
精密医療Q&Aを可能にするDeepSeek R1モデルの微調整:オープンソースAIの可能性を解き放つ

ディープシーク OpenAIの業界でのポジションに挑戦するために、一連の高度な推論モデルを導入した。完全無料、使用制限なしこのプログラムは、すべてのユーザーのために設計されている。
この記事では、Hugging FaceのMedical Mind Chainデータセットを使用して、DeepSeek-R1-Distill-Llama-8Bモデルを微調整する方法を説明します。このライトバージョンの ディープシーク-R1 このモデルは、DeepSeek-R1によって生成されたデータに対してLlama 3 8Bモデルを微調整して得られたもので、元のモデルと同様の優れた推論を示す。

DeepSeek R1 復号化
DeepSeek-R1とDeepSeek-R1-Zeroは、数学、プログラミング、論理的推論のタスクにおいて、OpenAIのo1モデルを上回った。R1もR1-ZEROもオープンソースモデルであることは特筆に値する。.
ディープシーク-R1-ゼロ
DeepSeek-R1-Zeroは、最初のステップとして教師あり微調整(SFT)を使用する従来のモデルとは対照的に、大規模な強化学習(RL)のみを使用して訓練された最初のオープンソースモデルです。この革新的なアプローチは、モデルが独立してCoT(Chain-of-Thought)推論を探求する力を与え、複雑な問題を解決し、出力を反復的に最適化することを可能にします。しかし、このアプローチは、推論ステップの重複の可能性、可読性の低下、一貫性のない言語スタイルなど、いくつかの課題ももたらします。
ディープシーク-R1
DeepSeek-R1のリリースは、DeepSeek-R1-Zeroの欠点を克服することを目的としています。強化学習の前にコールドスタートデータを導入することで、DeepSeek-R1は推論と非推論の両方のタスクに対してより強力な基盤を築きます。この多段階学習戦略により、DeepSeek-R1は数学、プログラミング、推論のベンチマークでOpenAI-o1に対してトップレベルのパフォーマンスを達成し、出力の可読性と一貫性を大幅に向上させることができます。
DeepSeek蒸留モデル
DeepSeekはまた、蒸留モデル・ファミリーも導入している。これらのモデルは、優れた推論性能を維持しながら、より小さく、より効率的です。パラメータサイズは1.5Bから70Bまでありますが、これらのモデルはすべて強力な推論能力を保持しています。その中でもDeepSeek-R1-Distill-Qwen-32Bは、いくつかのベンチマークでOpenAI-o1-miniモデルを凌駕しています。小規模モデルは大規模モデルの推論パターンを継承しており、蒸留技術の有効性を完全に実証している。
-1")
ディープシークR1の微調整の様子
1.環境構成
このモデルの微調整では、Kaggleが無償でGPUリソースを提供しているため、クラウドIDEとしてKaggleが選ばれた。当初は2つのT4 GPUが選ばれましたが、使用されたのは1つだけでした。ユーザーがローカルコンピューターでモデルの微調整を行う場合は、最低でも16GBのメモリを搭載したRTX 3090グラフィックカード。.
まず、ユーザーのHugging Faceで新しいKaggleノートブックを開始します。 トークン 歌で応える ウェイト Biases トークンがキーとして追加される。
キーのセットアップが完了したら アンロス Pythonパッケージ。 Unslothは、大規模言語モデル(LLM)の微調整を倍速化し、メモリ効率を大幅に改善するために設計されたオープンソースのフレームワークです。
%%capture
!pip install unsloth
!pip install --force-reinstall --no-cache-dir --no-deps git+https://github.com/unslothai/unsloth.git
次に、Hugging Face CLIにログインします。このステップは、その後のデータセットのダウンロードと微調整されたモデルのアップロードのために重要です。
from huggingface_hub import login
from kaggle_secrets import UserSecretsClient
user_secrets = UserSecretsClient()
hf_token = user_secrets.get_secret("HUGGINGFACE_TOKEN")
login(hf_token)
その後、Weights & Biases (wandb)にログインし、実験の経過を追跡し、進捗を微調整するために、新しいプロジェクトを作成する。
import wandb
wb_token = user_secrets.get_secret("wandb")
wandb.login(key=wb_token)
run = wandb.init(
project='Fine-tune-DeepSeek-R1-Distill-Llama-8B on Medical COT Dataset',
job_type="training",
anonymous="allow"
)
2.モデルとトークナイザーのロード
この論文では、DeepSeek-R1-Distill-Llama-8BモデルのUnslothバージョンをロードした。
https://huggingface.co/unsloth/DeepSeek-R1-Distill-Llama-8B
メモリ使用量を最適化し、パフォーマンスを向上させるため、モデルは4ビットの定量化された方法でロードされるように選択された。
from unsloth import FastLanguageModel
max_seq_length = 2048
dtype = None
load_in_4bit = True
model, tokenizer = FastLanguageModel.from_pretrained(
model_name="unsloth/DeepSeek-R1-Distill-Llama-8B",
max_seq_length=max_seq_length,
dtype=dtype,
load_in_4bit=load_in_4bit,
token=hf_token,
)
3.事前微調整モデル推論能力プライマー
モデル用のプロンプト・テンプレートを構築するために、質問と回答生成のためのプレースホルダーを備えたシステム・プロンプトが定義された。このプロンプトは、思考を段階的に進め、最終的に論理的に厳密で正確な答えを生成するプロセスを通じてモデルを導くことを意図している。
prompt_style = """Below is an instruction that describes a task, paired with an input that provides further context.
Write a response that appropriately completes the request.
Before answering, think carefully about the question and create a step-by-step chain of thoughts to ensure a logical and accurate response.
### Instruction:
You are a medical expert with advanced knowledge in clinical reasoning, diagnostics, and treatment planning.
Please answer the following medical question.
### Question:
{}
### Response:
<think>{}"""
この例では、メッセージが prompt_style 医療問題を提供し、それをトークンに変換する。 トークン 答えを生成するためにモデルに渡される。
question = "A 61-year-old woman with a long history of involuntary urine loss during activities like coughing or sneezing but no leakage at night undergoes a gynecological exam and Q-tip test. Based on these findings, what would cystometry most likely reveal about her residual volume and detrusor contractions?"
FastLanguageModel.for_inference(model)
inputs = tokenizer([prompt_style.format(question, "")], return_tensors="pt").to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=1200,
use_cache=True,
)
response = tokenizer.batch_decode(outputs)
print(response[0].split("### Response:")[1])
上記の医学的疑問の核心はこうだ:
咳やくしゃみなどの動作時に不随意に尿が漏れるが、夜間の尿漏れはない61歳の女性。彼女は婦人科的検査とQ-tipテストを受けた。これらの所見に基づき、膀胱鏡検査で彼女の残尿量と尿膜拘縮の状態についてどのような情報が得られる可能性が高いか?
微調整なしでも、モデルは思考の連鎖をうまく生成し、最終的な答えを出す前に厳密な推論を行う。 <think></think> タグは次の通り。
では、なぜ微調整が必要なのか?モデルは詳細な推論プロセスを示しているが、その表現はやや長く、十分に簡潔ではない。さらに、最終的な答えは箇条書きのリストとして表示されるが、これは微調整が期待されるデータセットの構造やスタイルから逸脱している。
4.データセットの読み込みと前処理
プロンプト・テンプレートに複雑な思考連鎖(Complex Chain-of-Thought)カラムの3つ目のプレースホルダーを追加することで、データセットの処理ニーズに対応できるようにプロンプト・テンプレートを微調整した。
train_prompt_style = """Below is an instruction that describes a task, paired with an input that provides further context.
Write a response that appropriately completes the request.
Before answering, think carefully about the question and create a step-by-step chain of thoughts to ensure a logical and accurate response.
### Instruction:
You are a medical expert with advanced knowledge in clinical reasoning, diagnostics, and treatment planning.
Please answer the following medical question.
### Question:
{}
### Response:
<think>
{}
</think>
{}"""
データセットに「テキスト」列を作成するためにPython関数を作成した。この列の内容は、質問、思考連鎖、答えをそれぞれプレースホルダーに入力したトレーニングプロンプトテンプレートで構成されている。
EOS_TOKEN = tokenizer.eos_token # Must add EOS_TOKEN
def formatting_prompts_func(examples):
inputs = examples["Question"]
cots = examples["Complex_CoT"]
outputs = examples["Response"]
texts = []
for input, cot, output in zip(inputs, cots, outputs):
text = train_prompt_style.format(input, cot, output) + EOS_TOKEN
texts.append(text)
return {
"text": texts,
}
FreedomIntelligence/medical-o1-reasoning-SFTデータセットの最初の500サンプルがHugging Face Hubからロードされた。
https://huggingface.co/datasets/FreedomIntelligence/medical-o1-reasoning-SFT?row=46
その後 formatting_prompts_func 関数は、データセットの "text "カラムをマップする。
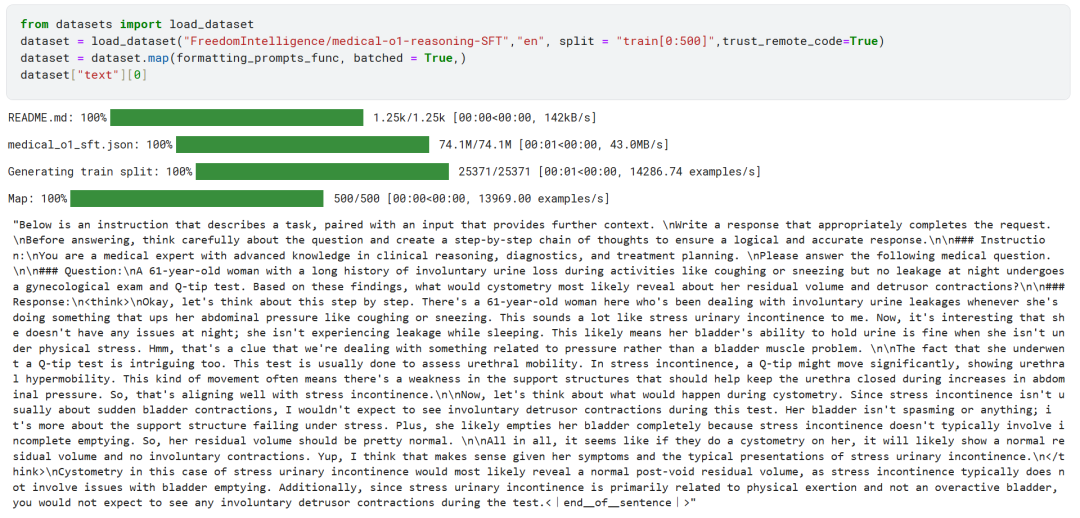
上にあるように、「テキスト」欄はシステムのヒント、指示、思考連鎖、最終解答とうまく統合されている。
5.モデル構成
このモデルは、ターゲットモジュールを設定することにより、ローランクアダプター技術を使用して構成される。
model = FastLanguageModel.get_peft_model(
model,
r=16,
target_modules=[
"q_proj",
"k_proj",
"v_proj",
"o_proj",
"gate_proj",
"up_proj",
"down_proj",
],
lora_alpha=16,
lora_dropout=0,
bias="none",
use_gradient_checkpointing="unsloth", # True or "unsloth" for very long context
random_state=3407,
use_rslora=False,
loftq_config=None,
)
次に、トレーニングパラメータとトレーナー(Trainer)が設定された。モデルの微調整プロセスを最適化するために、モデル、トークナイザー、データセット、その他の主要なトレーニングパラメータがトレーナーに提供された。
from trl import SFTTrainer
from transformers import TrainingArguments
from unsloth import is_bfloat16_supported
trainer = SFTTrainer(
model=model,
tokenizer=tokenizer,
train_dataset=dataset,
dataset_text_field="text",
max_seq_length=max_seq_length,
dataset_num_proc=2,
args=TrainingArguments(
per_device_train_batch_size=2,
gradient_accumulation_steps=4,
# Use num_train_epochs = 1, warmup_ratio for full training runs!
warmup_steps=5,
max_steps=60,
learning_rate=2e-4,
fp16=not is_bfloat16_supported(),
bf16=is_bfloat16_supported(),
logging_steps=10,
optim="adamw_8bit",
weight_decay=0.01,
lr_scheduler_type="linear",
seed=3407,
output_dir="outputs",
),
)
6.モデルトレーニング
trainer_stats = trainer.train()
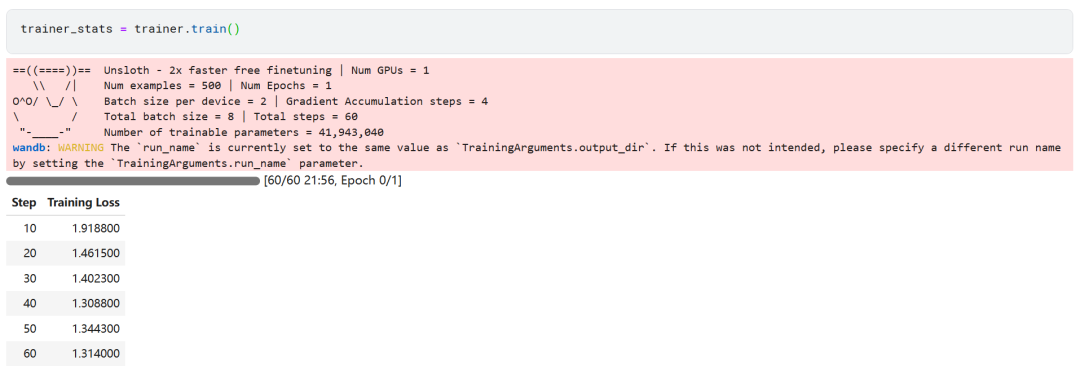
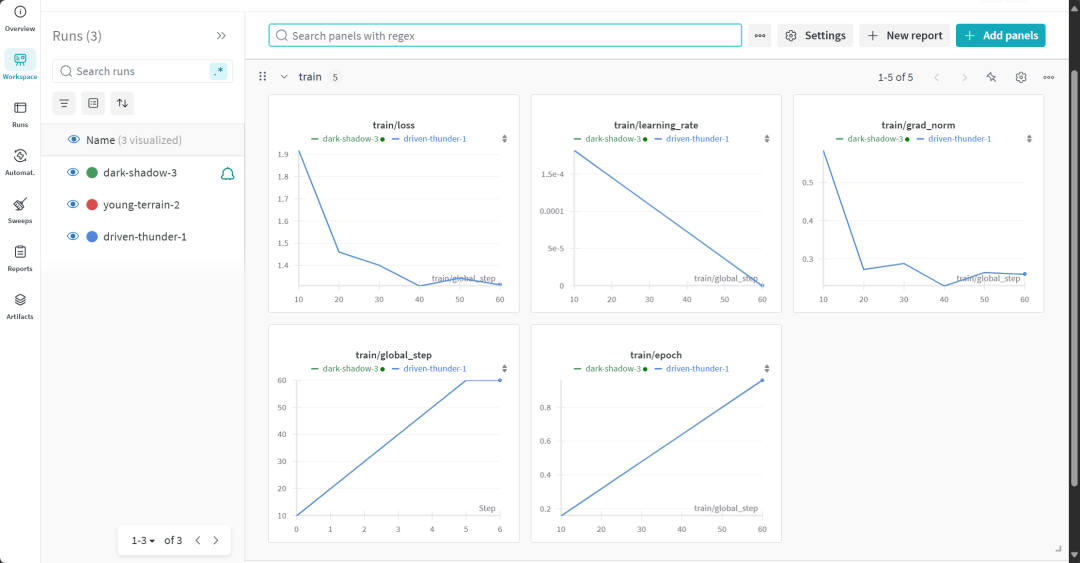
モデルのトレーニングプロセスには22分かかった。トレーニングのロス(損失)は徐々に減少しており、これはモデルの性能が向上していることを示すポジティブなサインである。
ユーザーは、Weights & Biasesのウェブサイトでモデル評価報告書の全文を見ることができる。
7.微調整モデルの推論能力の評価
比較分析のため、微調整前と同じ質問を微調整後のモデルに対して再度行い、モデル性能の変化を観察した。
question = "A 61-year-old woman with a long history of involuntary urine loss during activities like coughing or sneezing but no leakage at night undergoes a gynecological exam and Q-tip test. Based on these findings, what would cystometry most likely reveal about her residual volume and detrusor contractions?"
FastLanguageModel.for_inference(model) # Unsloth has 2x faster inference!
inputs = tokenizer([prompt_style.format(question, "")], return_tensors="pt").to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=1200,
use_cache=True,
)
response = tokenizer.batch_decode(outputs)
print(response[0].split("### Response:")[1])
実験結果は、微調整されたモデルの出力の質が著しく向上し、回答がより正確になったことを示している。思考の連鎖はより簡潔に示され、最終的な回答はより直接的で、わずか1段落で明確に答えられるようになり、このモデルの微調整が成功したことを示している。

8.モデルのローカルストレージ
ここで、他のプロジェクトで使用するために、アダプタ、フルモデル、およびトークナイザをローカルに保存します。
new_model_local = "DeepSeek-R1-Medical-COT"
model.save_pretrained(new_model_local)
tokenizer.save_pretrained(new_model_local)
model.save_pretrained_merged(new_model_local, tokenizer, save_method="merged_16bit")
9.ハギング・フェイス・ハブにアップロードされたモデル
AIコミュニティがこの微調整されたモデルをフルに活用し、システムに簡単に統合できるようにする目的で、アダプター、トークナイザー、フルモデルもハギング・フェイス・ハブにプッシュされた。
new_model_online = "realyinchen/DeepSeek-R1-Medical-COT"
model.push_to_hub(new_model_online)
tokenizer.push_to_hub(new_model_online)
model.push_to_hub_merged(new_model_online, tokenizer, save_method="merged_16bit")
概要
人工知能(AI)分野は急速な変化を遂げている。オープンソースコミュニティの台頭は、過去3年間プロプライエタリモデルに支配されてきたAIの状況に強い課題を突きつけている。 オープンソースの大規模言語モデル(LLM)は、ますます高速で効率的になっており、少ない計算資源とメモリ資源で、これまで以上に簡単に微調整できるようになっています。
本稿では、その詳細を紹介する。 ディープシークR1 この推論モデルは、医療Q&Aのシナリオに適用するために、ライトバージョンをどのように微調整できるかを詳述している。微調整された推論モデルは、パフォーマンスを大幅に向上させるだけでなく、医学、救急医療、ヘルスケアなどの重要な分野で実用的に使用できる。
DeepSeek R1のリリースを受け、OpenAIはさらに2つの重要なツールを迅速に導入した。 オペレーター 後者は、新しいコンピュータ利用エージェント(CUA: Computer Usage Agent)に依存している。 コンピューター Use Agent)のモデルで、ウェブサイトを自律的にナビゲートし、複雑なタスクを実行する能力を示す。
ソースコード
https://www.kaggle.com/code/realyinchen/deepseek-r1-medical-cot
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事




コメントはありません