
KAG: ハイブリッド知識グラフとベクトル検索のための専門知識ベースQ&Aフレームワーク

はじめに
KAG (Knowledge Augmented Generation)は、OpenSPGエンジンと大規模言語モデル(LLMs)に基づいた、論理的なフォームに導かれた推論と検索のフレームワークです。このフレームワークは、従来のRAG(Retrieval Augmented Generation)ベクトル類似度計算モデルの欠点を効果的に克服し、専門的なドメイン知識ベースのための論理的な推論と事実質問ソリューションを構築するために特別に設計されています。KAGは、知識グラフとベクトル検索の相補的な強みを双方向の4つの方法でLLMと知識グラフを強化します:LLMに適した知識表現、知識グラフと生のテキストフラグメント間の相互インデクシング、ハイブリッド推論ソルバ。インデクシング、ハイブリッド推論ソルバー、妥当性評価メカニズム。このフレームワークは、数値計算、時間関係、エキスパートルールなどの複雑な知識論理問題を扱うのに特に適しており、専門的なドメインアプリケーションに対して、より正確で信頼性の高い質問応答機能を提供する。

機能一覧
- 複雑な論理的推論をサポートする能力
- ナレッジグラフとベクトル検索のハイブリッド検索メカニズムの提供
- LLMに適した知識表現変換の実装
- 知識構造とテキストブロックの双方向インデックスをサポート
- LLM推論、知的推論、数学的論理推論の統合
- 信頼性評価と検証のメカニズムを提供する
- マルチホップQ&Aと複雑なクエリ処理をサポート
- 専門領域の知識ベースのためのカスタマイズされたソリューションの提供
ヘルプの使用
1.環境準備
まず最初にすべきことは、お使いのシステムが以下の要件を満たしていることを確認することです:
- Python 3.8以上
- OpenSPGエンジン環境
- 大規模言語モデル用APIインターフェースをサポート
2.インストール手順
- クローン・プロジェクト・ウェアハウス
git clone https://github.com/OpenSPG/KAG.git
cd KAG
- 依存パッケージをインストールします:
pip install -r requirements.txt
3.フレームワーク使用プロセス
3.1 知識ベースの準備
- 専門領域の知識データのインポート
- 知識グラフモデルの設定
- テキスト索引システムの構築
3.2 クエリー処理
- 質問入力:システムはユーザーから自然言語による質問を受け取る。
- 論理形式の変換:標準化された論理式への問題の変換
- 混合検索:
- ナレッジグラフ検索の実行
- ベクトル類似検索の実行
- 検索結果の統合
3.3 推論プロセス
- 論理的推論:混合推論ソルバーによる多段階推論
- 知識融合:LLM推論と知識グラフ推論の結果を組み合わせる
- 答えの生成:最終的な答えの形成
3.4 信頼性の保証
- 回答検証
- 推論経路トレース
- 信頼性評価(数学)
4.高度な機能の使用
4.1 カスタマイズされた知識表現
知識表現形式は、LLMとの互換性を確保しながら、専門分野のニーズに応じてカスタマイズすることができます:
# 示例代码
knowledge_config = {
"domain": "your_domain",
"schema": your_schema_definition,
"representation": your_custom_representation
}
4.2 推論ルールの構成
ドメイン固有のロジックを扱うために、特殊な推論ルールを設定することができる:
# 示例代码
reasoning_rules = {
"numerical": numerical_processing_rules,
"temporal": temporal_reasoning_rules,
"domain_specific": your_domain_rules
}
5.ベストプラクティス
- ナレッジベース・データの品質と完全性の確保
- 検索戦略の最適化による効率化
- ナレッジベースの定期的な更新とメンテナンス
- システムの性能と精度を監視する
- 継続的な改善のためにユーザーからのフィードバックを収集する
6.一般的な問題の解決
- 検索効率の問題が発生した場合は、インデックス・パラメータを適切に調整することができます。
- 複雑なクエリに対しては、段階的推論ストラテジーを使用することができる。
- 推論結果が不正確な場合、知識表現とルール構成をチェックする
KAGプロジェクト・プレゼンテーション
1.はじめに
数日前、AntはKnowledge Augmented Generation(KAG:知識拡張ジェネレーション)と呼ばれる専門的なドメイン知識サービスフレームワークを正式にリリースした。 ラグ 技術スタックにはいくつかの課題がある。
このフレームワークのウォームアップのアリから、私はKAGのコア機能のいくつか、特に論理的なシンボリック推論と知識の整列にもっと興味を持っている、既存の主流のRAGシステムでは、議論のこれらの2つのポイントは、あまりにも多く、このオープンソースを活用し、波の研究を急いでいないようだ。
- KAGの論文アドレス:https://arxiv.org/pdf/2409.13731
- KAGプロジェクトのアドレス:https://github.com/OpenSPG/KAG
2.フレームワークの概要
コードを読む前に、フレームワークの目標と位置づけを簡単に見ておこう。
2.1 何が、なぜ?
実際、KAGフレームワークを目にしたとき、多くの人が最初に思い浮かべる疑問は、なぜRAGではなくKAGなのかということだと思う。関連記事や論文によると、KAGフレームワークは主に、専門領域の知識サービスにおける大規模モデルが直面している現在の課題のいくつかを解決するために設計されている:
- LLMは批判的思考能力を持たず、推論能力に欠ける
- 事実、論理、精度の誤り、モデルの振る舞いを制約するために定義済みのドメイン知識構造を使用できない。
- 一般的なRAGは、LLMの錯覚、特に秘密裏に誤解を招くような情報への対処にも苦慮している。
- 専門知識サービスの課題と要件、厳格で統制された意思決定プロセスの欠如
したがって、アントチームは、プロフェッショナルな知識サービスのフレームワークは、以下のような特徴を持たなければならないと考えている:
- 知識の境界の完全性、知識の構造と意味の明確さなど、知識の正確性を保証することが重要である;
- 論理的な厳密さ、時間的感度、数値的感度が求められる;
- 知識ベースの意思決定を行う際に、完全な裏付け情報へのアクセスを容易にするためには、完全な文脈情報も必要である;
AntのKAGの公式な位置づけは、「プロフェッショナル・ドメイン知識補強サービス・フレームワーク」であり、特に大規模な言語モデルと知識グラフの現在の組み合わせのために、以下の5つの分野を強化する。
- LLMフレンドリーな知識の強化
- 知識グラフと原文断片との相互インデックス構造
- 論理記号誘導型ハイブリッド推論エンジン
- 意味推論に基づく知識アライメント機構
- KAGモデル
このオープンソースリリースは、最初の4つのコア機能を完全にカバーしている。
KAGの命名の問題に戻ると、私は個人的に、それはまだ知識オントロジーの概念を強化することかもしれないと推測している。公式の説明や実際のコード実装を見る限り、KAGフレームワークは、構築段階であれ推論段階であれ、RAG技術スタックの既知の問題点を可能な限り改善するために、知識そのものから、完全かつ厳密な論理リンクを構築することを常に強調している。
2.2 何が(どのように)達成されるのか?
KAGフレームワークは、KAG-Builder、KAG-Solver、KAG-Modelの3つの部分から構成されている:
- KAG-Builderはオフライン・インデックス作成に使用され、上記の機能1および2を含む:知識表現の強化、相互インデックス構造。
- KAG-Solverモジュールは、3番目と4番目の機能をカバーする:論理-記号ハイブリッド推論エンジン、知識整列メカニズム。
- 一方KAG-Modelは、エンド・ツー・エンドのKAGモデルを構築しようとするものだ。
3.ソースコード解析
このオープンソースには、主にKAG-BuilderとKAG-Solverの2つのモジュールが含まれ、builderとsolverの2つのサブディレクトリのソースコードに直接対応しています。
実際にコードを勉強する際には、まず examples まずディレクトリから始めてフレームワーク全体の流れを理解し、特定のモジュールに深く入っていく。いくつかのデモのエントリーファイルへのパスは似ています。 kag/examples/medicine/builder/indexer.py も kag/examples/medicine/solver/evaForMedicine.pyビルダーが異なるモジュールを組み合わせていることは明らかである。 kag/solver/logic/solver_pipeline.py.
3.1 KAG-Builder
まずはカタログの全構成を掲載しよう。
❯ tree .
.
├── __init__.py
├── component
│ ├── __init__.py
│ ├── aligner
│ │ ├── __init__.py
│ │ ├── kag_post_processor.py
│ │ └── spg_post_processor.py
│ ├── base.py
│ ├── extractor
│ │ ├── __init__.py
│ │ ├── kag_extractor.py
│ │ ├── spg_extractor.py
│ │ └── user_defined_extractor.py
│ ├── mapping
│ │ ├── __init__.py
│ │ ├── relation_mapping.py
│ │ ├── spg_type_mapping.py
│ │ └── spo_mapping.py
│ ├── reader
│ │ ├── __init__.py
│ │ ├── csv_reader.py
│ │ ├── dataset_reader.py
│ │ ├── docx_reader.py
│ │ ├── json_reader.py
│ │ ├── markdown_reader.py
│ │ ├── pdf_reader.py
│ │ ├── txt_reader.py
│ │ └── yuque_reader.py
│ ├── splitter
│ │ ├── __init__.py
│ │ ├── base_table_splitter.py
│ │ ├── length_splitter.py
│ │ ├── outline_splitter.py
│ │ ├── pattern_splitter.py
│ │ └── semantic_splitter.py
│ ├── vectorizer
│ │ ├── __init__.py
│ │ └── batch_vectorizer.py
│ └── writer
│ ├── __init__.py
│ └── kg_writer.py
├── default_chain.py
├── model
│ ├── __init__.py
│ ├── chunk.py
│ ├── spg_record.py
│ └── sub_graph.py
├── operator
│ ├── __init__.py
│ └── base.py
└── prompt
├── __init__.py
├── analyze_table_prompt.py
├── default
│ ├── __init__.py
│ ├── ner.py
│ ├── std.py
│ └── triple.py
├── medical
│ ├── __init__.py
│ ├── ner.py
│ ├── std.py
│ └── triple.py
├── oneke_prompt.py
├── outline_prompt.py
├── semantic_seg_prompt.py
└── spg_prompt.py
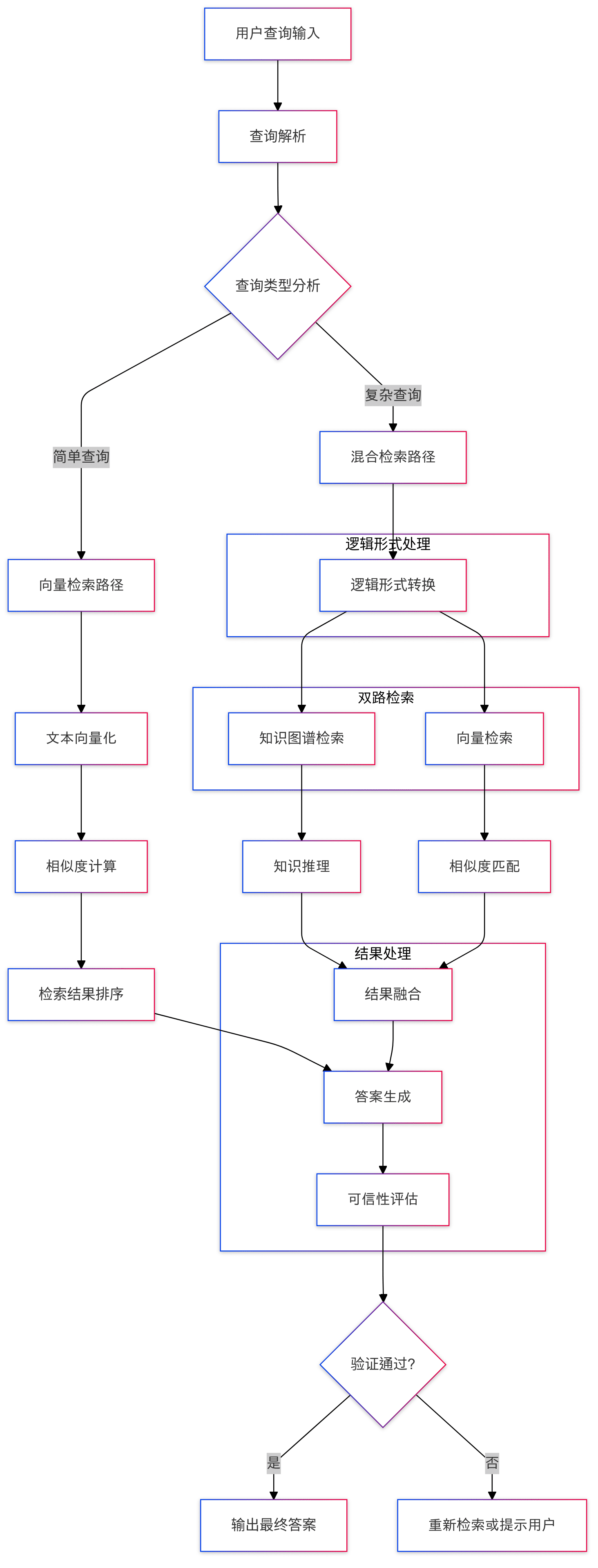
ビルダー・セクションは幅広い機能をカバーしているので、ここではより重要なコンポーネントのひとつだけを取り上げる。 KAGExtractor 基本的なフローチャートを以下に示す:

ここで行われている主なことは、構造化されていないテキストから構造化された知識への知識グラフを、大規模なモデルを用いて自動的に作成することである。
- まず、エンティティ認識モジュールがあり、あらかじめ定義された知識グラフ・タイプに対して、まず特定のエンティティの認識が行われ、続いて一般的な名前付きエンティティの認識が行われる。この2階層識別メカニズムにより、ドメイン固有エンティティが捕捉され、汎用エンティティが見逃されないようにする。
- マッピングの構築プロセスは、実際には以下のように行われる。
assemble_sub_graph_with_spg_recordsメソッドが実行され、システムが基本型以外の属性をエンティティの元の属性として保持し続けるのではなく、グラフのノードやエッジに変換するという点で特殊だ。このちょっとした変更は正直あまりよく理解されておらず、ある程度はエンティティの複雑さを単純化するためのものだと思われるが、実際にはこの戦略がどれほどのメリットをもたらすかはよくわからない。 - による事業体の標準化
named_entity_standardization歌で応えるappend_official_nameこの2つのアプローチは協調して行われる。まずエンティティ名が正規化され、正規化された名前が元のエンティティ情報と関連付けられる。このプロセスはEntity Resolutionに似ている。
全体として、Builderモジュールの機能は、現在の一般的なグラフ構築技術スタックにかなり近く、関連記事やコードも理解するのにそれほど難しくないので、ここでは繰り返さない。
3.2 KAGソルバー
フレームワークのソルバー部分は、特に象徴的な推論関連のコンテンツのロジックのコア機能点の多くを含む、最初に全体的な構造を見てください:
❯ tree .
.
├── __init__.py
├── common
│ ├── __init__.py
│ └── base.py
├── implementation
│ ├── __init__.py
│ ├── default_generator.py
│ ├── default_kg_retrieval.py
│ ├── default_lf_planner.py
│ ├── default_memory.py
│ ├── default_reasoner.py
│ ├── default_reflector.py
│ └── lf_chunk_retriever.py
├── logic
│ ├── __init__.py
│ ├── core_modules
│ │ ├── __init__.py
│ │ ├── common
│ │ │ ├── __init__.py
│ │ │ ├── base_model.py
│ │ │ ├── one_hop_graph.py
│ │ │ ├── schema_utils.py
│ │ │ ├── text_sim_by_vector.py
│ │ │ └── utils.py
│ │ ├── config.py
│ │ ├── lf_executor.py
│ │ ├── lf_generator.py
│ │ ├── lf_solver.py
│ │ ├── op_executor
│ │ │ ├── __init__.py
│ │ │ ├── op_deduce
│ │ │ │ ├── __init__.py
│ │ │ │ ├── deduce_executor.py
│ │ │ │ └── module
│ │ │ │ ├── __init__.py
│ │ │ │ ├── choice.py
│ │ │ │ ├── entailment.py
│ │ │ │ ├── judgement.py
│ │ │ │ └── multi_choice.py
│ │ │ ├── op_executor.py
│ │ │ ├── op_math
│ │ │ │ ├── __init__.py
│ │ │ │ └── math_executor.py
│ │ │ ├── op_output
│ │ │ │ ├── __init__.py
│ │ │ │ ├── module
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ └── get_executor.py
│ │ │ │ └── output_executor.py
│ │ │ ├── op_retrieval
│ │ │ │ ├── __init__.py
│ │ │ │ ├── module
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ ├── get_spo_executor.py
│ │ │ │ │ └── search_s.py
│ │ │ │ └── retrieval_executor.py
│ │ │ └── op_sort
│ │ │ ├── __init__.py
│ │ │ └── sort_executor.py
│ │ ├── parser
│ │ │ ├── __init__.py
│ │ │ └── logic_node_parser.py
│ │ ├── retriver
│ │ │ ├── __init__.py
│ │ │ ├── entity_linker.py
│ │ │ ├── graph_retriver
│ │ │ │ ├── __init__.py
│ │ │ │ ├── dsl_executor.py
│ │ │ │ └── dsl_model.py
│ │ │ ├── retrieval_spo.py
│ │ │ └── schema_std.py
│ │ └── rule_runner
│ │ ├── __init__.py
│ │ └── rule_runner.py
│ └── solver_pipeline.py
├── main_solver.py
├── prompt
│ ├── __init__.py
│ ├── default
│ │ ├── __init__.py
│ │ ├── deduce_choice.py
│ │ ├── deduce_entail.py
│ │ ├── deduce_judge.py
│ │ ├── deduce_multi_choice.py
│ │ ├── logic_form_plan.py
│ │ ├── question_ner.py
│ │ ├── resp_extractor.py
│ │ ├── resp_generator.py
│ │ ├── resp_judge.py
│ │ ├── resp_reflector.py
│ │ ├── resp_verifier.py
│ │ ├── solve_question.py
│ │ ├── solve_question_without_docs.py
│ │ ├── solve_question_without_spo.py
│ │ └── spo_retrieval.py
│ ├── lawbench
│ │ ├── __init__.py
│ │ └── logic_form_plan.py
│ └── medical
│ ├── __init__.py
│ └── question_ner.py
└── tools
├── __init__.py
└── info_processor.py
ソルバーのエントリー・ファイルについては前にも触れたので、関連するコードをここに掲載しておこう:
class SolverPipeline:
def __init__(self, max_run=3, reflector: KagReflectorABC = None, reasoner: KagReasonerABC = None,
generator: KAGGeneratorABC = None, **kwargs):
"""
Initializes the think-and-act loop class.
:param max_run: Maximum number of runs to limit the thinking and acting loop, defaults to 3.
:param reflector: Reflector instance for reflect tasks.
:param reasoner: Reasoner instance for reasoning about tasks.
:param generator: Generator instance for generating actions.
"""
self.max_run = max_run
self.memory = DefaultMemory(**kwargs)
self.reflector = reflector or DefaultReflector(**kwargs)
self.reasoner = reasoner or DefaultReasoner(**kwargs)
self.generator = generator or DefaultGenerator(**kwargs)
self.trace_log = []
def run(self, question):
"""
Executes the core logic of the problem-solving system.
Parameters:
- question (str): The question to be answered.
Returns:
- tuple: answer, trace log
"""
instruction = question
if_finished = False
logger.debug('input instruction:{}'.format(instruction))
present_instruction = instruction
run_cnt = 0
while not if_finished and run_cnt < self.max_run:
run_cnt += 1
logger.debug('present_instruction is:{}'.format(present_instruction))
# Attempt to solve the current instruction and get the answer, supporting facts, and history log
solved_answer, supporting_fact, history_log = self.reasoner.reason(present_instruction)
# Extract evidence from supporting facts
self.memory.save_memory(solved_answer, supporting_fact, instruction)
history_log['present_instruction'] = present_instruction
history_log['present_memory'] = self.memory.serialize_memory()
self.trace_log.append(history_log)
# Reflect the current instruction based on the current memory and instruction
if_finished, present_instruction = self.reflector.reflect_query(self.memory, present_instruction)
response = self.generator.generate(instruction, self.memory)
return response, self.trace_log
合計 SolverPipeline.run() この方法論には3つの主要モジュールがある:Reasoner, Reflector 歌で応える Generator全体的なロジックはやはり非常に明快である。まず問題に答えてみて、問題が解けたかどうかを振り返り、解けなければ納得のいく答えが出るまで、あるいは最大試行回数に達するまで深く考え続ける。これは基本的に、複雑な問題を解く際の人間の一般的な思考法を模倣している。
次のセクションでは、上記の3つのモジュールについてさらに分析する。
3.3 推論者
推論モジュールは、おそらくフレームワーク全体の中で最も複雑な部分であり、その主要なコードは以下の通りである:
class DefaultReasoner(KagReasonerABC):
def __init__(self, lf_planner: LFPlannerABC = None, lf_solver: LFSolver = None, **kwargs):
def reason(self, question: str):
"""
Processes a given question by planning and executing logical forms to derive an answer.
Parameters:
- question (str): The input question to be processed.
Returns:
- solved_answer: The final answer derived from solving the logical forms.
- supporting_fact: Supporting facts gathered during the reasoning process.
- history_log: A dictionary containing the history of QA pairs and re-ranked documents.
"""
# logic form planing
lf_nodes: List[LFPlanResult] = self.lf_planner.lf_planing(question)
# logic form execution
solved_answer, sub_qa_pair, recall_docs, history_qa_log = self.lf_solver.solve(question, lf_nodes)
# Generate supporting facts for sub question-answer pair
supporting_fact = '\n'.join(sub_qa_pair)
# Retrieve and rank documents
sub_querys = [lf.query for lf in lf_nodes]
if self.lf_solver.chunk_retriever:
docs = self.lf_solver.chunk_retriever.rerank_docs([question] + sub_querys, recall_docs)
else:
logger.info("DefaultReasoner not enable chunk retriever")
docs = []
history_log = {
'history': history_qa_log,
'rerank_docs': docs
}
if len(docs) > 0:
# Append supporting facts for retrieved chunks
supporting_fact += f"\nPassages:{str(docs)}"
return solved_answer, supporting_fact, history_log
この結果、推論モジュールの全体的なフローチャートが次のようになる(エラー処理などのロジックは省略されている)。

それは簡単なことだ。DefaultReasoner.reason() 方法論は大きく3つのステップに分けられる:
- ロジック・フォーム・プランニング(LFP):主な内容
LFPlanner.lf_planing - ロジック・フォーム・エグゼキューション(LFE):主に以下のことを行う。
LFSolver.solve - ドキュメントの再ランキング:主に以下のことが含まれる。
LFSolver.chunk_retriever.rerank_docs
以下、3つのステップのそれぞれについて詳しく分析する。
3.3.1 ロジック・フォーム・プランニング
DefaultLFPlanner.lf_planing() メソッドは主に、クエリを一連の独立した論理形式 (lf_nodes: List[LFPlanResult]).
lf_nodes: List[LFPlanResult] = self.lf_planner.lf_planing(question)
実装ロジックは kag/solver/implementation/default_lf_planner.py主な焦点は llm_output 正則化された構文解析を行うか、提供されていない場合はLLMを呼び出して新しい論理形を生成する。
ここで注目すべきことがある。 kag/solver/prompt/default/logic_form_plan.py 関連事項 LogicFormPlanPrompt プロジェクトの詳細設計は、複雑な問題をいかにして複数のサブクエリとそれに対応する論理形式に分解するかが中心である。
3.3.2 ロジック・フォームの実行
LFSolver.solve() メソッドは、特定の論理形式の問題を解くために使用され、答え、サブ問題の答えのペア、関連する想起文書や履歴などを返す。
solved_answer, sub_qa_pair, recall_docs, history_qa_log = self.lf_solver.solve(question, lf_nodes)
深いkag/solver/logic/core_modules/lf_solver.pyソースコードのセクションは以下の通り。 LFSolver このクラス(Logical Form Solver)は推論プロセス全体の中核をなすクラスであり、論理形式(LF)を実行し、答えを生成する役割を担っている:
- 主な方法は以下の通り。
solveクエリと論理フォームノード(List[LFPlanResult]). - 利用する
LogicExecutor回答、ナレッジグラフパス、履歴を生成する論理フォームを実行する。 - サブクエリとアンサーペア、および関連ドキュメントを処理します。
- エラー処理とフォールバック戦略:回答や関連文書が見つからない場合、次のように試みます。
chunk_retriever関連文書のリコール
主な工程は以下の通り:

この中には LogicExecutor はより重要なクラスのひとつで、コア・コードはここに掲載されている:
executor = LogicExecutor(
query, self.project_id, self.schema,
kg_retriever=self.kg_retriever,
chunk_retriever=self.chunk_retriever,
std_schema=self.std_schema,
el=self.el,
text_similarity=self.text_similarity,
dsl_runner=DslRunnerOnGraphStore(...),
generator=self.generator,
report_tool=self.report_tool,
req_id=generate_random_string(10)
)
kg_qa_result, kg_graph, history = executor.execute(lf_nodes, query)
- 実装ロジック
LogicExecutorクラスの関連コードはkag/solver/logic/core_modules/lf_executor.py.そのexecuteこのメソッドの主な実行フローを以下に示す。
この実行フローは、二重の検索戦略を示している。すなわち、検索と推論には構造化されたグラフ・データを優先的に使用し、グラフが答えられない場合には非構造化テキスト情報検索にフォールバックする。
システムはまず、知識グラフを通して、各論理式ノードについて、さまざまなアクチュエータ(以下、「アクチュエータ」と呼ぶ)を使って質問に答えようとする。deduceそしてmathそしてsortそしてretrievalそしてoutputグラフが満足のいく回答を提供できない場合(「わからない」を返す)、システムはテキストブロック検索に戻る。検索アンカーポイントとして以前に得られた名前付きエンティティ(NER)の結果を使用し、それらを過去のQ&Aレコードと組み合わせてコンテキストを強化したクエリを構築する。chunk_retriever検索された文書に基づいて回答を再生成する。
構造化された知識グラフと非構造化テキストデータを組み合わせることで、このハイブリッド検索は、精度を維持しながら、可能な限り完全で文脈の一貫した回答を提供することができる。 - コア・コンポーネント
上記の具体的な実装ロジックに加え、以下の点に注意してください。LogicExecutor初期化には複数のコンポーネントを渡す必要がある。スペースが限られているため、ここでは各コンポーネントのコア機能の簡単な説明のみとし、具体的な実装はソースコードを参照してください。- kg_retriever: ナレッジグラフ・レトリバー
協議kag/solver/implementation/default_kg_retrieval.py真ん中KGRetrieverByLlm(KGRetrieverABC)これは、完全/ファジーやワンホップ部分グラフなどの複数のマッチング方法を含む、実体と関係の検索を実装している。 - chunk_retriever: テキスト・チャンク・リトリーバー
協議kag/common/retriever/kag_retriever.py真ん中DefaultRetriever(ChunkRetrieverABC)まず、Entityの処理が標準化されている。また、検索はHippoRAGを参照し、DPR(Dense Passage Retrieval)とPPR(Personalized PageRank)を組み合わせたハイブリッド検索戦略を採用し、さらにDPRとPPRスコアの融合に基づいている。また、ここではDPR(Dense Passage Retrieval)とPPR(Personalized PageRank)を組み合わせたハイブリッド検索戦略を採用し、さらにその後のDPRとPPRに基づくスコアの融合により、2つの検索手法の動的な重み付けを実現している。 - entity_linker (el): エンティティ・リンカ
協議kag/solver/logic/core_modules/retriver/entity_linker.py真ん中DefaultEntityLinker(EntityLinkerBase)ここでは、エンティティリンクの処理を並列化する前に特徴を構築するというアイデアが使われている。 - dsl_runner: グラフデータベースクエリア
協議kag/solver/logic/core_modules/retriver/graph_retriver/dsl_executor.py真ん中DslRunnerOnGraphStore(DslRunner)構造化されたクエリ情報を特定のグラフデータベースのクエリステートメントを担当し、この作品は、基礎となる特定のグラフデータベースが含まれます、詳細は比較的複雑ですが、あまりにも多くの関与していない。
- kg_retriever: ナレッジグラフ・レトリバー
上記のコードとフローチャートを見ると、ロジックフォーム実行(LFE)ループ全体が階層的な処理アーキテクチャを採用していることがわかる:
- てっぺん
LFSolverプロセス全体の責任者 - 中間圏
LogicExecutor特定の論理フォーム(LF)の実装を担当 - そこ
DSL Runnerグラフデータベースとのやり取りを担当
3.3.3 ドキュメントの再ランキング
を有効にした場合 chunk_retrieverまた、リコールされた文書の順番も変更されます。
if self.lf_solver.chunk_retriever:
docs = self.lf_solver.chunk_retriever.rerank_docs(
[question] + sub_querys, recall_docs
)
3.4 リフレクター
Reflector クラスは主に _can_answer とともに _refine_query 前者は質問に答えられるかどうかを判断するための方法で、後者はマルチホップクエリの中間結果を最適化し、最終的な答えの生成を導くための方法である。
関連実装リファレンス kag/solver/prompt/default/resp_judge.py とともに kag/solver/prompt/default/resp_reflector.py この2つのプロンプトファイルは理解しやすい。
3.5 発電機
ステープル LFGenerator クラスは、さまざまなシナリオ(ナレッジグラフの有無、ドキュメントの有無など)に基づいてプロンプトの単語テンプレートを動的に選択し、対応する質問に対する回答を生成します。
関連する実装は kag/solver/logic/core_modules/lf_generator.pyこのコードは比較的直感的なもので、繰り返されることはない。
4.いくつかの反省
蟻このオープンソースのKAGフレームワークは、専門的なドメインの知識強化サービスに焦点を当て、象徴的な推論、知識の整列と革新的なポイント、包括的な研究のシリーズをカバーし、私は、フレームワークは、シナリオの専門的な知識のスキーマの厳密な制約の必要性のために特に適しているかどうか、インデックス作成やクエリの段階では、全体のワークフローは、ビューのポイントを繰り返し強化されていることを感じる:あなたは、知識ベースの制約からする必要がありますグラフを構築したり、論理的な推論を行う。グラフを構築したり、論理的な推論を行ったりしなければならない。この考え方は、大規模なモデルの錯覚だけでなく、ドメイン知識の欠落の問題をある程度緩和するはずである。
マイクロソフトのGraphRAGフレームワークがオープンソース化されて以来、コミュニティは知識グラフとRAG技術スタックの統合についてより深く考えるようになり、例えばLightRAG、StructRAGなどの最近の研究は多くの有益な探求を行っている。KAGは、技術的にはGraphRAGとの間にいくつかの相違点があるものの、特に知識の整列と推論における欠点を補うために、GraphRAGの専門的なドメインにおける知識強化サービスの方向における実践としてある程度みなすことができる。KAGとGraphRAGの間には技術的な違いはあるが、KAGはGraphRAGの専門領域における知識強化サービスの方向性、特に知識アライメントと推論の欠点を補うための実践とみなすことができる。この観点から、個人的には知識制約型GraphRAGと呼びたい。
ネイティブのGraphRAGは、異なるコミュニティに基づいた階層的な要約により、比較的抽象度の高い質問に答えることができるが、Query-focused summarization (QFS)にフォーカスしすぎているため、このフレームワークは細かい事実の質問にはうまく対応できない可能性がある。GraphRAGは、ペンダント領域において多くの課題を抱えている。一方、KAGフレームワークは、グラフ構築の段階から、Entityの整列や特定のSchemaに基づく標準化操作など、より多くの最適化を行い、クエリの段階では、記号論理に基づく知識グラフ推論も導入している。記号推論は、グラフ分野ではかなり前から研究されているが、RAGシナリオにはまだ実際に適用されていない。RAGの推論能力の強化は、筆者がより楽観的に考えている研究方向であり、少し前にマイクロソフトはRAG技術スタックの推論能力の4つの層を要約した:
- レベル1 明示的事実, 明示的事実
- レベル2 暗黙の事実、隠された事実
- レベル3の解釈可能な根拠、解釈可能な(ペンダントの)根拠
- レベル4の隠れた根拠、見えない(ペンダント・ドメインの)根拠
現在、ほとんどのRAGフレームワークの推論能力は、まだLevel-1レベルに留まっており、Level-3、Level-4以上のレベルでは、垂直推論の重要性が強調され、垂直領域での大規模モデルの知識不足が難点であり、KAGフレームワークのクエリ段階での記号推論の導入は、ある程度この方向性の模索と見なすことができ、RAG推論の領域では、次年度以降に新しい研究の波が起こることが予見される。RLやCoTなど、モデル自身の推論能力とのさらなる融合など、RAG推論が新たな研究の波を巻き起こすことも予見される。
推論セッションに加えて、KAGはRetrieval(検索)でも言及している。 ヒッポラグ DPRとPPRのハイブリッド検索戦略の採用とPageRankの効率的な使用は、従来のベクトル検索に対する知識グラフの優位性をさらに実証しており、今後さらに多くのグラフ検索アルゴリズムがRAG技術スタックに統合されると考えられる。
もちろん、KAGフレームワークはまだ初期段階の急速な反復の段階にあると推定され、既存の論理形式計画と論理形式実行が設計レベルで完全な理論的裏付けを持っているかどうか、複雑な問題に直面したときに分解が不十分で実行に失敗しないかどうかなど、機能の具体的な実装についてはまだ議論の余地があるはずである。不十分な分解、実行の失敗があるかどうかが、この境界の定義と堅牢性の問題は、通常、対処することは非常に困難であるだけでなく、試行錯誤のコストを必要とし、推論チェーン全体があまりにも複雑である場合、最終的な失敗率が高くなる可能性があり、結局のところ、戦略に戻って劣化の様々な問題の緩和の一定程度に過ぎない。加えて、私はフレームワークの一番下にあるGraphStoreが実際に増分更新インターフェイスを予約していることに気づいたが、上位レイヤのアプリケーションは関連する機能を示しておらず、これも個人的にGraphRAGコミュニティがより高く求めている機能だと理解している。
全体として、KAGフレームワークは、革新的な点を多く含む、最近の中では非常に筋金入りの作品と考えられており、コードは本当に多くの細部を磨き上げてきた。これは、RAGテクノロジースタックの着地プロセスの重要な原動力になったと考えられている。
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事


コメントはありません