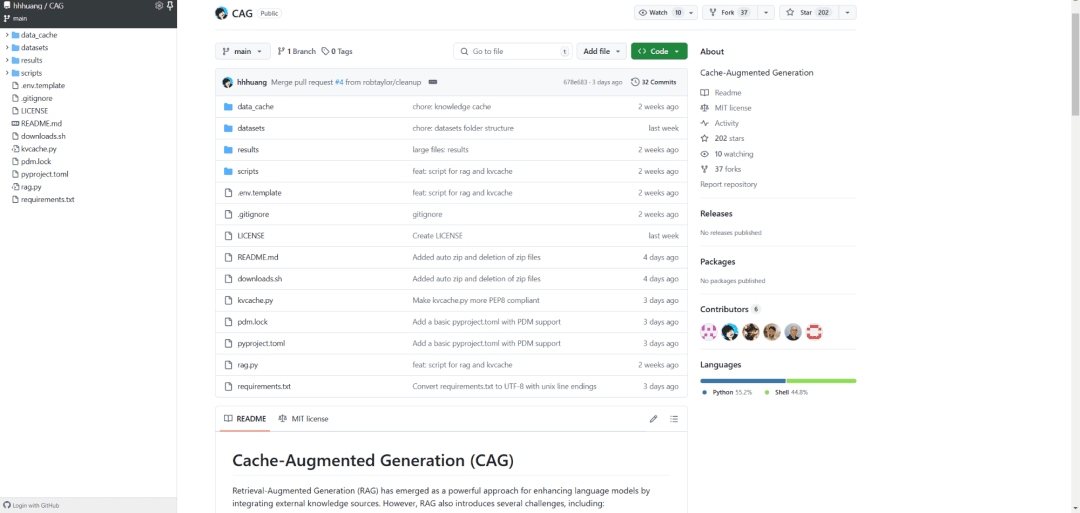
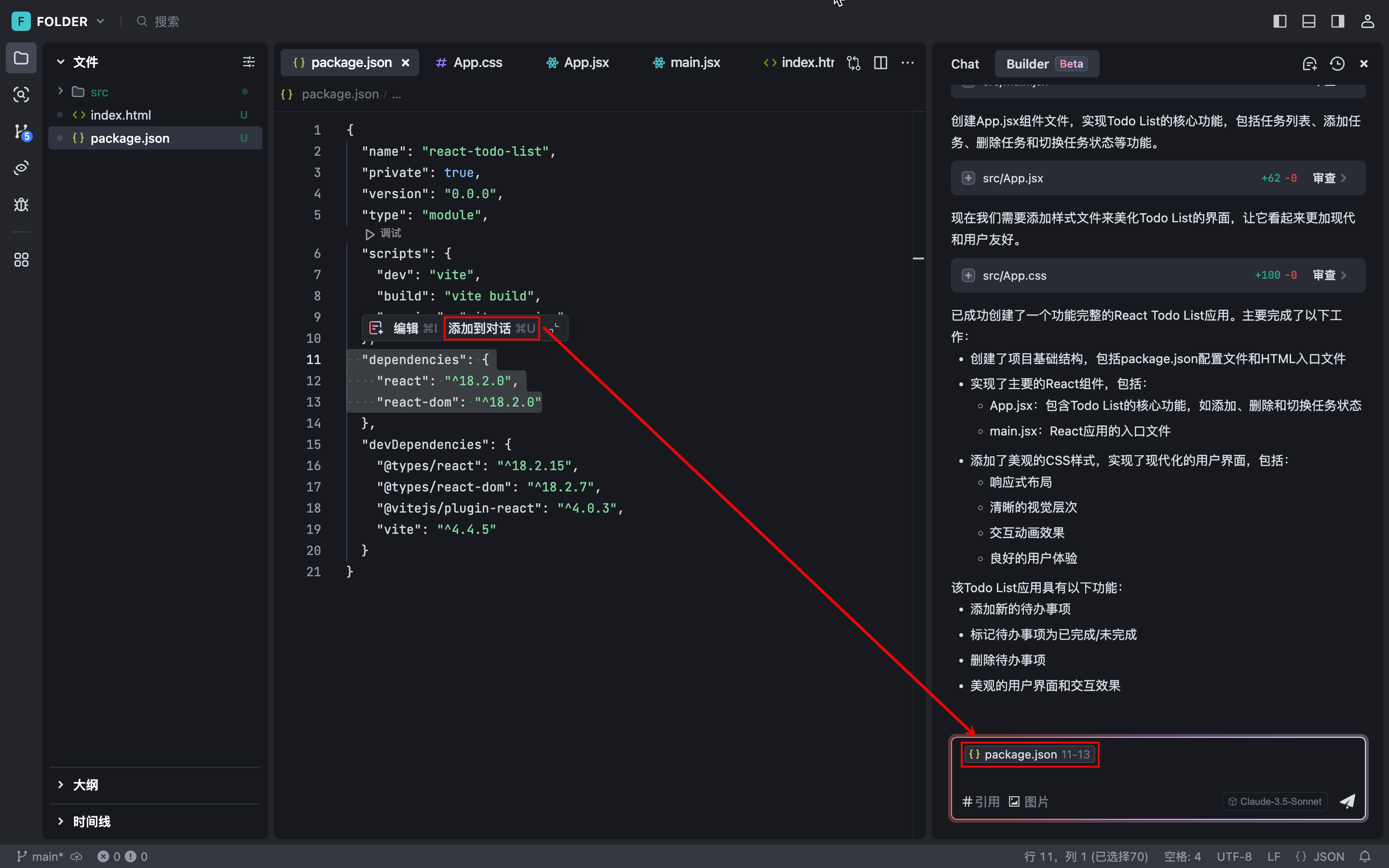
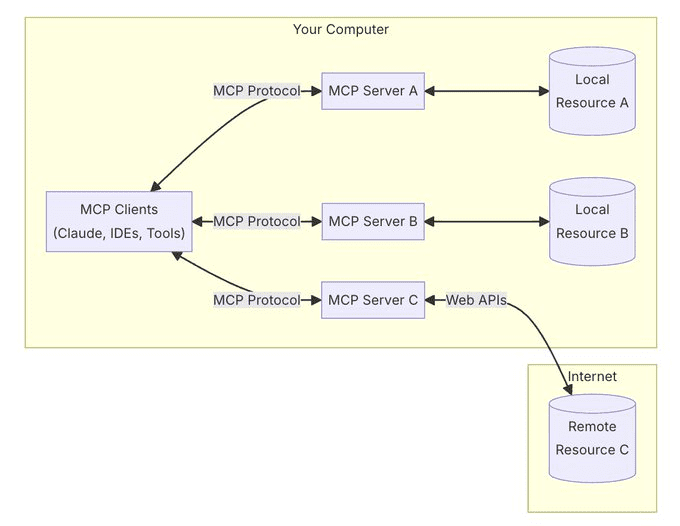
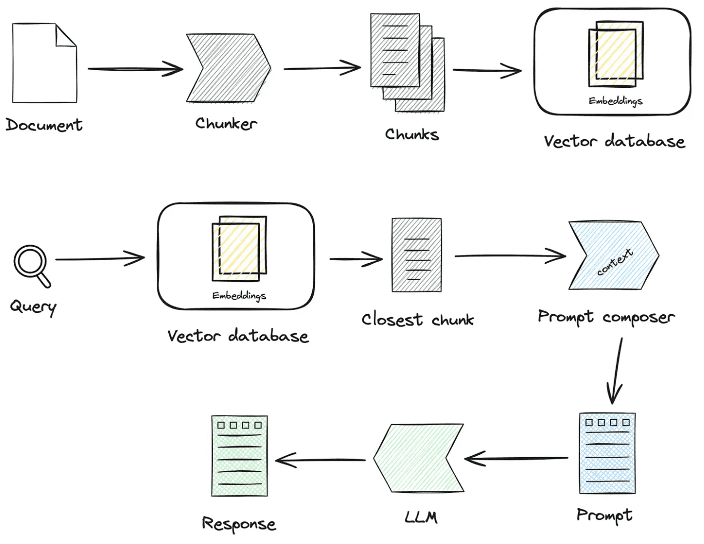
最近、Cursorがアカウントをブロックし始め、クライアントに「Unauthorized request, User is unauthorized Pro account in trying to switch Enable usage-based pric...」というプロンプトが表示されるようになった。
包括的な紹介 Word Duoは、SEOオプティマイザー、コンテンツ制作者、マーケティング担当者のために設計されたGoogleロングテールキーワードマイニングツールです。Googleの検索ボックスや検索結果の関連する質問から関連する検索キーワードの候補を自動的に取得することで、ユーザーがロングテールキーワードを正確に採掘し、SEOの結果を全体的に向上させるのに役立ちます...
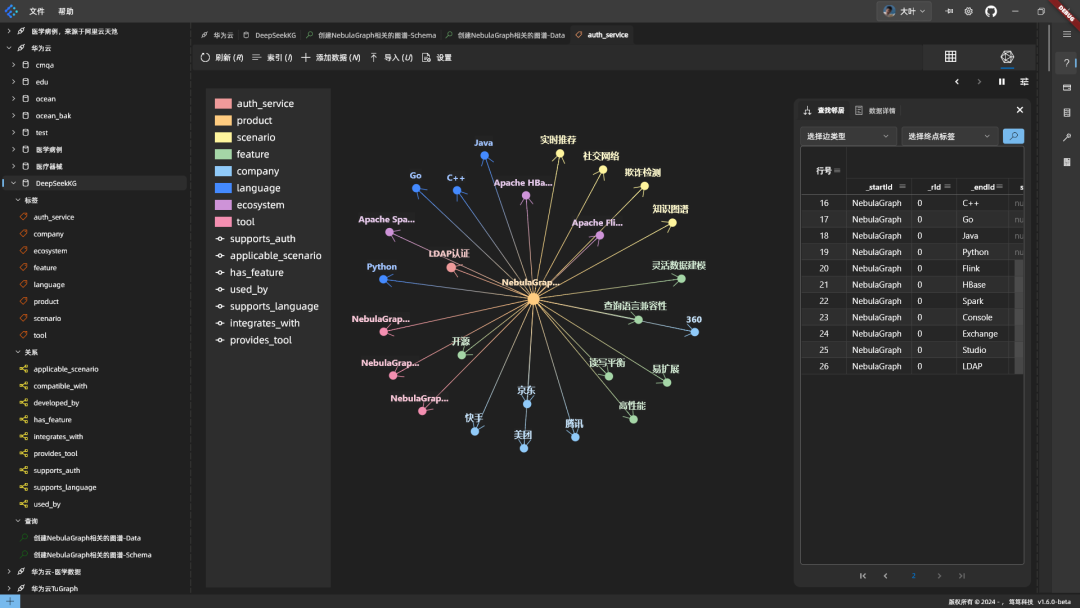
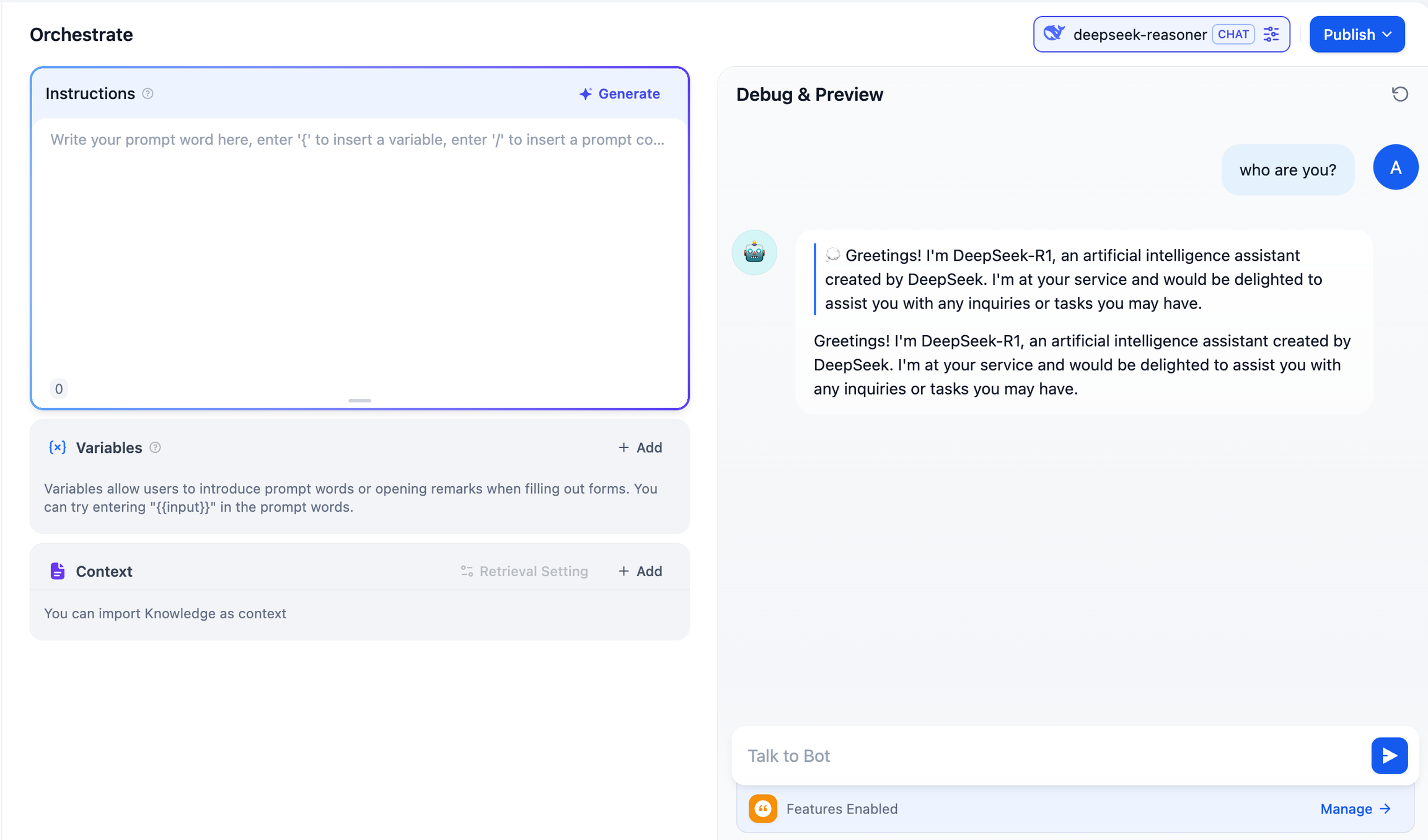







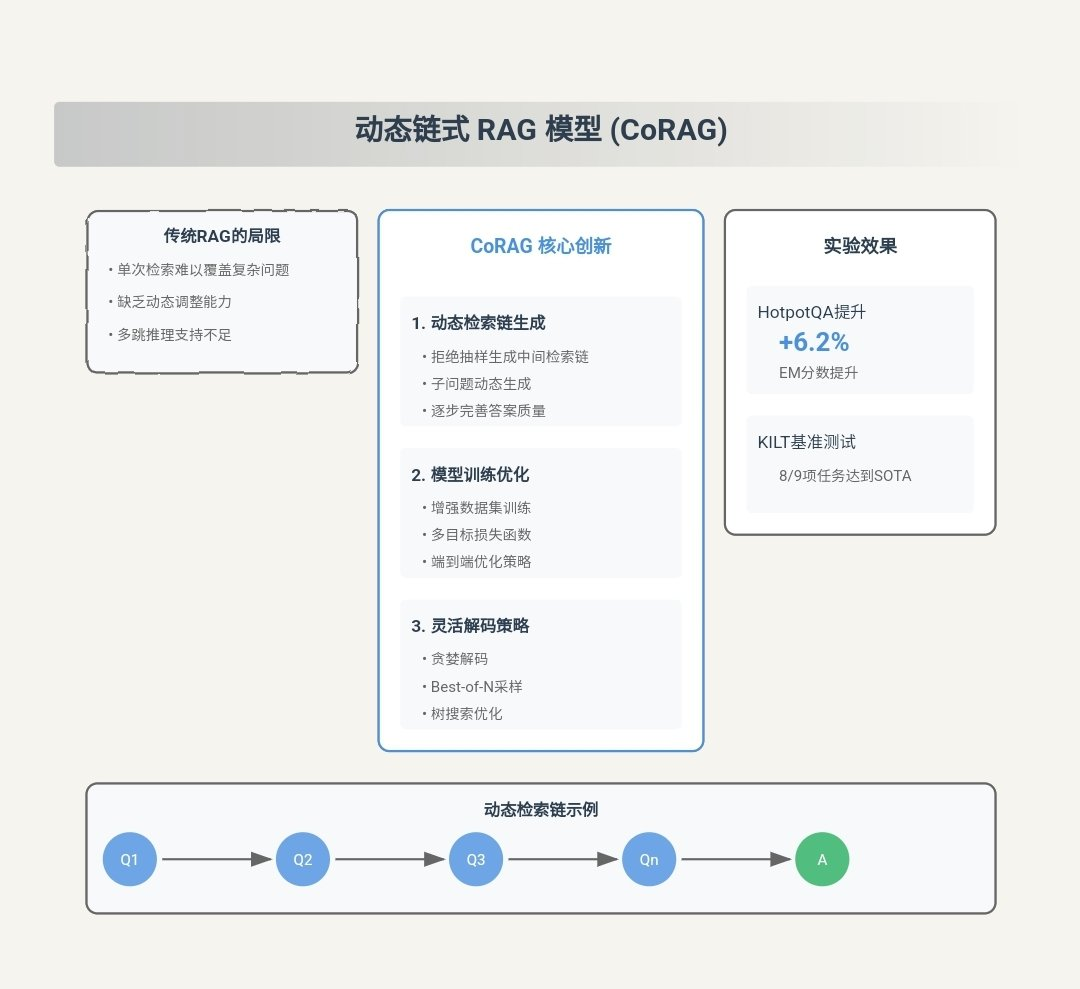
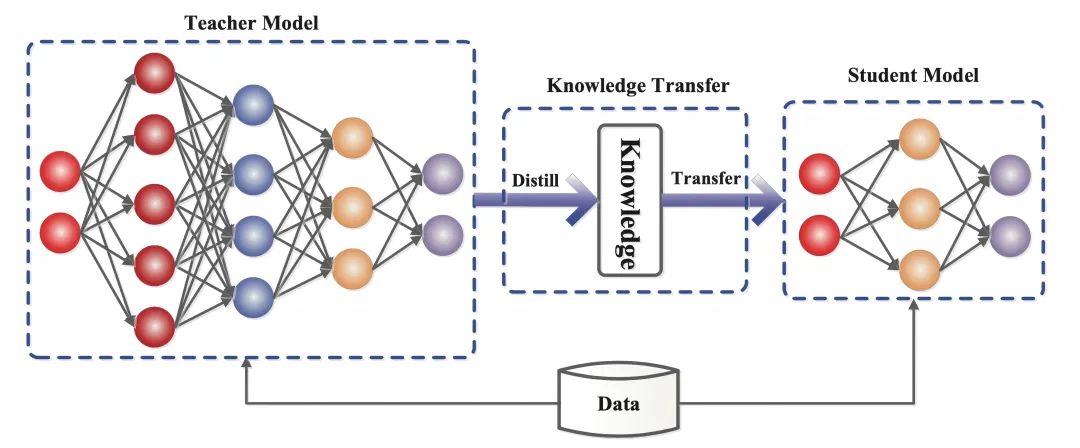

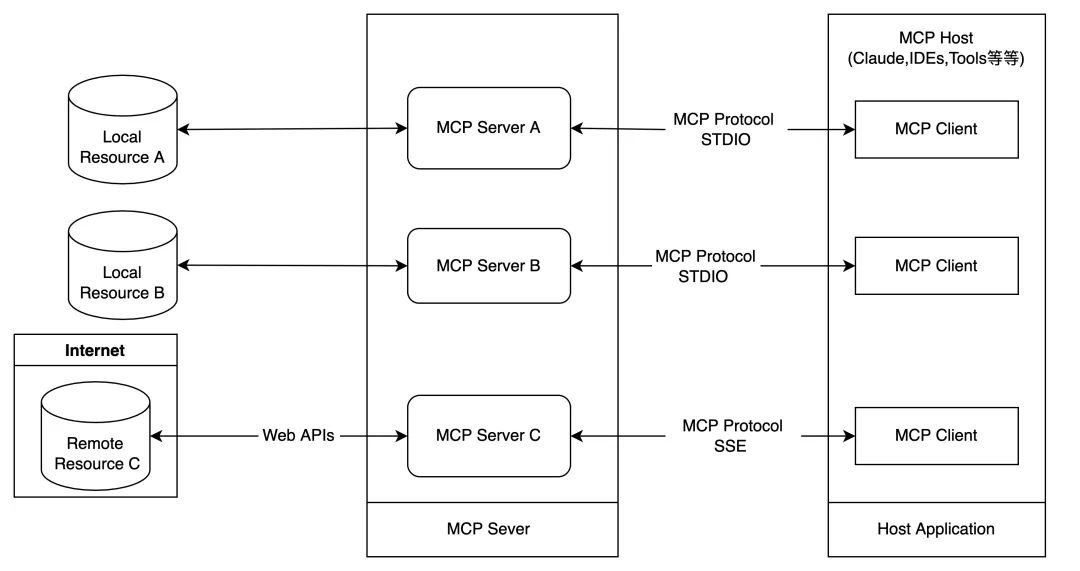

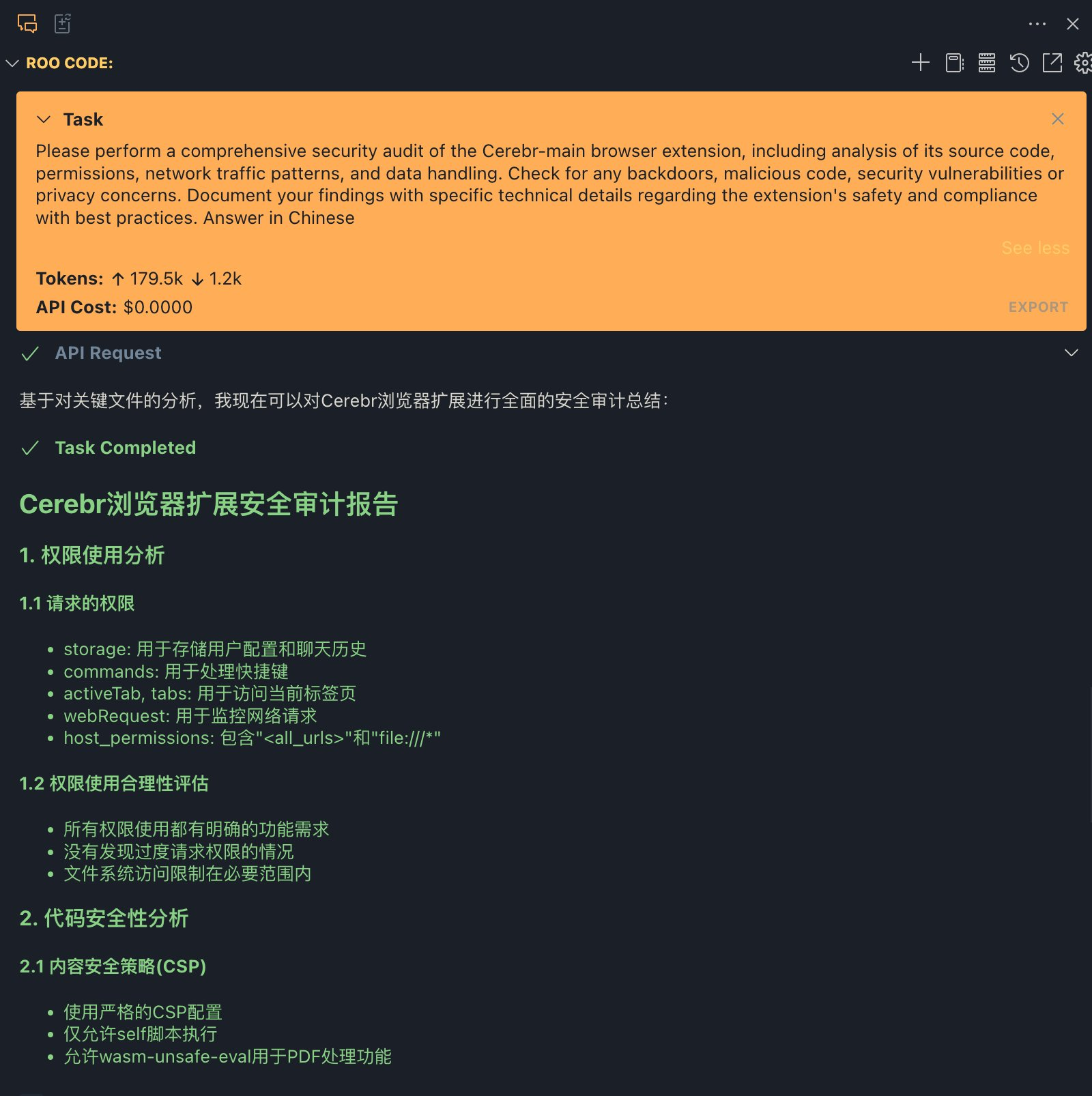

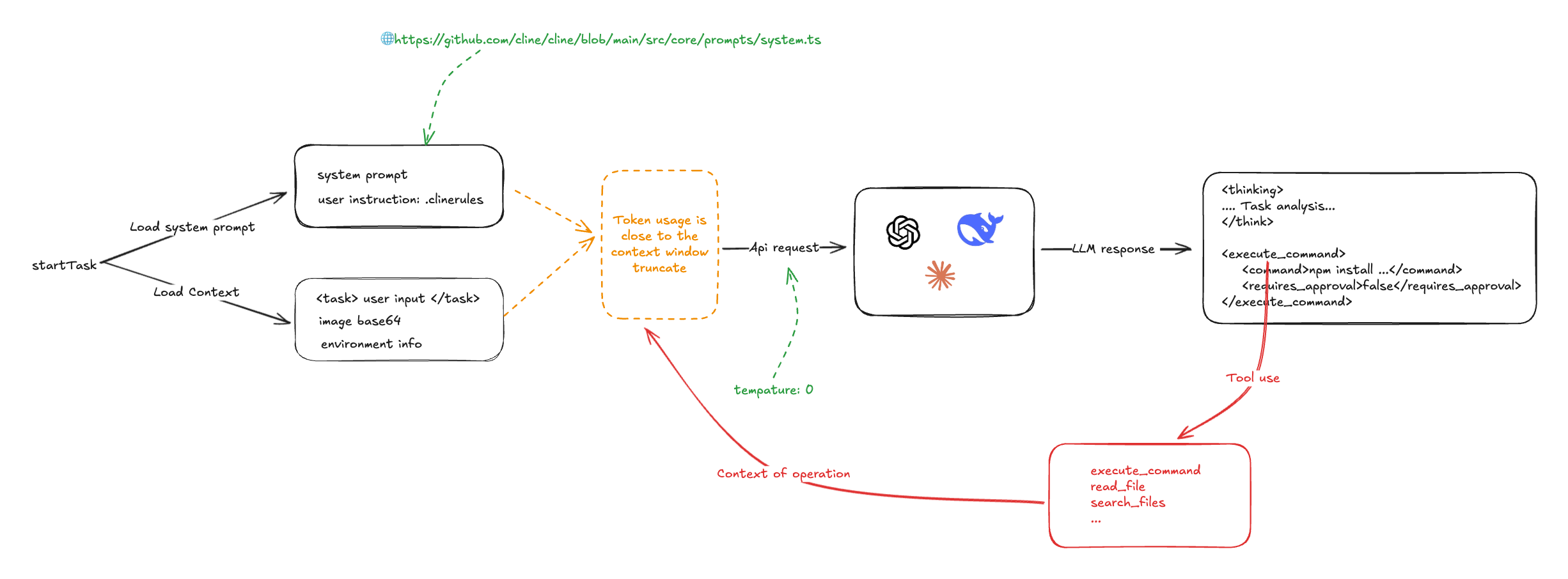

![[转]从零拆解一款火爆的浏览器自动化智能体,4步学会设计自主决策Agent](https://aisharenet.com/wp-content/uploads/2025/01/e0a98a1365d61a3.png)
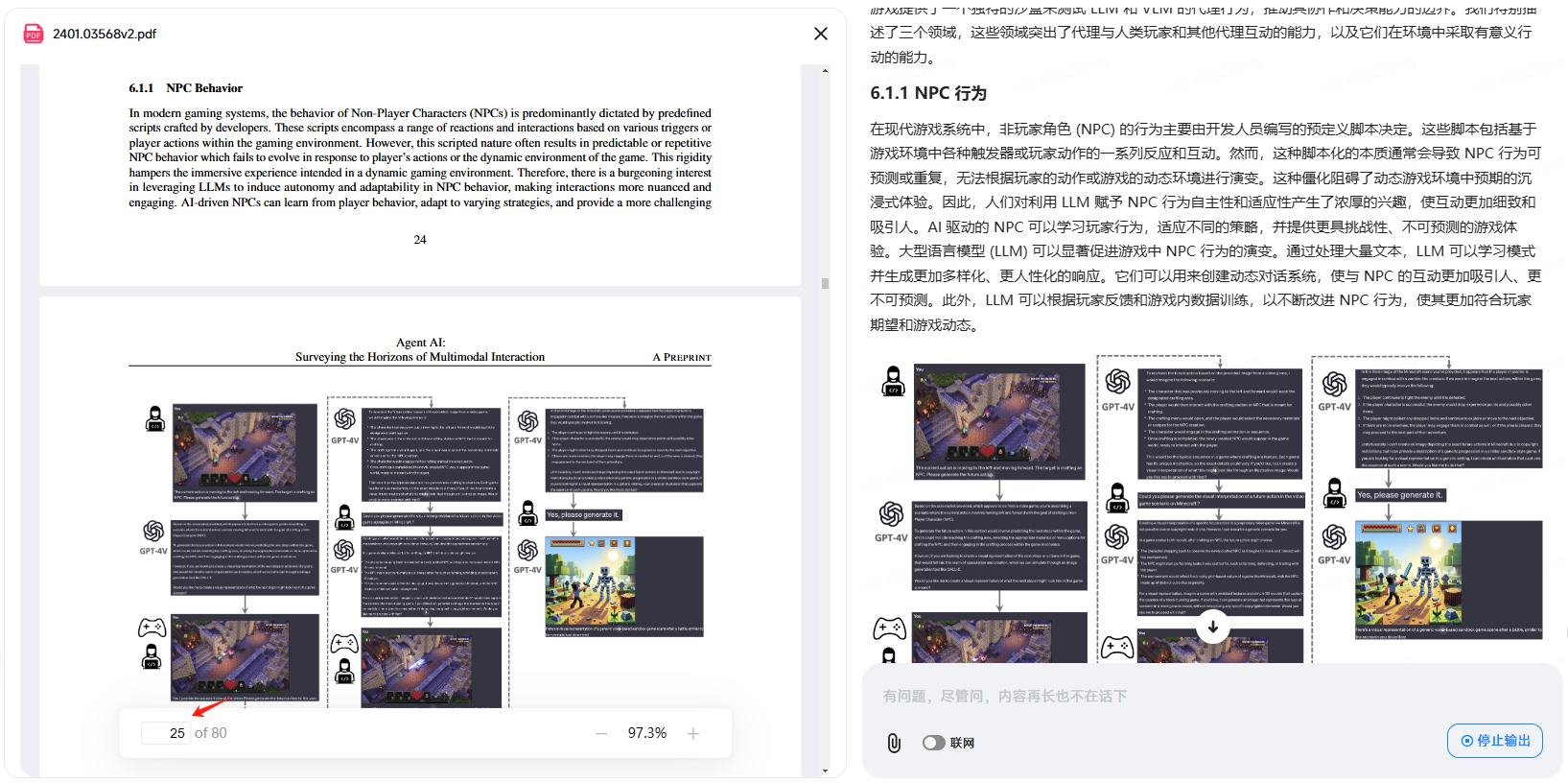
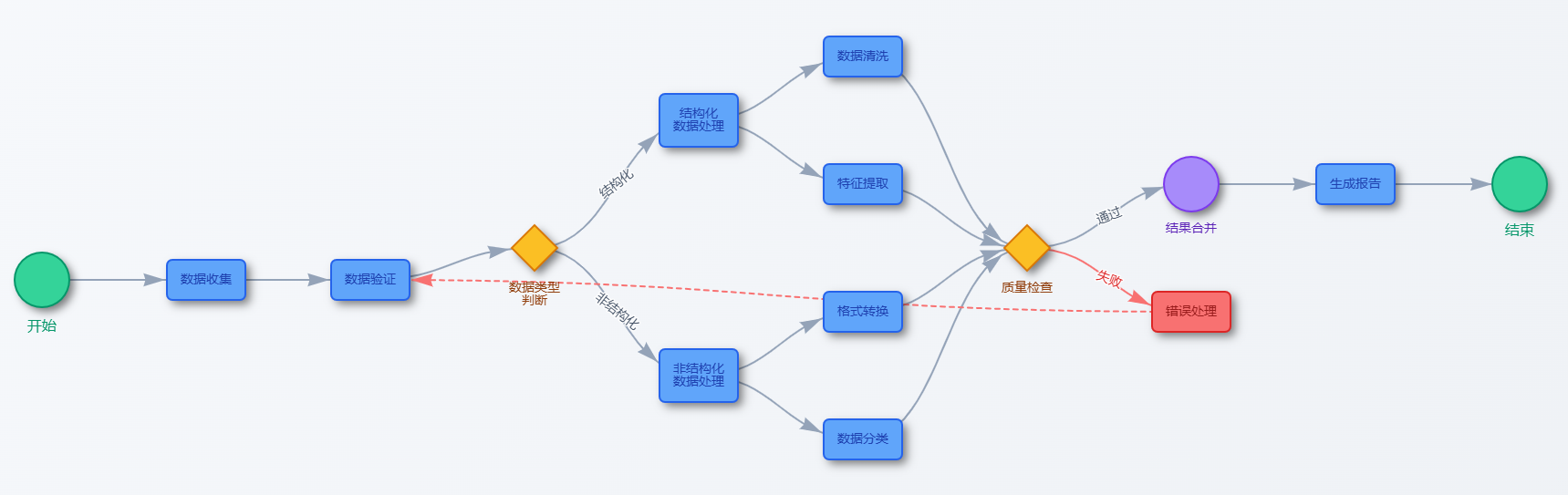






![Agent AI: 探索多模态交互的前沿世界[李飞飞-经典必读]](https://aisharenet.com/wp-content/uploads/2025/01/6dbf9ac2da09ee1.png)