 使いやすさとドキュメンテーションの改善: そのプロジェクトのドキュメンテーションは徹底しており、理解しやすいか?デプロイや使い方が簡単か?初心者の開発者にとって、明確なドキュメントがあり、簡単に始められるプロジェクトを選ぶことは、学習コストを効果的に削減することができます。
- コミュニティ活動とメンテナンス: そのプロジェクトのオープンソースコミュニティは活発か?更新やメンテナンスが継続的に行われているか?コミュニティが活発であるということは、通常、よりタイムリーな技術サポートと、より迅速な反復を意味します。
- ライセンス契約: 商用利用が許可されているかどうか、商用利用が特定の条件の対象となるかどうかを確認するために、プロジェクトのオープンソースライセンス契約に常に注意を払ってください。一般的なオープンソースライセンスには、MITライセンス、Apache 2.0ライセンス、GPLライセンスなどがあります。
- ハードウェアリソース要件: TTSモデルによって、必要なハードウェア・リソースは異なる。大規模なモデルの中には、スムーズに動作させるために高性能なGPUを必要とするものもあれば、軽量なモデルであればCPU環境でも動作可能なものもあります。ハードウェアの状況に応じて適切なモデルを選択してください。
上記の要素を組み合わせて、特定のアプリケーションシナリオと技術的能力に従って、各プロジェクトを慎重に評価し、テストすることをお勧めします。多くのプロジェクトは事前に訓練されたモデルとデモ例を提供していますので、それらを体験し、あなたのニーズに最も適したプロジェクトを選択することができます。
結語
オープンソースTTSプロジェクトの急増は、音声技術の革新を促進し、開発者に豊富な選択肢を提供しました。あなたが商業開発者であれ、学術研究者であれ、技術愛好家であれ、あなたのアプリケーションにより生き生きとした自然な音声対話体験を与える理想的な音声エンジンをオープンソースコミュニティで見つけることができます。 技術の絶え間ない進歩に伴い、オープンソースTTS分野では今後さらに多くのイノベーションが生まれ、音声技術の普及と応用が促進され続けることを期待する理由があります。
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事


コメントはありません