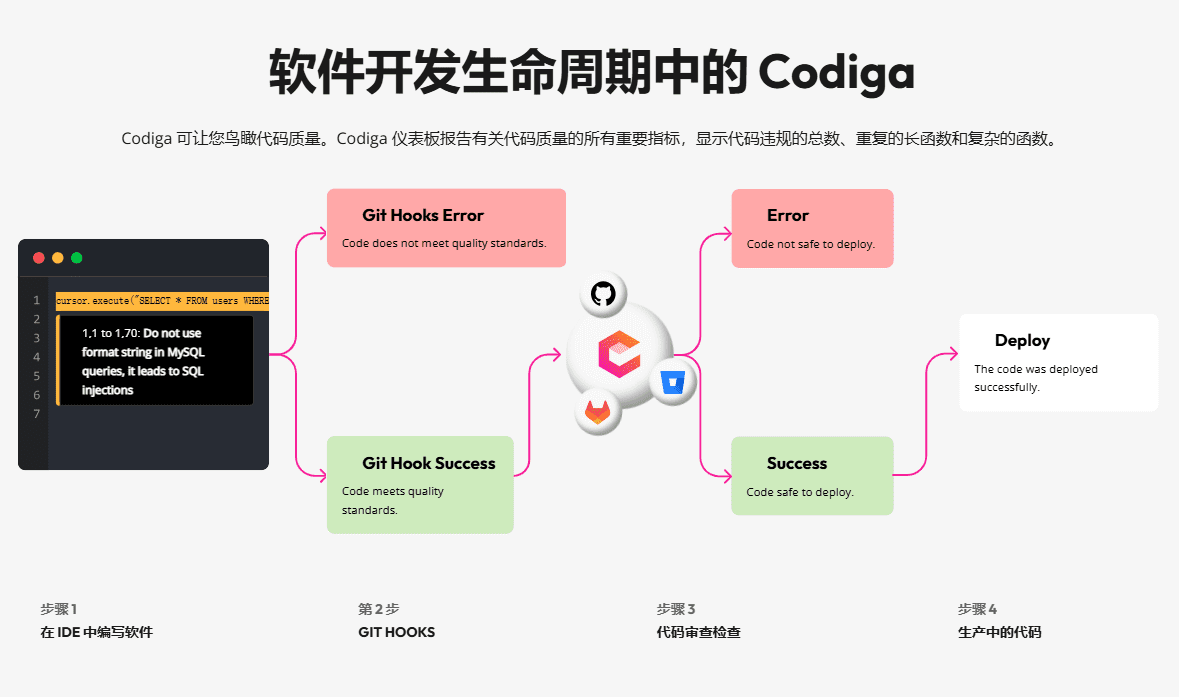
MedASR - Googleのオープンソース医療音声認識モデル

MedASRとは?
MedASRは、Googleによってオープンソース化された1億500万パラメータの医療用音声認識モデルであり、5,000時間に及ぶ減感作された臨床コーパスで微調整され、薬剤、投与量、解剖学用語に最適化されています。このモデルは、コンシューマーグレードのGPU1つで微調整が可能なConformerアーキテクチャを採用し、16kHzのモノラル入力をサポートし、Hugging Faceのワンクリックダウンロード、Vertex AIのオンラインデプロイメント、ローカル微調整ノートブックを提供します。これはGoogle Health AIコンプライアンス条項に準拠しており、出力は手動でレビューする必要があるため、現在の医療シナリオに適した選択肢となっています。精度と使いやすさの両方を考慮すると、現在の医療シナリオに適したASRソリューションである。

MedASRの機能的特徴
- 医療専用軽量モデル1億500万パラメータのコンフォーマ・アーキテクチャ、コンシューマー向けGPU1つで微調整可能、16kHzモノラル入力、ストリーミング/バッチ推論のレイテンシは300ms以下。
- 正確な医療語彙認識5,000時間に及ぶ減感作された臨床音声(放射線科、内科、家庭医)を基に微調整された6gramの医学言語モデルを内蔵し、薬品名、用法、解剖学用語の認識精度が大幅に向上しました。
- トップクラスの認識精度これはWhisper v3 Largeと比較して約60%低い数値です。
- 閾値ゼロのオープンソース体験Colab公式ノートブック、ワンクリックで試聴可能、複雑な環境設定は不要。
- クラウドでワンクリック展開可用性の高いオンライン・サービスは、Vertex AI Model Gardenを通じて直接リリースされ、病院の高い同時実行性と低遅延のニーズを満たすために、自動的に弾力的なスケーリングが行われます。
- 民営化微調整サポートオープンソースには微調整用のノートブックが付属しており、病院は患者のプライバシーとデータのセキュリティを保護するために、オフライン操作全体のトレーニングを継続するために独自のデータを使用することができます。
- コンプライアンス・セキュリティ・フレームワークGoogle Health AI Developer Foundationsのプロトコルに従います。このプロトコルでは、直接的な臨床判断を明確に禁止し、医療リスクを軽減するために専門家によるアウトプットの確認が義務付けられています。
MedASRの強み
- エクストリーム・ライトウェイト1億500万パラメータのコンフォーマーでは、コンシューマー向けGPU1つで微調整が可能で、推論レイテンシは300ms以下です。
- データ 深耕放射線科、内科、家庭医など、複数の診療科における実際のシナリオを網羅した、5,000時間に及ぶ減感作医療スピーチ専門トレーニングに基づく。
- 一流の精度民間の放射線科テストセットRAD-DICTのワードエラー率はわずか4.6%で、Whisper v3 Largeと比較して約60%の削減となり、これは業界最高水準です。
- 字句の特殊化6グラムの医学言語モデルを内蔵し、薬品名、用法、解剖学用語の認識精度が大幅に向上。
- 入力フレンドリー16kHzのモノラル波形に対応し、複雑な前処理や後処理をすることなく、ボタンひとつでストリーミングとバッチ推論を切り替えることができる。
MedASRの公式ウェブサイトは?
- プロジェクトのウェブサイト:: https://developers.google.com/health-ai-developer-foundations/medasr
- GitHubリポジトリ:: https://github.com/google-health/medasr
- HuggingFaceモデルライブラリ:: https://huggingface.co/google/medasr
MedASRの対象者
- 病院情報セクション医師のキーボード入力の負担を軽減し、カルテ記入の適時性を向上させる高精度の音声入力システムを迅速に稼動させる必要がある。
- 臨床医放射線科、内科、家庭医療科の医師は、検査報告書、処方箋、患者記録を口述し、誤字脱字の少なさを追求している。
- ヘルスケアAIスタートアップチーム画像レポート、手術記録など、垂直シナリオのオープンソースモデルに基づく製品を二次開発したい。
- 遠隔コンサルテーション・プラットフォーム医師と患者の対話をリアルタイムで構造化テキストに書き起こし、その後のQA、検索、ビッグデータ分析に役立てる必要がある。
- 医学教育研究者高品質な医療用音声トランスクリプションの結果を使用して、ナレッジグラフを構築し、下流のNLPモデルを訓練し、音声データマイニングの研究を行います。
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事



コメントはありません