
キミがMoBAを立ち上げる:無限のコンテキストを可能にする画期的な方法!

Mixture of ExpertsとSparse attentionにより、事実上無限のコンテクストが可能になる。これにより、RAG AIエージェントはコンテキストの制限を受けることなく、コードベースやドキュメント全体を食い尽くすことができる。
📌 ロング・コンテクスト・アテンションへの挑戦
シーケンスが非常に大きくなると、トランスフォーマーは依然として大きな計算負荷に直面する。デフォルトのアテンション・モデルは、それぞれの トークン 他のすべてのトークンと比較すると、計算コストが2次関数的に増加する。このオーバーヘッドは、コードベース全体、複数の章からなる文書、または大量の法的テキストを読む場合に問題となる。
📌 モバ
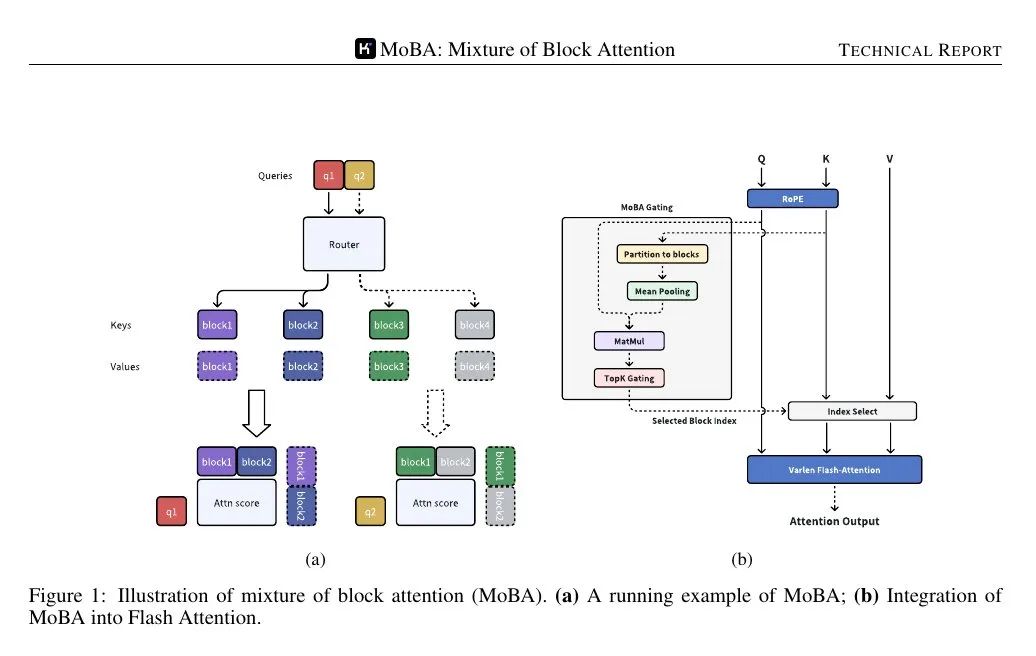
MoBA (Mixture of Block Attention)はMixture of Expertsの概念を注意メカニズムに応用したものである。このモデルは入力シーケンスを複数のブロックに分割し、学習可能なゲーティング関数が各クエリトークンと各ブロックの相関スコアを計算する。最もスコアの高いブロックのみがアテンション計算に使用されるため、完全なシーケンスの各トークンに注意を払う必要がない。
ブロックはシーケンスを等しいスパンに分割することで定義される。各クエリトークンは、各ブロック内のキーの集約表現(例えば、平均プーリングを使用)を見て、重要度をランク付けし、詳細な注意計算のためにいくつかのブロックを選択する。クエリを含むブロックは常に選択される。因果マスキングは、トークンが将来の情報を見ないようにし、左から右への生成順序を維持する。
📌 スパースとフルアテンションのシームレスな切り替え
MoBAは標準的なアテンション・メカニズムに取って代わるものだが、パラメータの数は変わらない。標準的な 変圧器 インターフェイスは互換性があり、スパースとフルアテンションを異なるレイヤーやトレーニングフェーズ間で切り替えることができる。一部のレイヤーは、特定のタスク(例えば、教師ありの微調整)のためにフルアテンションを予約することができるが、ほとんどのレイヤーは計算コストを削減するためにMoBAを使用する。
📌 これは、標準的なアテンションコールを置き換えることで、より大きなTransformerスタックに適用される。ゲーティングメカニズムは、各クエリが少数のブロックにのみフォーカスすることを保証する。因果関係は、将来のブロックをフィルタリングし、クエリの現在のブロック内でローカルマスクを適用することで処理される。
📌 下図は、クエリーがキー/値のいくつかの "エキスパート "ブロックにのみルーティングされ、シーケンス全体にはルーティングされないことを示している。 ゲーティングメカニズムは、各クエリを最も関連性の高いブロックに割り当てるため、アテンション計算の複雑さを2次関数からサブ2次関数に減らすことができる。
📌 ゲーティング機構は、各クエリと各ブロックの凝集表現との相関スコアを計算する。 そして、各クエリに対して、どれだけ後ろのブロックであっても、最もスコアの高い上位k個のブロックを選択する。
クエリごとに数ブロックしか処理されないため、計算はまだ二次関数的であるが、ゲーティングスコアが高い相関を示した場合、モデルはまだ現在のブロックから遠く離れたトークンにジャンプすることができる。
PyTorchの実装
この擬似コードは、キーと値をブロックに分割し、各ブロックの平均プール表現を計算し、クエリ(Q)とプール表現を掛け合わせることでゲーティングスコア(S)を計算する。
次に、クエリが未来のブロックに焦点を当てられないようにするために因果マスクを適用し、各クエリに対して最も関連性の高いブロックを選択するためにtop-k演算子を使用し、効率的な注意計算のためにデータを整理する。
📌 フラッシュ・アテンション をそれぞれ自己注意ブロック(現在位置)とMoBA選択ブロックに適用し、最後にオンラインソフトマックスを用いて出力を統合した。
最終的な結果は、標準的な注意の完全な二次計算コストを回避しながら、因果構造を保持し、長距離依存性を捕捉する疎な注意メカニズムである。

このコードは、専門家混合ロジックとスパース・アテンションを組み合わせることで、各クエリが少数のブロックにのみ集中するようにしている。
ゲーティング・メカニズムは、各ブロックとクエリをスコアリングし、上位k人の「エキスパート」を選択することで、キーと値の比較回数を減らす。
これにより、注意の計算オーバーヘッドを二次関数以下のレベルに保ち、計算やメモリーの負担を増やすことなく、非常に長い入力を処理することができる。
同時に、ゲーティングメカニズムは、クエリが必要なときに遠くのトークンにフォーカスできることを保証し、グローバルコンテキストを処理するTransformerの能力を維持する。
このブロックとゲーティングに基づく戦略は、まさにMoBAがLLMで無限に近いコンテキストを実装する方法である。

実験的観察
MoBAを使用したモデルは、言語モデリングの損失と下流タスクのパフォーマンスにおいて、完全注意とほぼ同等である。この結果は、コンテキストの長さが数十万から数百万のトークンであっても一貫している。テールトークン」で評価した実験では、クエリが関連するチャンクを特定する際に、重要な長距離依存関係が依然として捕捉されることが確認された。
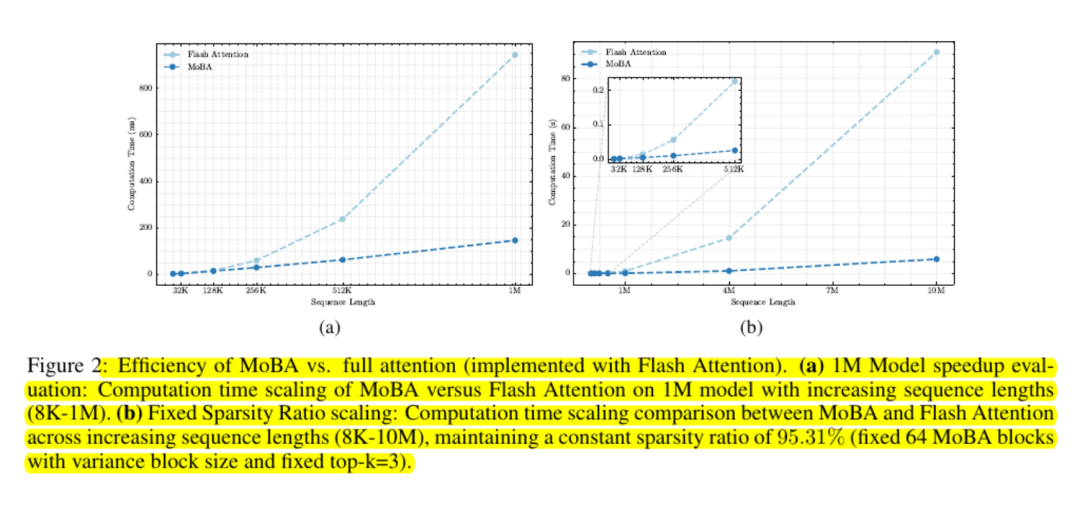
スケーラビリティ・テストによれば、コスト曲線は二次曲線以下である。研究者たちは、100万トークンで最大6倍のスピードアップ、その範囲外ではより大きなスピードアップを報告している。
MoBAは、完全なアテンション・マトリクスの使用を避け、ブロック・ベースの計算のために標準的なGPUカーネルを利用することで、メモリ・フレンドリーを維持している。
最終見解
MoBAは、どのブロックが重要かをクエリに学習させ、それ以外は無視するというシンプルなアイデアによって、アテンション・オーバーヘッドを削減している。
これは標準的なソフトマックスベースの注意インターフェースを維持し、硬直したローカルモデルの強制を避ける。多くの大規模な言語モデルは、プラグアンドプレイ方式でこのメカニズムを統合することができる。
このため、MoBAは、事前学習の重みを大きく変更したり、再学習のオーバーヘッドを多く消費したりすることなく、コードベース全体のスキャンや巨大な文書の要約など、非常に長いコンテキストを処理する必要がある作業負荷にとって非常に魅力的である。

© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事



コメントはありません