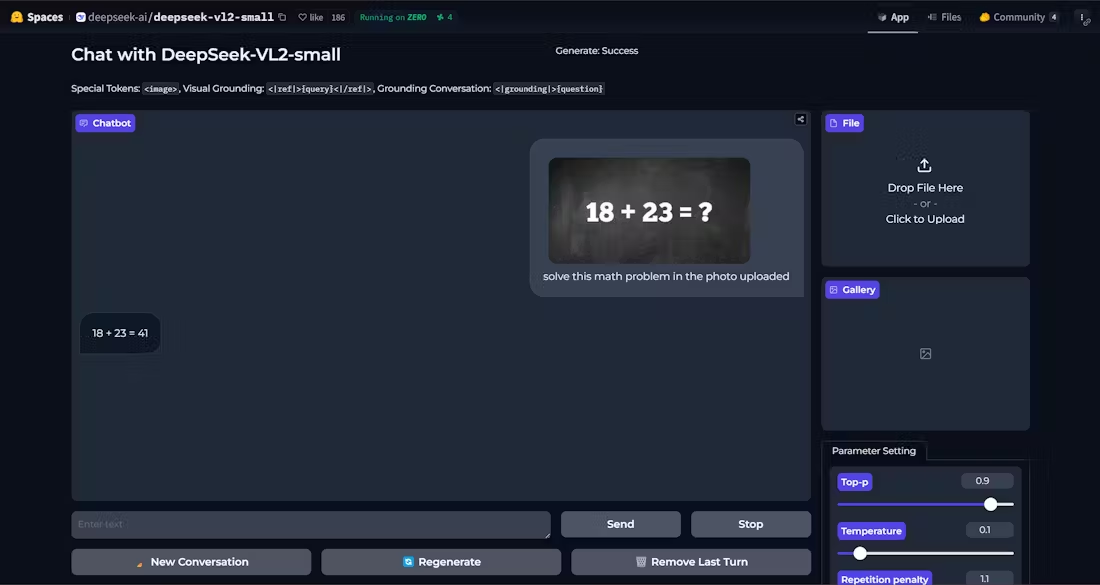
LLaVA-OneVision-1.5 - 高性能マルチモーダル理解のためのフリーでオープンソースのマルチモーダルモデル

LLaVA-OneVision-1.5とは?
LLaVA-OneVision-1.5は、EvolvingLMMS-Labチームによるオープンソースのマルチモーダルモデルであり、コンパクトな3段階のトレーニングプロセス(言語-画像のアライメント、概念の均等化と知識の注入、命令の微調整)を通じて、8Bパラメータスケールを使用して128台のA800 GPUで4日間、総コスト〜US$16Kで事前トレーニングされました。RICE-ViTビジュアルエンコーダは、ネイティブ解像度や領域レベルのきめ細かなセマンティックモデリングをサポートするほか、「コンセプトバランシング」戦略によりデータ利用を最適化するなど、革新的な機能を備えています。OCR、文書理解、その他のタスクにおいてQwen2.5-VLを上回り、初めてフルオープンソース(データ、学習ツールチェーン、評価スクリプトを含む)を実現し、マルチモーダルモデル再生の敷居を大幅に下げました。モデルコードはGitHubで公開されており、コミュニティによる低コストでの再現や二次開発をサポートしています。
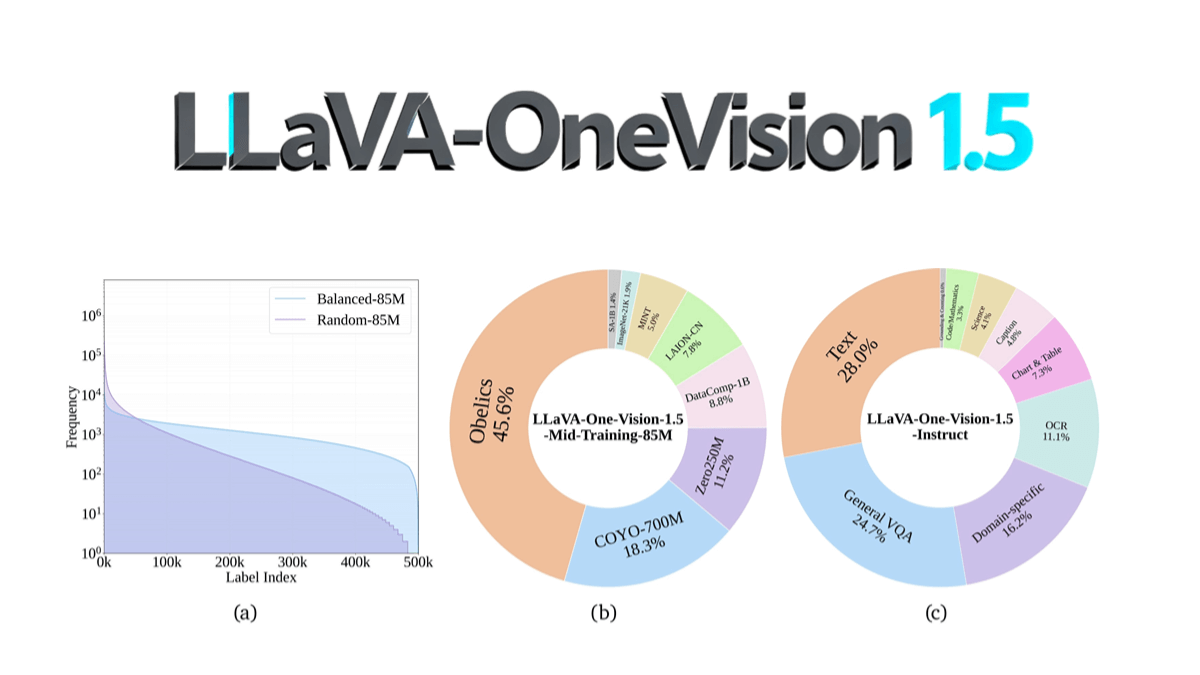
LLaVA-OneVision-1.5の特徴
- 高性能なマルチモーダル理解画像やテキスト情報を効率的に処理・理解し、幅広い複雑なシナリオに対して正確な説明と回答を生成。
- 効率的なトレーニングと低コスト最適化されたトレーニング戦略とデータパッキング技術により、高いパフォーマンスを維持しながらトレーニングコストを大幅に削減。
- 強力な指揮コンプライアンスユーザーのコマンドを正確に理解して実行することができ、タスクの汎化能力が高く、幅広いマルチモーダルなタスクに適用できる。
- 質の高いデータ主導入念に構築された事前学習とインストラクションのファインチューニング・データセットを通じて、モデルが豊富な知識と意味情報を学習するようにします。
- 柔軟な入力解像度をサポートビジョンエンコーダは可変入力解像度をサポートしているため、解像度固有の微調整が不要で、さまざまな画像サイズ要件に対応できます。
- 局所的知覚注意メカニズム画像中の局所領域に対する意味理解を、領域を意識した注意メカニズムによって強化し、細部を捉えるモデルの能力を向上させる。
- 多言語サポート国際化されたアプリケーションのニーズに対応するため、多言語入出力をサポート。
- 透明でオープンなフレームワークコード、データ、モデルの完全なリソースを提供することで、コミュニティのために低コストでの再現と検証可能な拡張を保証し、学術的および産業的な応用を促進する。
- ロングテールを見極める力データ中の出現頻度が低いカテゴリーや概念の効果的な識別と理解も可能となり、モデルの汎化能力が向上する。
- クロスモーダル検索機能テキストベースのクエリ画像または画像ベースのクエリテキストをサポートし、効率的なクロスモーダル情報検索を実現します。
LLaVA-OneVision-1.5の主な利点
- ハイパフォーマンスマルチモーダルなタスクをこなし、画像やテキスト情報を効率的に処理し、高品質なアウトプットを生み出す。
- 安い最適化されたトレーニング戦略とデータパッキング技術により、トレーニングコストを大幅に削減し、費用対効果を改善します。
- 再現性が高い完全なコード、データ、トレーニングスクリプトを提供することで、コミュニティは低コストでモデルのパフォーマンスを再現し、検証することができます。
- 効率的なトレーニングオフライン並列データパッキングとハイブリッド並列技術により、学習効率を向上させ、計算資源の無駄を削減する。
- 質の高いデータモデルが豊富な意味情報を学習できるように、大規模で高品質な事前学習と指導の微調整用データセットを構築。
- 柔軟な入力サポートビジョンエンコーダは可変入力解像度をサポートしているため、解像度固有の微調整が不要で、さまざまな画像サイズ要件に対応できます。
- エリア認識能力画像中の局所領域の意味理解を強化し、領域を意識した注意メカニズムによって細部キャプチャを改善する。
LLaVA-OneVision-1.5の公式サイトは?
- Githubアドレス:: https://github.com/EvolvingLMMs-Lab/LLaVA-OneVision-1.5
- HuggingFaceモデルライブラリ:: https://huggingface.co/collections/lmms-lab/llava-onevision-15-68d385fe73b50bd22de23713
- arXivテクニカルペーパー:: https://arxiv.org/pdf/2509.23661
- オンライン体験デモ:: https://huggingface.co/spaces/lmms-lab/LLaVA-OneVision-1.5
LLaVA-OneVision-1.5が適している人
- 研究員マルチモーダル学習、コンピュータ・ビジョン、自然言語処理に携わる研究者は、最先端の研究やアルゴリズム開発にこのモデルを利用することができる。
- 開発者ソフトウェアエンジニアやアプリケーション開発者は、LLaVA-OneVision-1.5をさまざまなアプリケーションに統合して、インテリジェントなカスタマーサービスやコンテンツ推薦などを開発することができます。
- 教育者画像解釈やマルチメディアコンテンツ作成など、教育や学習を支援するために教育現場で利用できる。
- 医療関係者医師や医学研究者は、医療効率と精度を向上させるために、医療画像解析や補助診断に使用することができます。
- コンテンツクリエーターライター、デザイナー、メディア制作者は、このモデルを使用して、クリエイティブなコンテンツ、コピー、画像の説明を生成し、クリエイティブな効率を向上させます。
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事


コメントはありません