こころ:自然で滑らかな音声を生成する効率的な音声合成モデル

はじめに
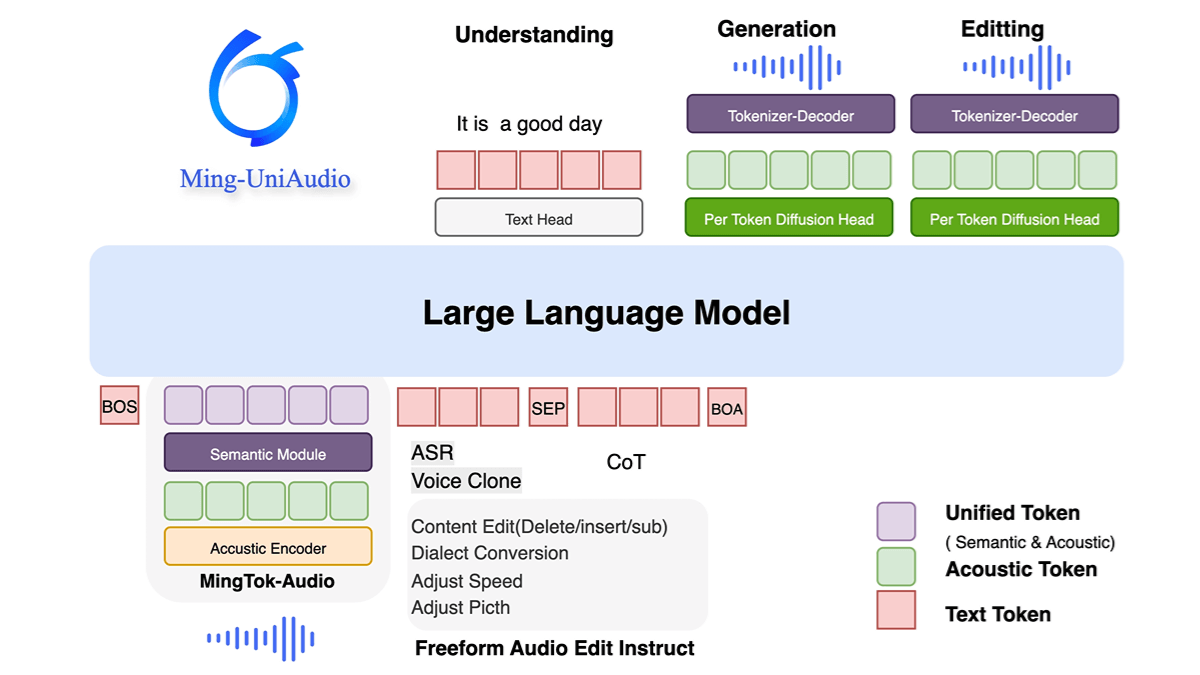
ココロ82Mは、Hugging Faceが提供する高効率な音声合成モデルで、少ないパラメータと少ないデータで高品質な音声を生成するように設計されています。このモデルは8,200万個のパラメータを持ち、Apache 2.0ライセンスの下でリリースされ、異なるスタイルや言語の音声を生成するために複数のVoicepackをサポートしています。kokoro-82MはTTS(Text-to-Speech)領域、特にEloランキングにおいて良好な性能を発揮し、以下のような結果を得ることができます。kokoro-82Mは、TTS(Text-to-Speech)領域、特にEloランキングにおいて優れた性能を発揮し、より少ない計算資源で高品質な音声合成を実現します。
ココロはAPIを包んだ:ココロTTS API: 高速音声合成のためのDocker化FastAPIラッパー (ココロ-82Mモデル)

経験:https://huggingface.co/spaces/hexgrad/Kokoro-TTS
機能一覧
- 音声合成自然で滑らかな音声出力を生成します。
- 複数のボイスパックに対応様々なボイスパックが用意されており、ユーザーは様々なボイススタイルを選択することができます。
- 効率的なモデリングより少ないパラメータとデータで高品質な音声合成を実現。
- オープンソースライセンスApache 2.0ライセンスに基づき、自由な使用と改変が認められています。
- 地域支援: Discordサーバーが用意されており、ユーザーはコミュニティで議論したり、フィードバックしたりすることができます。
ヘルプの使用
設置プロセス
- 依存関係のインストール::
git lfs install
git clone https://huggingface.co/hexgrad/Kokoro-82M
cd Kokoro-82M
apt-get -qq -y install espeak-ng > /dev/null 2>&1
pip install -q phonemizer torch transformers scipy munch
- モデルをビルドし、デフォルトのボイスパックをロードする::
from models import build_model
import torch
device = 'cuda' if torch.cuda.is_available() else 'cpu'
MODEL = build_model('kokoro-v0_19.pth', device)
VOICE_NAME = 'af' # 默认语音包
VOICEPACK = torch.load(f'voices/{VOICE_NAME}.pt', weights_only=True).to(device)
print(f'Loaded voice: {VOICE_NAME}')
- スピーチの生成::
from kokoro import generate
text = "How could I know? It's an unanswerable question. Like asking an unborn child if they'll lead a good life. They haven't even been born."
audio, out_ps = generate(MODEL, text, VOICEPACK, lang=VOICE_NAME[0])
from IPython.display import display, Audio
display(Audio(data=audio, rate=24000, autoplay=True))
使用方法
- ボイスパックを選択ココロ-82Mでは、必要に応じて様々なボイススタイルを選択できるように、様々なボイスパックを用意しています。デフォルトのボイスパックは
afこれはvoicesフォルダ内の他のボイスパックを探す。 - スピーチの生成使用
generateこの関数はテキストを入力し、音声を生成する。生成された音声は24kHzで、IPythonのディスプレイで再生することができます。 - 調整パラメーター最適な音声合成結果を得るために、必要に応じてモデルパラメータや音声パッケージを調整することができます。
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事



コメントはありません