ロールアップ長文ベクトルモデル チャンキング戦略 コンペティション

ロングテキスト・ベクター・モデルは、10ページ分のテキストを1つのベクターにエンコードすることができる。
多くの人は... 必ずしもそうではない。
直接使ってもいいのか?チャンクすべき?最も効率的な分割方法は?この記事では、長いテキストベクターモデルのための様々なチャンキング戦略を探り、長所と短所を分析し、落とし穴を避ける手助けをします。
長文ベクトル化の問題
まず、記事全体を1つのベクターに圧縮することにどのような問題があるかを見てみよう。
文書検索システムを構築する例として、一つの記事に複数のトピックが含まれる場合がある。 例えば、ICML2024の参加者レポートに関するこのブログには、会議の紹介、ジーナAIの仕事のプレゼンテーション(jina-clip-v1)や他の研究論文の要約を含む。記事全体を一つのベクトルにベクトル化すると、そのベクトルには3つの異なるトピックの情報が混在することになる:
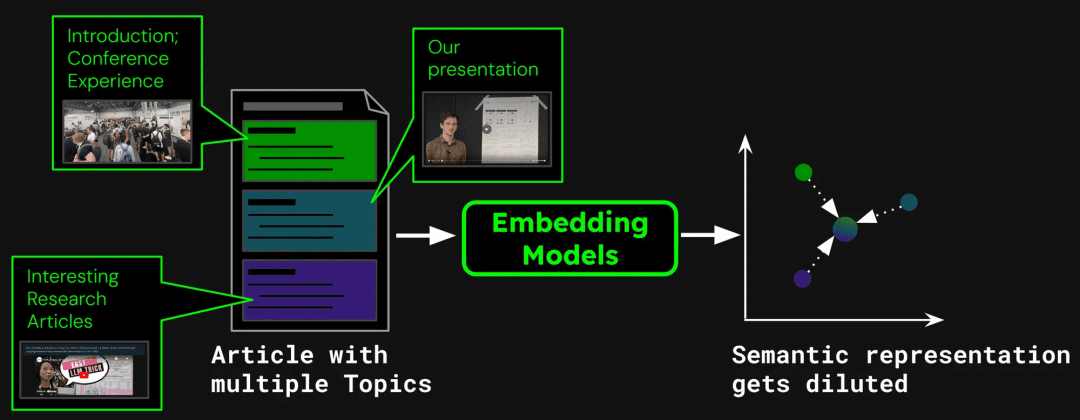
これは次のような問題を引き起こす可能性がある:
1.代表権の希釈
は、希釈がテキストベクトルの精度を弱めることを示している。ブログ記事には複数のトピックが含まれているがしかし、ユーザーの検索クエリは、これらのうちの1つだけに集中する傾向がある。.記事全体を一つのベクトルで表現することは、全てのトピック情報をベクトル空間の一点に圧縮することと同じである。より多くのテキストがモデルの入力に追加されるにつれ、このベクトルは記事の全体的な主題を徐々に表し、特定の文章やトピックの詳細を薄める。これは、複数の顔料を混ぜて一つの色にするようなもので、ユーザーが特定の色を見つけようとしたときに、その中から特定の色を識別することが難しくなる。
2.限られたキャパシティ
モデルによって生成されるベクトル次元は固定されており、長いテキストには多くの情報が含まれているため、変換処理中に情報が失われることは避けられない。高精細な地図を切手に圧縮するようなもので、多くの細部が見えなくなる。
3.情報の損失
多くの長いテキストモデルは、8192トークンまでしか扱えない。より良いテキストは、通常は後ろの方で切り捨てられなければならず、重要な情報が文書の末尾にある場合、検索に失敗する可能性がある。
4.セグメンテーションの要件
アプリケーションによっては、特定のテキストセグメントに対してのみベクトル化を行う必要があります。例えば、質問と回答のシステムでは、回答を含む段落のみをベクトル化のために抽出する必要があります。この場合でも、テキストのチャンキングは必要です。
3 長文処理戦略
実験を始める前に、概念の混乱を避けるために、まず3つのチャンク戦略を定義する:
1.チャンキングはしない:テキスト全体を1つのベクターに直接エンコードする。
2.ナイーブ・チャンキングテキストはまず複数のテキストチャンクに分割され、別々にベクトル化される。一般的に使用される方法には、テキストを固定サイズに分割する固定サイズチャンキングがあります。 トークン チャンクの数;センテンス・ベース・チャンキング:文中のチャンキング;セマンティック・ベース・チャンキング:意味情報に基づくチャンキング。この実験では、固定サイズのチャンクを使用。
3.後期チャンキングこれは、チャンクする前にテキスト全体に目を通すという新しい方法で、主に2つのステップからなる:
- 規約全文文書全体を最初にエンコードし、各トークンのベクトル表現を得る。
- チャンクプーリング同じテキストブロックのトークン・ベクトルをチャンクの境界に従って平均的にプールすることで、各テキストブロックのベクトルを生成する。各トークンのベクトルは全テキストの文脈で生成されるため、レイト・パーティショニングによってブロック間の文脈情報を保持することができる。
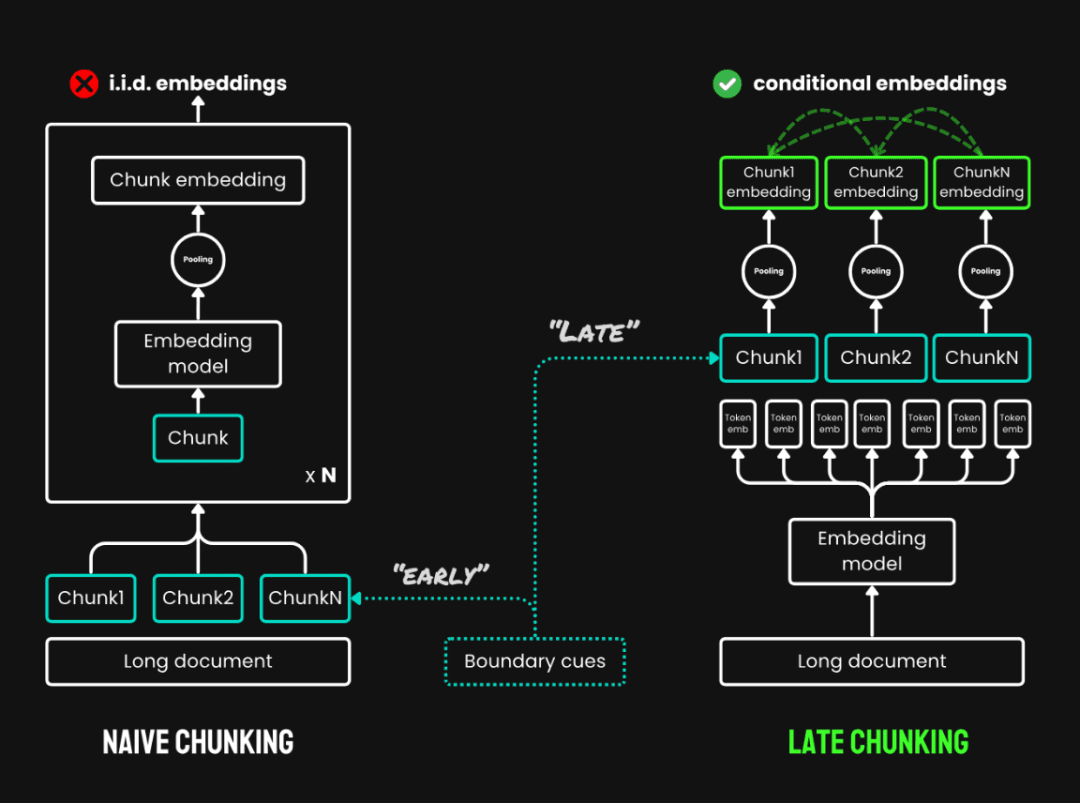
後期分割とプレーン・チャンキングの比較
最大入力長を超えるモデルの場合(例:8192 トークンを使用する。 ロング・レイト・チャンキングまず、文書を複数の重複するマクロブロックに分割し、各マクロブロックはモデルの処理可能範囲内の長さを持つ。次に、各マクロブロックの内部で標準的な後分割戦略(エンコードとプーリング)が適用される。マクロブロック間の重複は、文脈情報の連続性を確保するために使われる。
後期得点特定実施コード: https://github.com/jina-ai/late-chunking在 ノート経験: https://colab.research.google.com/drive/1iz3ACFs5aLV2O_uZEjiR1aHGlXqj0HY7?usp=sharing
では、どの方法がベストなのか?
比較のために、5つのデータセットを使用した。 jina-embeddings-v3 実験では、すべての長文をモデルの最大入力長(8192トークン)に切り詰め、64トークンずつのテキストブロックに分割した。

5つのテストデータセットは、5つの異なる検索タスクにも対応している。
下図は、異なるタスクにおける3つの方法の性能の違いを示している。どの方法がすべての場合に最適ということはなく、選択は特定のタスクに依存する。
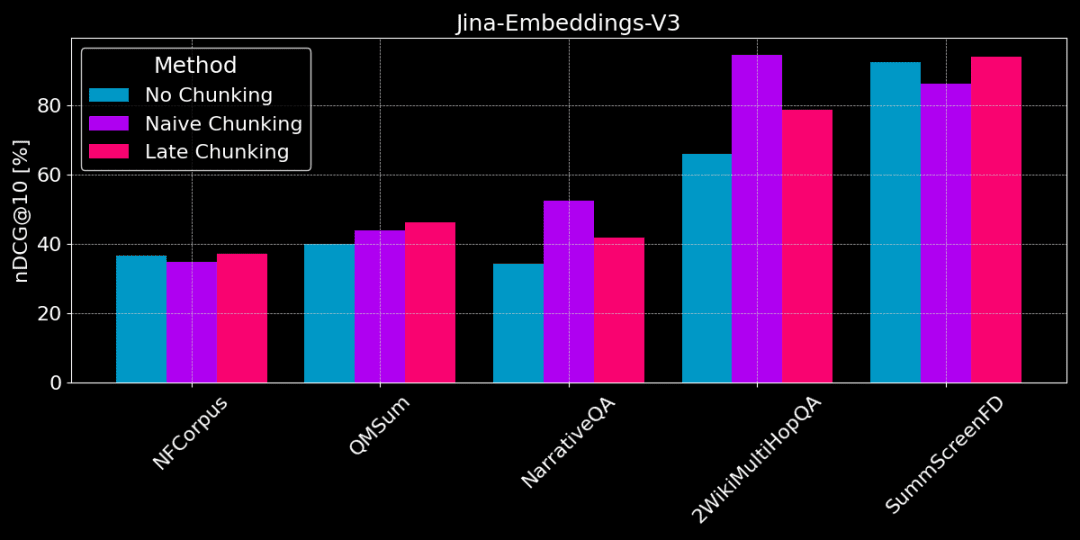
チャンキングなし vs プレーン・チャンキング vs レイト・チャンキング
👩🏫 具体的な事実を見つける。
特定の、局所的な事実情報をテキストから抽出する必要がある場合(例えば、「誰が何かを盗んだのか?))、QMSum、NarrativeQA、2WikiMultiHopQAのようなデータセットでは、プレーン・チャンキングは文書全体をベクトル化するよりも良いパフォーマンスを発揮する。答えは通常テキストの特定の部分にあるため、プレーン・チャンキングは他の余計な情報に惑わされることなく、答えを含むテキストの塊をより正確に探し出すことができる。
しかし、単純なチャンキングは文脈を断ち切り、テキスト中の参照関係や参照を正しく解析するためのグローバルな情報を失う可能性がある。
👩🏫 テーマに一貫性があり、点数は遅い方が良い。
遅めの採点は、主題が明確で、文章の構造が首尾一貫している場合に効果的である。レイト区分は文脈を考慮するため、長文内の参照関係を含め、各パートの意味や関連性をよりよく理解することができる。
しかし、記事中に多くの無関係なコンテンツがある場合、レイト・スコアリングは「ノイズ」を考慮することになり、性能の後退と精度の低下につながる。例えば、NarrativeQAと2WikiMultiHopQAは、これらの記事には無関係な情報が多すぎるため、プレーン・チャンキングほどうまくいかない。
チャンクのサイズは影響するのか?
次の図は、チャンクサイズの異なるデータセットに対する、プレーン・チャンキングとレイト・チャンキングの性能を示している:
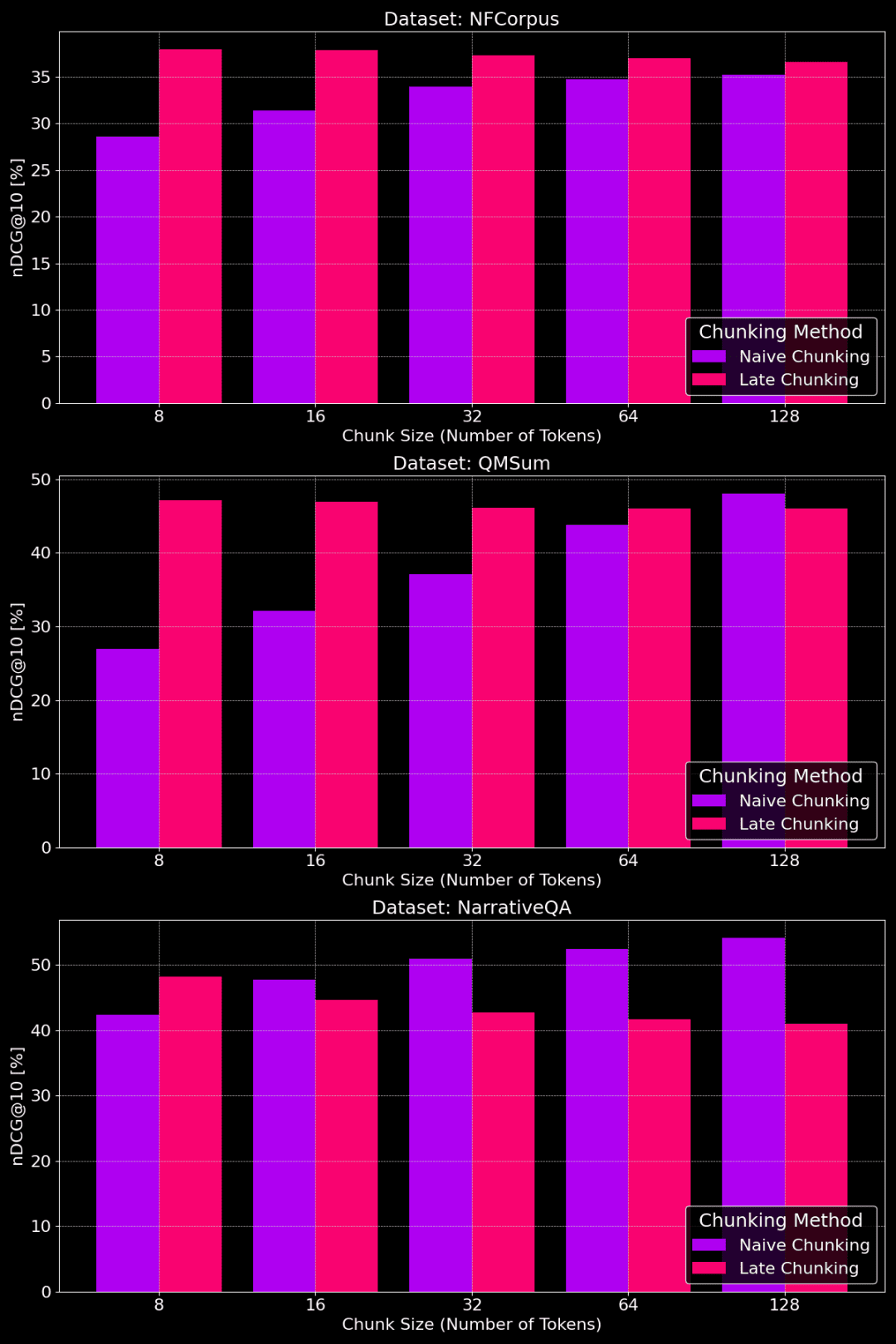
チャンクサイズを変えたプレーン・チャンキングとレイト・チャンキングの性能比較
図からわかるように、最適なチャンクサイズは、実は特定のデータセットがどのようなものかに依存する。
レイトスプリッティング法では、小さなチャンクの方が文脈情報をよりよく捉え、そのためよりうまく機能する。特に、(NarrativeQAデータセットのように)トピックに関係のないコンテンツがデータセットに多く含まれる場合、コンテキストが多すぎるとかえってノイズを招き、パフォーマンスを低下させる可能性がある。
プレーン・チャンキングの場合、チャンクが大きい方が、含まれる情報が包括的で損失が少ないため、うまくいくことがある。しかし、チャンクが大きすぎて情報が乱雑になり、検索の精度が落ちることもある。そのため、最適なチャンクサイズは特定のデータセットやタスクに合わせて調整する必要があり、万能な答えは存在しない。
さまざまなチャンキング戦略の長所と短所を理解した上で、どのように適切なものを選べばいいのだろうか?
1.フルテキストのベクトル化(チャンキングなし)は、どのような場合に適切か?
- テーマは単一で、重要な情報は冒頭に集中している:例えば、構造化されたニュース記事の場合、重要な情報は見出しや冒頭の段落にあることが多い。この場合、全文ベクトル化を直接使用すると、モデルが主要な情報を捉えるため、通常は良い結果が得られます。
- 一般的に、できるだけ多くのテキストコンテンツをモデルに入れることは、検索結果に影響を与えない。しかし、長文モデルは冒頭部分(タイトル、序文など)に注目する傾向が強く、中間部分や末尾部分の情報は無視される可能性がある。そのため、重要な情報が記事の途中や末尾にある場合、この方法の効果はかなり低くなる。
- 詳細な実験結果はhttps://jina.ai/news/still-need-chunking-when-long-context-models-can-do-it-all
2.ナイーブ・チャンキングはどこに適しているか?
- トピックの多様性、特定の情報を検索する必要性テキストに複数のトピックが含まれる場合、あるいはユーザーからのクエリがテキスト中の特定の事実を対象とする場合、プレーン・チャンキングが適しています。情報の希薄化を効果的に回避し、特定の情報の検索精度を向上させることができます。
- ローカライズされたテキストスニペットを表示する必要がある検索エンジンと同様に、クエリに関連するテキストスニペットを結果に表示する必要があるため、チャンキング戦略が必要となる。
- また、チャンキングは、より多くのテキストブロックをベクトル化する必要があるため、ストレージスペースと処理時間に影響を与える。
3.レイト・チャンキングはどのような位置づけか?
- 主題の一貫性、文脈情報の必要性エッセイや長文のレポートなど、一貫したトピックを持つ長文の場合、後期分割法は文脈情報を効果的に保持することができ、テキスト全体の意味理解を深めることができる。特に、長文の読解や意味マッチングなど、テキストの異なる部分間の関係を理解する必要があるタスクに適している。
- ローカルな詳細とグローバルなセマンティクスのバランスを取る必要性後期分割法は、より小さなチャンクサイズで局所的な詳細と大域的な意味のバランスを効果的にとることができ、多くの場合、他の2つの方法よりも良い結果を得ることができる。しかし、記事中に無関係なコンテンツが多い場合、後期分割はそのような無関係な情報を考慮するため、効果に影響を与えることに注意すべきである。
評決を下す
長文のベクトル化戦略の選択は複雑な問題であり、万能の最適解はなく、先に述べたテキストの長さ、トピックの数、重要な情報の位置など、データの特性と検索目標を考慮する必要がある。
本稿では、様々なチャンキング戦略の比較分析フレームワークを提供し、実験結果を通じていくつかの参考情報を提供したい。実際の応用では、より多くの実験を比較し、あなたのシナリオに最も適した戦略を選択することができます。
長文のベクトル化に興味があるならjina-embeddings-v3高度な長文処理機能、多言語サポート、レイト・スコアなど、試してみる価値はある。
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事


コメントはありません