Maxun:ウェブデータを自動的にクロールし、APIやスプレッドシートに変換するオープンソースのコード不要プラットフォーム

はじめに
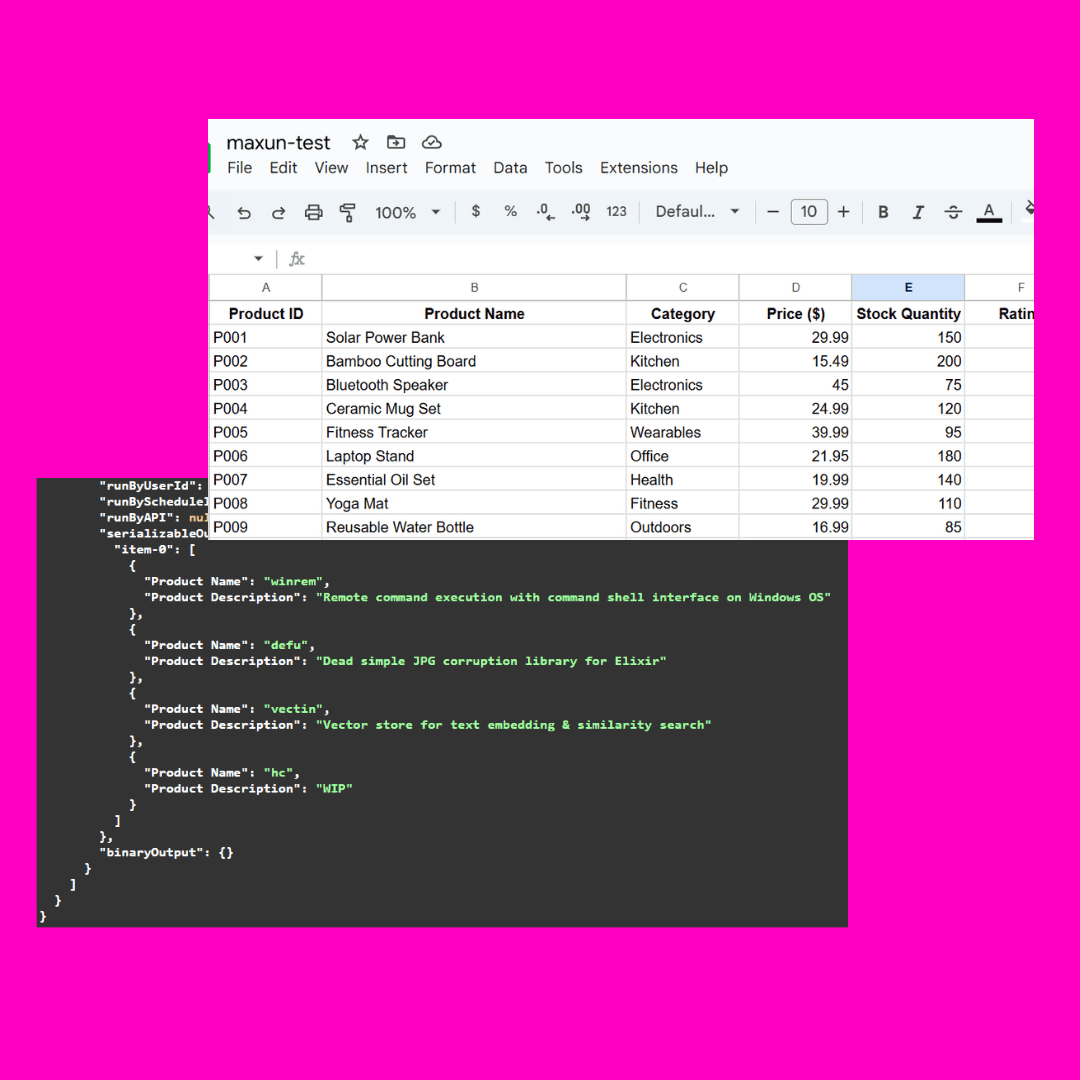
Maxunはオープンソースのコード不要のウェブデータ抽出プラットフォームで、ウェブデータを自動的にクロールしてAPIやスプレッドシートに変換するロボットを数分でトレーニングすることができます。このプラットフォームは、ページングとスクロールをサポートし、ウェブサイトのレイアウトの変更に適応することができ、様々なデータ抽出ニーズに対応する強力なデータクローリング機能を提供します。

機能一覧
- コード不要のデータ抽出:ウェブページのデータをクロールするためのコードを書く必要がありません。
- 自動データクローリング:ロボットがデータクローリング作業を自動化
- API生成:クロールされたデータをAPIに変換する
- スプレッドシート変換:取り込んだデータをスプレッドシートにエクスポート
- ページングとスクロールのサポート:複数ページデータや長いページデータの処理
- ウェブサイトのレイアウト変更に対応:ページレイアウトの変更に自動的に対応
- ログインと二要素認証のサポート:ログインが必要なサイトからデータをクロール(近日公開予定)
- Google Sheetsとの統合:Google Sheetsに直接データをインポートする。
- プロキシ対応:外部プロキシを使用してボット対策を回避する。
ヘルプの使用
設置プロセス
Docker Composeを使ったインストール
- クローン・プロジェクト・ウェアハウス
git clone https://github.com/getmaxun/maxun
- プロジェクト・カタログにアクセスする:
cd maxun
- Docker Composeを使ってサービスをビルドし、起動する:
docker-compose up -d --build
手動インストール
- Node.js、PostgreSQL、MinIO、Redisがシステムにインストールされていることを確認します。
- クローン・プロジェクト・ウェアハウス
git clone https://github.com/getmaxun/maxun
- プロジェクト・ディレクトリに移動し、依存関係をインストールする:
cd maxun
npm install
cd maxun-core
npm install
- フロントエンドとバックエンドのサービスを開始する:
npm run start
- フロントエンド・サービスはhttp://localhost:5173/、バックエンド・サービスはhttp://localhost:8080/。
使用ガイドライン
- ロボットの創造::
- プラットフォームにログイン後、「Create Bot」ボタンをクリックします。
- キャプチャするデータの種類(リスト、テキスト、スクリーンショット)を選択します。
- 対象URL、クロール頻度などのクロールルールを設定する。
- 保存してロボットを起動すると、自動的にデータ取り込みタスクが実行される。
- データエクスポート::
- ボットミッションが完了したら、ミッションの詳細ページに行く。
- エクスポート形式(APIまたはスプレッドシート)を選択します。
- エクスポート」ボタンをクリックしてデータをダウンロードするか、APIリンクを取得します。
- ページングとスクロールの処理::
- ボット作成時にページングとスクロールのオプションを設定します。
- ロボットは、複数ページのデータや長いページのデータを自動的に処理し、データの整合性を確保する。
- ウェブサイトのレイアウト変更への対応::
- このプラットフォームには、ページレイアウトの変更に自動的に適応するインテリジェントなアルゴリズムが組み込まれている。
- 手動でクロールルールを調整する必要はなく、ロボットが自動的に変更に適応する。
- グーグル・シートとの統合::
- Platform Settingsで、Google Sheetsの統合を設定します。
- ロボットによって取り込まれたデータは、指定されたGoogle Sheetsのフォームに自動的にインポートされる。
- プロキシの使用::
- Platform Settingsで、外部エージェントを設定する。
- ロボットはプロキシを通じて把持タスクを実行し、アンチロボット保護をバイパスする。
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事


コメントはありません