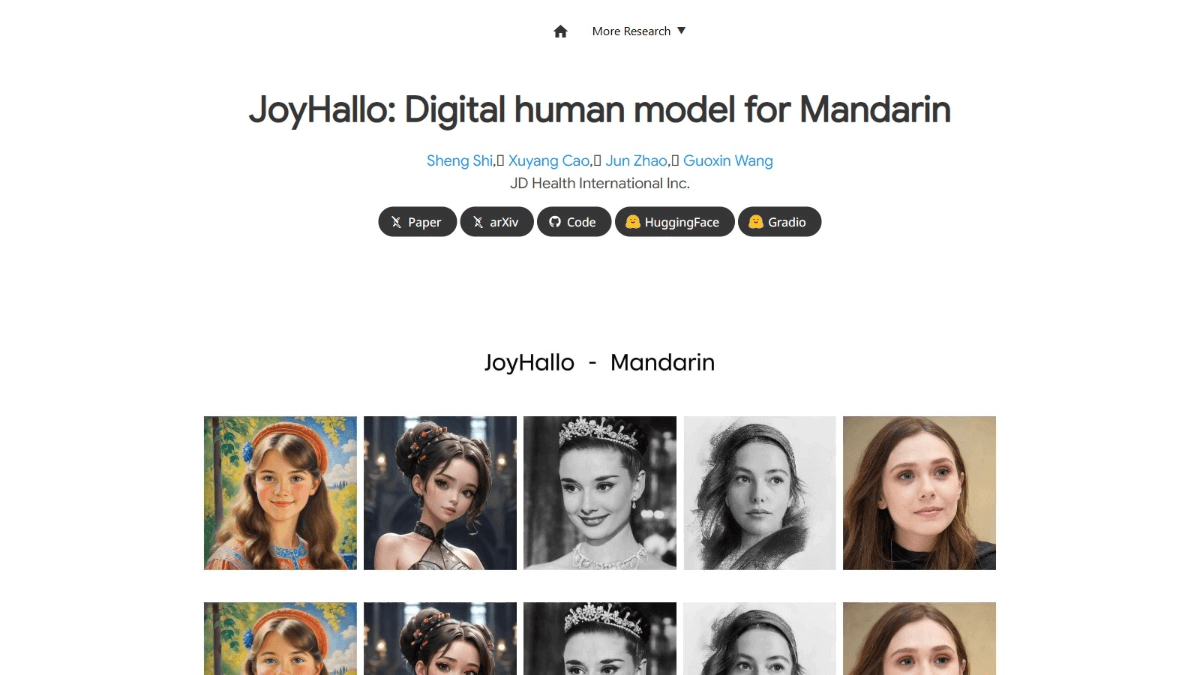
JoyHallo - JingdongのオープンソースAIデジタル人体モデル

ジョイハロとは?
JoyHalloはJingdongのオープンソースAIデジタルヒューマンモデルで、北京語用に設計され、音声をリアルなスピーキングビデオに変換することをサポートします。JoyHalloは、唇の動きの予測精度を向上させ、英語ビデオの生成をサポートするために、半結合構造を持つwav2vec2モデルに基づく音声特徴を埋め込みます。JoyHalloトレーニングデータセットは、複数の年齢とスタイルの北京語ビデオをカバーしています。JoyHalloはバーチャルアンカー、オンライン教育、顧客サービス、広告制作などの分野で幅広く応用され、効率的で生き生きとしたパーソナライズされたサービス体験を提供し、関連産業の知的発展を促進することができる。
JoyHalloの主な特徴
- オーディオ主導のビデオ生成入力された音声信号に基づいて、それに合ったトーキングビデオを自動的に生成します。
- 言語横断的な生成能力JoyHalloは中国語のビデオ生成に特化しているだけでなく、英語のビデオ生成も可能です。
- リップ・シンクロナイズこのモデルは、音声と映像の唇の動きを正確に同期させます。
- 表情生成音声の感情や声のトーンに基づいて、適切な表情を生成します。
ジョイハロ公式サイトアドレス
- プロジェクトのウェブサイト::https://jdh-algo.github.io/JoyHallo/
- GitHubリポジトリ::https://github.com/jdh-algo/JoyHallo
- HuggingFaceモデルライブラリ::https://huggingface.co/jdh-algo/JoyHallo-v1
- arXivテクニカルペーパー::https://arxiv.org/pdf/2409.13268
ジョイハロの使い方
- 環境準備::
- ハードウェア要件モデルの推論を高速化するために、NVIDIAシリーズのグラフィックスカード(RTX 30シリーズ以上)など、高性能GPUを搭載したコンピュータの使用を推奨します。
- ソフトウェア環境Pythonがシステムにインストールされていることを確認する(推奨バージョン3.8以上)。以下のコマンドに基づいてPyTorchをインストールしてください(CUDAのバージョンに応じて適切なインストールコマンドを選択してください):
pip install torch torchvision torchaudio- 依存関係のインストール::
- JoyHalloのGitHubリポジトリのクローン::
git clone https://github.com/jdh-algo/JoyHallo.git
cd JoyHallo- プロジェクトの依存関係をインストールする::
pip install -r requirements.txt- データ準備JoyHalloのデータセットには通常、音声ファイルとそれに対応する動画ファイルが含まれています。音声ファイルはwav形式、動画ファイルはmp4形式である必要があります。事前に訓練されたモデルを推論に使用するだけであれば、このステップは直接スキップしてください。
- モデルのローディングと推論::
- 訓練済みモデルの読み込みJoyHalloの事前訓練されたモデルは、Hugging Faceモデルライブラリに基づいてロードされます。
from transformers import AutoModelForAudioToVideo, AutoProcessor
model_name = "jdh-algo/JoyHallo-v1"
processor = AutoProcessor.from_pretrained(model_name)
model = AutoModelForAudioToVideo.from_pretrained(model_name)- オーディオの前処理:オーディオファイルをモデルに必要な形式に変換します。::
from datasets import load_dataset
dataset = load_dataset("audiofolder", data_dir="path/to/your/audio/files")
inputs = processor(dataset[0]["audio"], return_tensors="pt")- ビデオの作成モデルを使って推論し、ビデオを生成する:
outputs = model(**inputs)
video = processor.postprocess_video(outputs)
video.save("output_video.mp4")ジョイハロの強み
- 中国語の最適化JoyHalloは北京語のためにデザインされ、唇の動きと正確に一致させ、北京語の複雑な母音と韻音を正確にシミュレートすることができます。zh"、"ch"、"sh "など。音声の感情やイントネーションに基づいて豊かな表情を生成し、ビデオをより魅力的なものにします。
- クロスランゲージ能力JoyHalloは北京語だけでなく英語の動画も作成でき、多国籍企業のカスタマーサービス、国際教育など、多言語対応で応用範囲が広い。
- 効率的な構造半結合構造に基づき、音声特徴埋め込み処理と映像生成処理を分離することで、推論速度が大幅に向上し、従来の完全結合モデルよりも14.3%高速化しました。
- 豊富なアプリケーションシナリオ: JoyHalloは、バーチャルキャスター(ニュース放送、天気予報、スポーツイベントの解説)、オンライン教育(語学学習、オンラインコース)、カスタマーサービス(バーチャル接客係)など、幅広い業界やシナリオに応用できます。
- オープンソースリソース日常会話から専門的な医療トピックまで、様々な年齢と話し方の北京語ビデオデータセットを含むオープンソースデータセット(jdh-Halloデータセット)を提供する。このプロジェクトでは、開発者がカスタマイズや最適化を行いやすいように、詳細なモデルの学習方法とコードを提供する。
ジョイハロの対象者
- コンテンツクリエータービデオプロデューサーやソーシャルメディアの達人は、高品質でパーソナライズされたビデオコンテンツを素早く作成し、時間とコストを節約し、コンテンツの魅力を高めます。
- 教育者オンライン教育プラットフォーム、学校、研修機関向けにバーチャル教師画像を生成し、教材を充実させ、生き生きとした教育体験を提供する。
- 企業・ブランド企業の顧客サービス部門は、サービス満足度を高めるためにバーチャルな顧客サービス担当者を作成し、マーケティングチームは広告の訴求力を高めるためにパーソナライズされた広告ビデオを作成する。
- エンターテインメント業界関係者映画・テレビ制作会社やゲーム開発会社による、キャラクターフェイシャルアニメーションの生成、制作効率の向上、制作コストの削減、作品への没入感や臨場感の向上。
- 研究者と開発者人工知能の研究者やソフトウェア開発者は、技術の進歩や応用シーンの拡大のために研究開発を行っています。
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事

コメントはありません