
視覚モデルを用いた画像テキスト抽出のためのOCRプロンプト

複雑なテキスト構造、またはテキストが混在するコンテンツに直面した場合、ビジュアルモデルOCR機能を使用してコンテンツを抽出するのがよい。
マルチモーダル・マクロモデルや特殊化された視覚モデルは、画像の内容を理解し、認識タスクを実行するための指示を受け取ることができる。
OCRプロンプトは、次のツールでテストすることをお勧めします: ChatGPT 、 キミ そして クウェン2-VL(現在最も正確)
テスト画像:
この画像の複雑さは、不明瞭なjsonの部分にある。
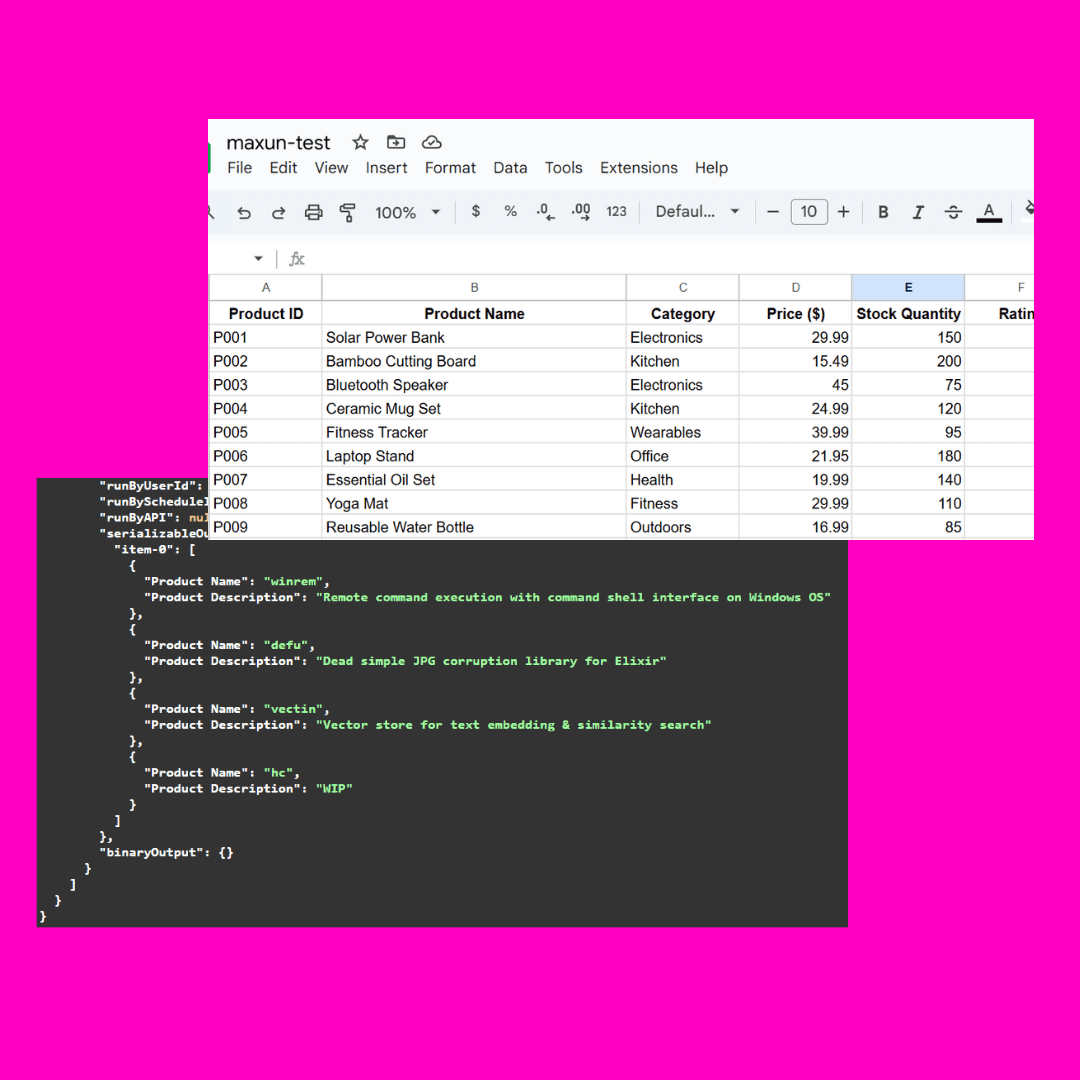
シンプルなコマンドであれば、通常は問題ない:
按照原文格式提取
コンテンツの一部のみが抽出される:
仅提取图片中的表格部分
抽出し、固定フォーマットのテキストに書き起こす:
识别图片后整理为MARKDOWN格式表格,请保持表格原始顺序、格式和语言
構造化抽出:
您的任务是将文件内容转录并格式化为 markdown。您的目标是创建一个结构良好、可读性强的 markdown 文档,该文档准确表示原始内容,同时添加适当的格式和标签。 请按照以下说明完成任务: 1. 仔细阅读整个文件内容。 2. 将内容转录为 markdown 格式,密切关注现有的格式和结构。 3. 如果您在原始内容中发现任何不清楚的格式,请自行判断添加适当的 markdown 格式以提高可读性和结构。 4. 对于表格、标题和目录,请添加以下标签: - 表格:将整个表格括在 [TABLE] 和 [/TABLE] 标签中。如果表格内容在下一页继续,请合并表格内容。 - 标题(在每页开头重复的完整字符串):括在 markdown 文件内的 [HEADER] 和 [/HEADER] 标签中。 - 目录:用 [TOC] 和 [/TOC] 标签括起来 5. 转录表格时: - 如果表格跨越多页,请将内容合并为一个连贯的表格。 - 使用适当的 markdown 表格格式,表格结构使用竖线 (|) 和连字符 (-)。 6. 不要在转录中包含分页符。 7. 保持文档的逻辑流程和结构,确保使用 markdown 标题正确格式化章节和小节(# 表示主标题,## 表示副标题等)。 8. 根据需要对其他格式元素(如粗体、斜体、列表和代码块)使用适当的 markdown 语法。 10. 仅返回 markdown 格式的解析内容,包括表格、标题和目录的指定标签。
抽出し、翻訳する:
私が最もよく使う翻訳コマンドはここで使うもので、複雑な構造のテキストを抽出するOCRにも威力を発揮する:オリジナルの書式を維持したまま、「英語の説明書テンプレート」を「中国語の説明書」に翻訳。
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事



コメントはありません