LongBench v2:長いテキストの評価 +o1?


実世界、長文、複数タスクにおける「深い理解と推論」のためのビッグモデルの評価
近年、長文に対する大規模な言語モデルの研究が大きく進展し、モデルのコンテキストウィンドウの長さが当初の8kから128k、さらには1Mトークンまで拡張された。しかし、重要な疑問が依然として残っている。これらのモデルは、扱っている長文を本当に理解しているのだろうか?言い換えれば、これらのモデルは長いテキストの情報を深く理解し、学習し、推論することができるのだろうか?
この疑問に答え、深い理解と推論のための長文モデルの進歩を推進するために、清華大学とSmart Spectrumの研究チームは、実世界の長文マルチタスクにおけるLLMの深い理解と推論能力を評価するために設計されたベンチマークテストであるLongBench v2を開始した。
我々は、LongBench v2が、推論時間計算(例えばo1モデル)をスケーリングすることで、長いテキストシナリオにおける深い理解と推論の問題をどのように解決できるかの探求を前進させると信じている。
特性
LongBench v2は、既存の長文理解用ベンチマークと比較して、いくつかの大きな特徴があります:
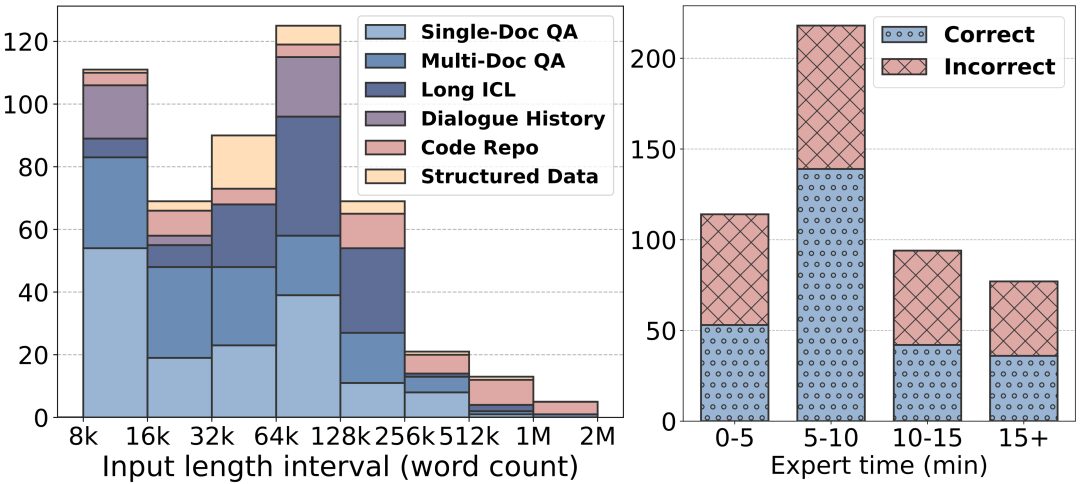
長いテキストの長さ:LongBench v2のテキストの長さは8kワードから2Mワードで、ほとんどのテキストは128k以下の長さです。
より高い難易度:LongBench v2には503問の難易度の高い4択の多肢選択問題が含まれており、文書内検索ツールを使用する人間の専門家でさえ短時間で正解するのに苦労するような問題が含まれています。人間の専門家は、15分の制限時間内で平均53.7%の正確さしか達成できませんでした(ランダムで25%)。
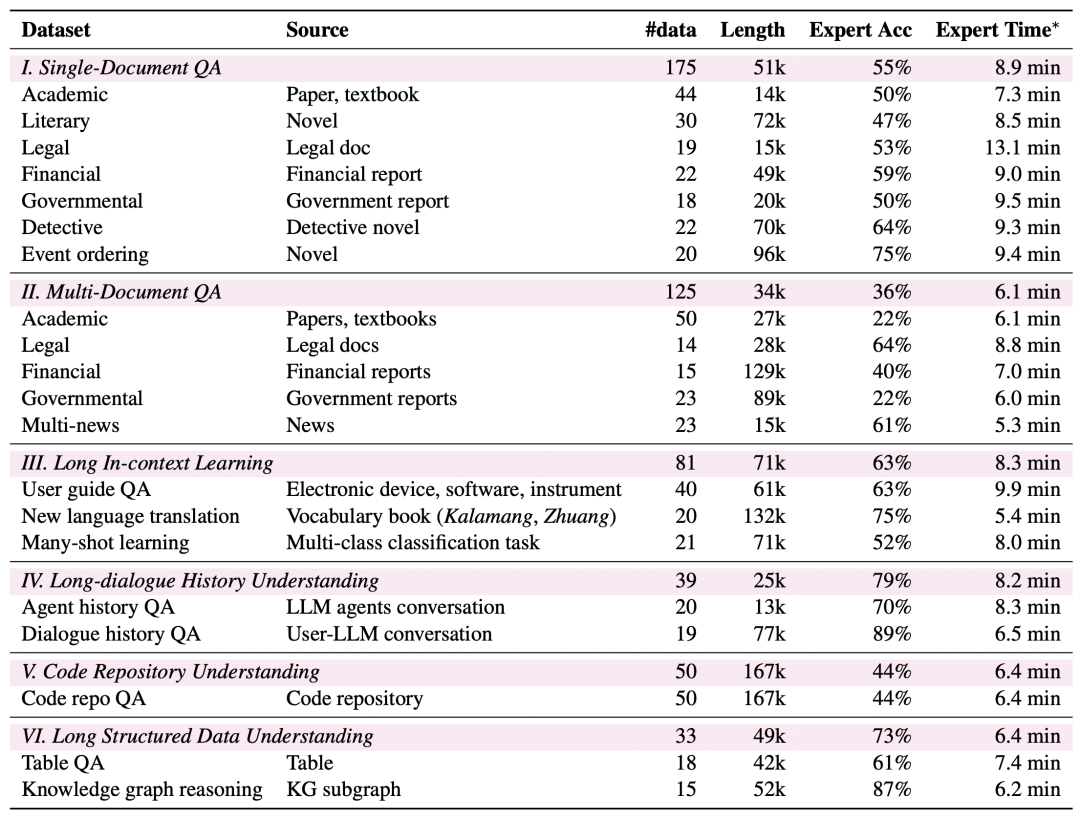
より広範なタスクカバレッジ:LongBench v2は、単一文書クイズ、複数文書クイズ、長文文脈学習、長文対話履歴理解、コードリポジトリ理解、長文構造化データ理解の6つの主要タスクカテゴリをカバーし、合計20のサブタスクが様々な実世界シナリオをカバーしています。
より高い信頼性: 評価の信頼性を確保するために、LongBench v2のすべての問題は多肢選択形式であり、データの質の高さを保証するために、厳格な手作業によるラベル付けとレビュープロセスを経ています。
データ収集プロセス
データの質と難易度を保証するために、LongBench v2は以下のステップからなる厳格なデータ収集プロセスを採用している:
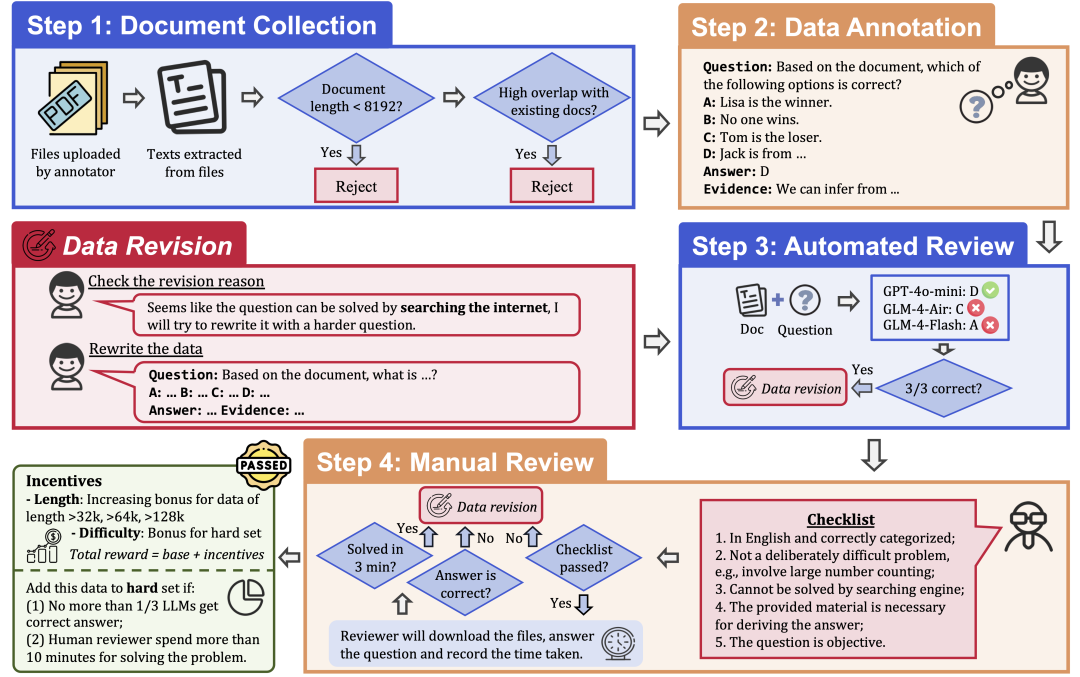
文書収集:さまざまな学歴と学年を持つ一流大学のアノテーター97人を採用し、研究論文、教科書、小説など、個人的に読んだり使ったりしたことのある長文の文書を収集する。
データ・ラベリング:収集した文書に基づき、ラベラーは4つの選択肢と正解、それに対応する証拠を持つ多肢選択式の質問をする。
自動レビュー:アノテーションされたデータは、3つのLLM(GPT-4o-mini、GLM-4-Air、GLM-4-Flash)を用いて、128kのコンテキストウィンドウで自動的にレビューされ、3つのモデルすべてが正解した場合は、単純すぎるとみなされ、ラベルを付け直す必要があった。
人間による審査:自動審査に合格したデータは、24人のプロの人間による審査に割り当てられます。この審査では、専門家が質問に回答し、質問が適切かどうか、回答が正しいかどうかを判断します。専門家が3分以内に質問に正しく回答できた場合、その質問は単純すぎるとみなされ、ラベルを貼り替える必要があります。さらに、専門家が問題そのものが適切でない、または答えが間違っていると判断した場合は、採点のやり直しのために問題が返却されます。
データの修正:監査に合格しなかったデータは、すべての監査ステップに合格するまで、修正のために注釈者に戻される。
評価結果
評価では、ゼロ・ショットとゼロ・ショット+CoT(すなわち、まず思考連鎖をモデルに出力させ、次に選択された答えをモデルに出力させる)の2つのシナリオが検討された。
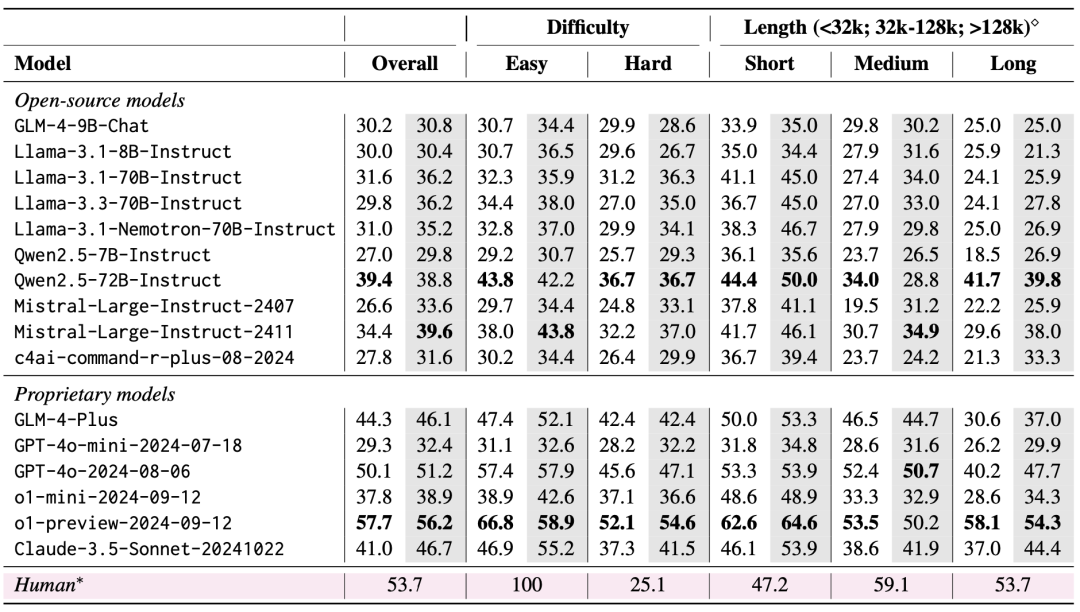
評価結果は、LongBench v2が現在のLLMにとって大きな挑戦であることを示しており、最も性能の良いモデルでさえ、直接回答出力で50.1%の精度しか達成していない。4%。
1.推論時間計算のスケーリングの重要性
評価結果において非常に重要な発見は、LongBench v2におけるモデルの性能は、推論時間計算のスケーリングによって大幅に改善される可能性があるということです。例えば、o1-previewモデルは、GPT-4oと比較して、より多くの推論ステップを統合することで、マルチドキュメントクイズ、長文文脈学習、コードリポジトリ理解などのタスクで大幅な改善を達成している。
このことは、LongBench v2が現在のモデルの推論能力により高い要求を課していること、そして推論について考え、推論する時間を増やすことが、このような長いテキスト推論の課題に取り組む上で自然かつ重要なステップであることを示唆している。
2.RAG+ロング・コンテクスト実験

Qwen2.5とGLM-4-Plusの両モデルとも、検索ブロック数がある閾値(32kトークン、長さ512の約64ブロック)を超えると、有意な性能向上は見られないか、劣化さえすることがわかった。
このことは、単に検索される情報量を増やすだけでは、必ずしも性能向上につながらないことを示唆している。対照的に、GPT-4oは、より長い検索コンテキストを効率的に利用することができ、最適な ラグ 128kの検索長でパフォーマンスが発生する。
要約すると、深い理解と推論を必要とする長いテキストのQ&Aタスクに直面した場合、特に検索されたブロックの数がある閾値を超えた場合、RAGの使用には限界がある。LongBench v2の難易度の高い問題を効果的に処理するためには、検索された情報に依存するだけでなく、より強力な推論機能を持つ必要がある。
このことはまた、今後の研究の方向性として、外部検索に頼るだけではなく、モデル自身の長文理解・推論能力をいかに向上させるかにもっと焦点を当てる必要があることを示唆している。
私たちは、LongBench v2が長文理解と推論技術の限界を押し広げることを期待しています。私たちの論文を読み、私たちのデータを使い、より多くのことを学んでください!
ホームページ:https://longbench2.github.io
論文:https://arxiv.org/abs/2412.15204
データとコード:https://github.com/THUDM/LongBench
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事



コメントはありません