Logics-Parsing - Ali オープンソース文書解析モデル

ロジックス・パーシングとは
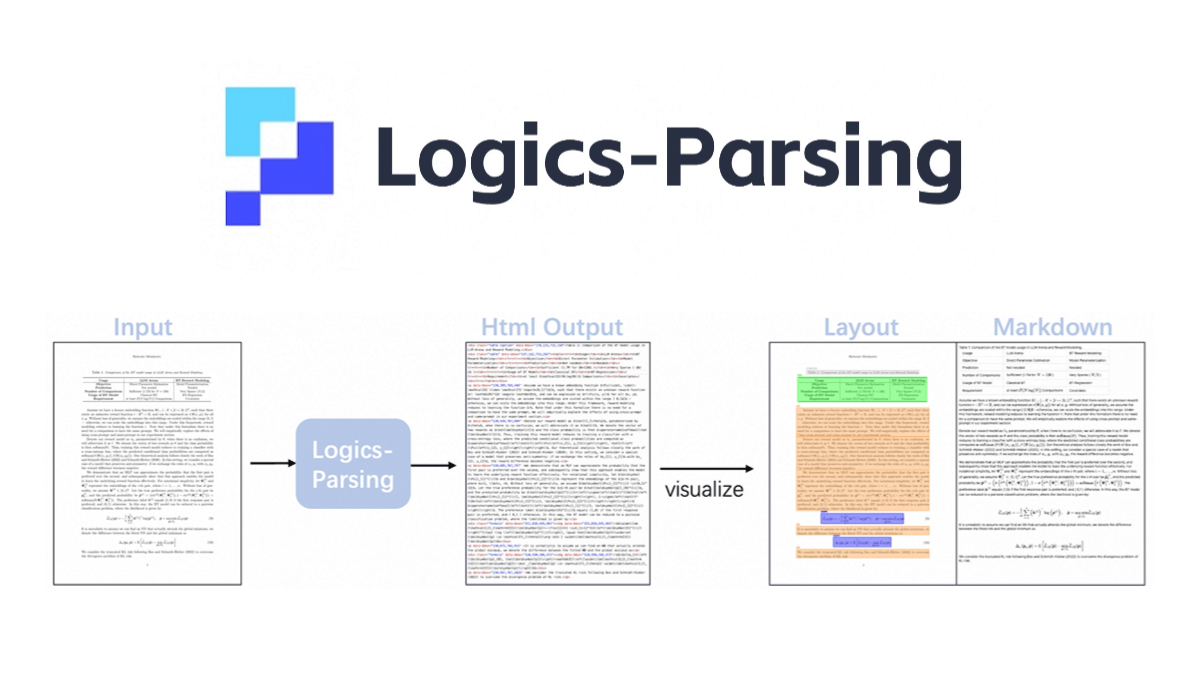
Logics-Parsingは、Qwen2.5-VL-7Bをベースとした、オープンソースのAliのエンドツーエンドの文書解析モデルです。 強化学習によって、文書のレイアウト解析と読み順推論を最適化し、PDF画像を構造化されたHTML出力に変換することができます。このモデルは2つのフェーズで学習される。第1フェーズは、構造化された出力を生成することを学習するための教師あり微調整であり、第2フェーズは、テキストの精度、レイアウト位置、読み順を最適化するためのレイアウト中心の強化学習である。このモデルはLogicsParsingBenchベンチマークで良好な結果を示し、特にプレーンテキスト、化学構造、手書きコンテンツの構文解析において他の手法を凌駕している。
ロジックス・パーシングの特徴
- エンド・ツー・エンドの解決能力複雑な多段パイプラインを使用せずに、ドキュメント画像から構造化されたHTML出力を直接生成します。
- 高度なコンテンツ認識数式、化学構造、手書き漢字などの複雑なコンテンツを正確に認識します。
- 構造化出力生成されたHTMLは、各コンテンツブロックの詳細なタグと座標を持つドキュメントの論理構造を保持します。
- 無関係な要素の自動削除ヘッダーやフッターなどの無関係な要素を自動的にフィルタリングし、核となるコンテンツに焦点を当てます。
- 学習の最適化レイアウト解析と読み順を最適化し、徹底的な研究によって構文解析の精度を高める。
- 高性能様々な複雑な文書タイプにおいて、他の既存の方法を凌駕します。
- シンプルな配置と推論インストール後、コマンドラインからモデルの重みをダウンロードし、推論を実行することができます。
ロジックス・パーシングの主な利点
- 高精度様々な種類の文書や複雑なコンテンツに対して、優れたパフォーマンスと高い精度を発揮します。
- エンド・ツー・エンドの解決多段階のパイプラインを必要とせず、文書画像から直接構造化出力を生成することで、プロセスを合理化します。
- 複雑なコンテンツを扱う強力な能力数式、化学構造、手書き中国語などの複雑なコンテンツを正確に認識し、解析する能力。
- 構造化出力結果として得られるHTML出力は、その後の処理や応用のために文書の論理構造を保持します。
- 無関係な要素の自動フィルタリングヘッダーやフッターなどの余計なコンテンツを自動的に識別して削除し、コアメッセージに焦点を当てます。
- 学習の最適化強化学習によりレイアウト解析と読み取り順序を最適化し、全体的なパフォーマンスを向上。
Logics-Parsingの公式ウェブサイトは?
- Githubリポジトリ:: https://github.com/alibaba/Logics-Parsing
- HuggingFaceモデルライブラリ:: https://huggingface.co/Logics-MLLM/Logics-Parsing
- arXivテクニカルペーパー:: https://arxiv.org/pdf/2509.19760
Logics-Parsingは誰のためにあるのか?
- (研究者学術論文や科学報告書を解析し、重要な情報を抽出するために使用します。
- 教育者教材、試験用紙、手書きノートなどを扱い、教育や学習をサポートする。
- コーポレート・アナリストビジネス文書やレポートの解析、データや情報の抽出。
- データサイエンティストデータマイニングや分析のために大量の文書データを扱う。
- 文書処理エンジニア文書処理システムを開発し、自動化を強化する。
- 学童教科書やノートを解析し、学習効率を向上させる。
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事


コメントはありません