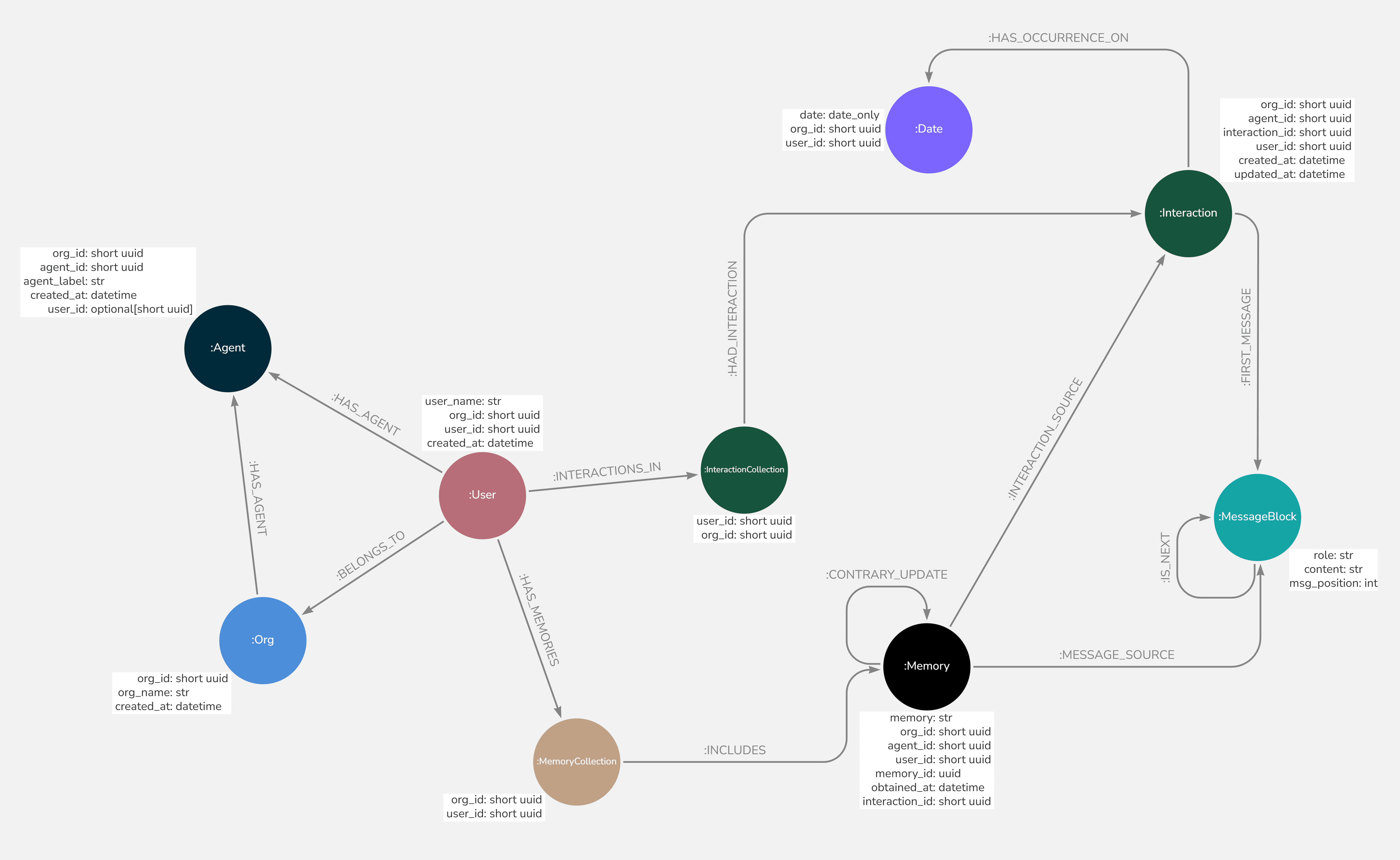
MarkPDFDown: マルチモーダルモデルに基づくPDFからMarkdownへの変換

はじめに
MarkPDFDownはオープンソースのツールです。マルチモーダルな大きな言語モデルを使ってPDFファイルをMarkdown形式に変換する。開発者はGitHubユーザーのjorben氏です。 このツールの目的はシンプルで、PDFドキュメントをより簡単に編集・共有できるようにすることです。文書内の見出し、リスト、表、その他の構造を認識し、きれいにフォーマットされたMarkdownファイルを生成する。このプロジェクトはPythonで書かれており、PDFファイルを処理してテキスト形式に変換する必要があるユーザーに適している。現在のバージョンはOpenAIのAPIに依存する必要があり、ユーザーは独自のAPIキーを準備する必要があります。markPDFDownのオープンソースコードはGitHubにあります。

機能一覧
- ドキュメントの構造を保持したまま、PDFファイルをMarkdown形式に変換します。
- 見出し、段落、リスト、表、その他の要素の認識をサポート。
- マルチモーダル・マクロモデリングによってPDFコンテンツを理解し、正確な変換結果を保証します。
- コマンドライン操作、PDFファイルのバッチ処理のサポートを提供します。
- オープンソースで無料、ユーザーはコードをカスタマイズできる。
ヘルプの使用
MarkPDFDownはコマンドラインツールで、使用するためにはパソコンにインストールし、環境を設定する必要があります。以下はインストールと操作の詳細な手順ですが、初心者の方でも簡単に使い始めることができます。
設置プロセス
- 環境を整える
Python 3.9がインストールされたコンピューターが必要です。そうでない場合は、まずPythonをダウンロードしてインストールしてください。
ターミナルを開き、以下のコマンドを入力して仮想環境を作成する:
conda create -n markpdfdown python=3.9
そして環境をアクティブにする:
conda activate markpdfdown
- ダウンロードコード
ターミナルでコマンドを入力して、MarkPDFDownのGitHubリポジトリをクローンします:
git clone https://github.com/jorben/markpdfdown.git
プロジェクトフォルダーに移動する:
cd markpdfdown
- 依存関係のインストール
このプロジェクトには、いくつかのPythonライブラリーのサポートが必要です。以下のコマンドを実行してインストールしてください:
pip install -r requirements.txt
- APIキーの設定
MarkPDFDownはOpenAIのマルチモーダルモデルを使用しており、APIキーが必要です。まずOpenAIのウェブサイトにアクセスしてアカウントを登録し、キーを取得してください。
端末にキーをセットする:
export OPENAI_API_KEY=<你的API密钥>
モデルやAPIアドレスを変更したい場合は、再度設定することができます:
export OPENAI_DEFAULT_MODEL=<你的模型名>
export OPENAI_API_BASE=<你的API地址>
- インストールの確認
輸入python main.py --helpヘルプメッセージが表示されれば、インストールは成功です。
使用方法
インストール後のMarkPDFDownの操作は非常に簡単で、主にコマンドラインから行います。具体的な手順は以下の通りです。
PDFファイル全体を変換する
次のようなPDFファイルがあるとします。 tests/input.pdfMarkdownファイルに変換したい場合 output.md.ターミナルに入力する:
python main.py < tests/input.pdf > output.md
を実行した後output.md 変換されたMarkdownコンテンツと一緒に現在のフォルダに表示されます。
PDFの特定のページを変換する
2ページから5ページなど、特定のページだけを変換したい場合は、次のように入力します:
python main.py 2 5 < tests/input.pdf > output.md
最初の番号は開始ページ、2番目の番号は終了ページです。ページ番号は1から数えます。
Dockerで実行する
Python環境をインストールしたくない?あなたのコンピューターにDockerがあることを確認して、それを実行してください:
docker run -i -e OPENAI_API_KEY=<你的API密钥> jorben/markpdfdown < tests/input.pdf > output.md
これはDockerコンテナを通してファイルを直接変換する。
機能
- コア機能:PDF to Markdown
コマンドラインウィンドウにPDFファイルをドラッグするか、直接ファイルパスを入力すると、ツールは自動的にコンテンツを分析します。タイトルは#そして##等から構成される。-はテーブルで表現され、テーブルはMarkdownテーブル形式で出力される。
例えば、タイトルが「はじめに」で、本文が「これが内容です」というPDFが変換されることがあります:
# 简介
这是内容
- バッチファイル
PDFファイルがたくさんある場合は、ループでコマンドを呼び出すスクリプトを書くことができる。例えばLinuxでは
for file in *.pdf; do python main.py < "$file" > "${file%.pdf}.md"; done
- デバッグと改善
変換結果にご満足いただけませんか?GitHubで質問するか、自分でコードを変更してください。このプロジェクトはPythonで書かれており、ロジックはすべてmain.pyマイル。
ほら
- ファイル・パスに漢字を使ってはならない。
- APIキーは秘密にし、他者に開示されるべきではない。
- 大きなファイルは処理に時間がかかることがあり、安定したネットワークを確保できる。
アプリケーションシナリオ
- 学術研究
MarkPDFDownは、Markdownで直接編集できるように、見出しや表などの論文の構造を保持します。 - ドキュメンテーション
企業には、Markdownアーカイブに変換したいPDFの指示書や報告書がたくさんあります。このツールを使って一括変換し、GitHubやNotionにアップロードすることができます。 - テクニカルライティング
技術ブログを書くとき、PDF資料を引用する必要があります。直接変換してMarkdownエディタに貼り付ければ、手作業で整理する手間が省けます。
品質保証
- ネットワークは必要か?
はい。このツールはOpenAIのAPIに依存しており、動作するにはネットワークに接続する必要があります。 - 中国語のPDFに対応していますか?
サポートPDFがテキスト形式(スキャンした画像ではない)である限り、中国語のコンテンツは適切に変換できます。 - 変換ミスがあった場合は?
APIキーが正しいか、PDFファイルが壊れていないか確認してください。それでもうまくいかない場合は、GitHubにアクセスしてissueを提起してください。 - オフラインで使用できますか?
今すぐではない。将来的にはローカルモデルがサポートされるかもしれないが、今のところはOpenAIのサービスでなければならない。
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事

コメントはありません