Marker:PDFをMarkdownに素早く変換するオープンソースツール

はじめに
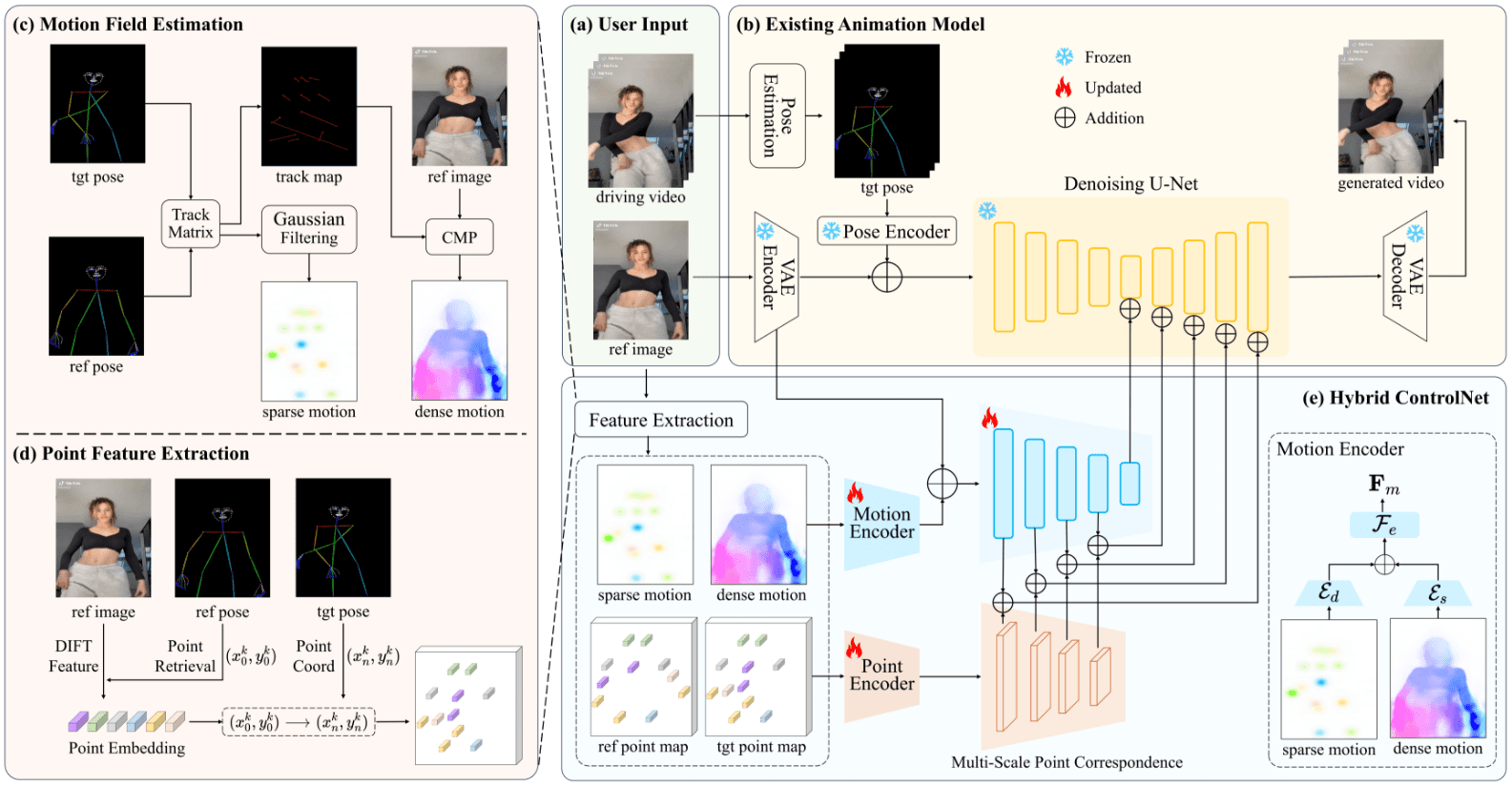
Markerは、PDFファイルを素早く正確にMarkdown形式に変換するために設計された、ディープラーニングベースの文書処理ツールです。ヘッダーやフッターなどの冗長なコンテンツの削除、表やコードブロックのフォーマット、画像の抽出と保存が可能です。また、ほとんどの数式をLaTeX形式に変換し、GPU、CPU、MPSでの実行をサポートします。

機能一覧
- PDFファイルをMarkdown形式に変換
- 書籍や科学論文を含む複数のドキュメントタイプをサポート
- ヘッダーやフッターなどの余分なコンテンツを削除する。
- テーブルとコードブロックの書式設定
- 画像の抽出と保存
- ほとんどの方程式をLaTeX形式に変換
- GPU、CPU、MPS動作をサポート
ヘルプの使用
設置プロセス
- 依存関係のインストールPython 3.6以上がインストールされ、以下の依存関係がインストールされていることを確認してください:
pip install marker-pdf - 実行例::
marker_single /path/to/file.pdf /path/to/output/folder --batch_multiplier 2 --max_pages 10
使用ガイドライン
個々のファイルを変換する
marker_single /path/to/file.pdf /path/to/output/folder --batch_multiplier 2 --max_pages 10
--batch_multiplierは、VRAM に余裕がある場合、デフォルトのバッチサイズの倍数です。数値が大きいほど多くの VRAM を使用しますが、処理速度は速くなります。デフォルトのバッチサイズには約 3GB の VRAM が必要です。--max_pagesは処理する最大ページ数です。この項目を省略すると、文書全体が変換されます。--langsは、OCRに使用する文書言語のコンマ区切りリスト(オプショナル)です。デフォルトではオプショナルですが、tesseractを使用する場合は指定する必要があります。--ocr_all_pagesこのパラメータまたは環境変数 `OCR_ALL_PAGES` が真であれば、OCRは強制されます。
サポートされているSurya OCR言語の一覧は、[ ] にあります。以下はが見つかりました。さらに多くの言語が必要な場合は、サポートされている言語のどれでも使うことができます。 OCR_ENGINE に設定する。 ocrmypdf.OCRが必要なければ、マーカーはどんな言語にも対応できる。
複数のファイルを変換する
marker /path/to/input/folder /path/to/output/folder --workers 4 --max 10 --min_length 10000
--workersは同時に変換されるPDFの数です。デフォルト設定は1ですが、CPU/GPU使用量の増加と引き換えにスループットを上げるためにこの値を増やすことができます。各ワーカープロセスは、ピーク時に5GB、平均で3.5GBのVRAMを使用します。--maxは変換するPDFの最大数です。この項目を省略すると、フォルダ内のすべてのPDFが変換されます。--min_lengthは、PDFから抽出される文字数の最小値で、この値以上のPDFのみが処理の対象となります。多くのPDFを処理する場合は、画像中心のPDFのOCR(処理が遅くなる)を避けるために、この値を設定することをお勧めします。--metadata_fileは、PDFに関するメタデータを含むオプションのJSONファイルパスです。提供された場合、このファイルは各PDFの言語を設定するために使用されます。言語の設定は、Surya(デフォルト)ではオプションですが、Tesseractでは必須です。フォーマットは以下の通りです:
{
"pdf1.pdf": {"languages": ["English"]},
"pdf2.pdf": {"languages": ["Spanish", "Russian"]},
...
}
言語名またはコードのいずれかを使用できます。正確なコードはOCRエンジンに依存します。Suryaコードの完全なリストについては、[ ]を参照してください。以下は]、テッセラクトについては[以下は]
FastGPT でのマーカー環境変数の設定
カスタム解決サービスを有効にするには、FastGPT で次の環境変数を設定する必要があります:
カスタム_read_file_url=http://xxxx.com/v1/parse/file
CUSTOM_READ_FILE_EXTENSION=pdf
- CUSTOM_READ_FILE_URL - カスタム解決サービスのアクセス・アドレス、ホストを配置した解決サービスのアドレスに変更する必要があります。
- CUSTOM_READ_FILE_EXTENSION - 解析に対応するファイル・タイプのサフィックスを指定する。
解析効果を検証する
設定完了後、以下の手順で解析効果を確認できます:
- ナレッジベースにPDFファイルをアップロードし、アップロードを確認する。
- システムログを表示する(LOG_LEVELをinfoまたはdebugレベルに設定する必要があります)。
- Markerによって解析されたPDFファイルには完全な画像リンクが含まれていることがわかります。
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事

コメントはありません