
Crawl4AIを使いこなす:LLMとRAGのための高品質ウェブデータの準備

従来のウェブクローラーフレームワークは汎用性が高いが、データを処理する際に追加のクレンジングやフォーマットが必要になることが多く、大規模言語モデル(LLM)との統合が比較的複雑になっている。多くのツールの出力(例えば、生の HTML または非構造化 JSON)は多くのノイズを含んでおり、RAG(Retrieval Augmented Generation)のようなシナリオでの直接使用には適していない。 LLM 処理の効率と正確さ。
クロール4AI は異なる種類のソリューションを提供する。それは、クリーンで構造化された Markdown フォーマットされたコンテンツ。このフォーマットは、ナビゲーション、広告、フッターなどの余計な要素をインテリジェントに取り除きながら、元のテキストの意味的構造(見出し、リスト、コードブロックなど)を保持するもので、以下のような用途に最適です。 LLM 高品質なインプットと構築 RAG データセットCrawl4AI は完全にオープンソースのプロジェクトで API キーもペイ・パー・ビューの基準値には設定されていない。
インストールと設定
推奨用途 紫外線 を作成し、有効化する。 Python プロジェクトの依存関係を管理するための仮想環境。uv これは Rust 先進国 新興国 Python パッケージ・マネージャーは、(通常は pip (3~5倍速い)と効率的な並列依存性解決。
# 创建虚拟环境
uv venv crawl4ai-env
# 激活环境
# Windows
# crawl4ai-env\Scripts\activate
# macOS/Linux
source crawl4ai-env/bin/activate
環境起動後 uv 取り付け Crawl4AI コア・ライブラリー:
uv pip install crawl4ai
インストールが完了したら、初期化コマンドを実行する。 Playwright 必要なブラウザ・ドライバ(例 Chromium)と環境検査を行う。Playwright で成り立っているものだ。 Microsoft によって開発されたブラウザ自動化ライブラリである。Crawl4AI の動的にロードされるコンテンツを扱えるように、実際のユーザー・インタラクションをシミュレートするために使用する。 JavaScript 重いウェブサイト
crawl4ai-setup
ブラウザ・ドライバに関する問題が発生した場合は、手動でインストールしてみてください:
# 手动安装 Playwright 浏览器及依赖
python -m playwright install --with-deps chromium
必要に応じて、次のようにすることができる。 uv 追加機能を含む拡張パックのインストール:
# 安装文本聚类功能 (依赖 PyTorch)
uv pip install "crawl4ai[torch]"
# 安装 Transformers 支持 (用于本地 AI 模型)
uv pip install "crawl4ai[transformer]"
# 安装所有可选功能
uv pip install "crawl4ai[all]"
基本的なクロールの例
それ以下 Python スクリプトは Crawl4AI の基本的な使い方 Markdown.
import asyncio
from crawl4ai import AsyncWebCrawler
async def main():
# 初始化异步爬虫
async with AsyncWebCrawler() as crawler:
# 执行爬取任务
result = await crawler.arun(
url="https://www.sitepoint.com/react-router-complete-guide/"
)
# 检查爬取是否成功
if result.success:
# 输出结果信息
print(f"标题: {result.title}")
print(f"提取的 Markdown ({len(result.markdown)} 字符):")
# 仅显示前 300 个字符作为预览
print(result.markdown[:300] + "...")
# 将完整的 Markdown 内容保存到文件
with open("example_content.md", "w", encoding="utf-8") as f:
f.write(result.markdown)
print(f"内容已保存到 example_content.md")
else:
# 输出错误信息
print(f"爬取失败: {result.url}")
print(f"状态码: {result.status_code}")
print(f"错误信息: {result.error_message}")
if __name__ == "__main__":
asyncio.run(main())
このスクリプトを実行するとCrawl4AI が起動します。 Playwright 特定のブラウザへのアクセスを制御 URL実行ページ JavaScriptそして、主要なコンテンツ領域をインテリジェントに識別・抽出し、散漫な要素をフィルタリングして、最終的にクリーンなコンテンツを生成します。 Markdown ドキュメンテーション
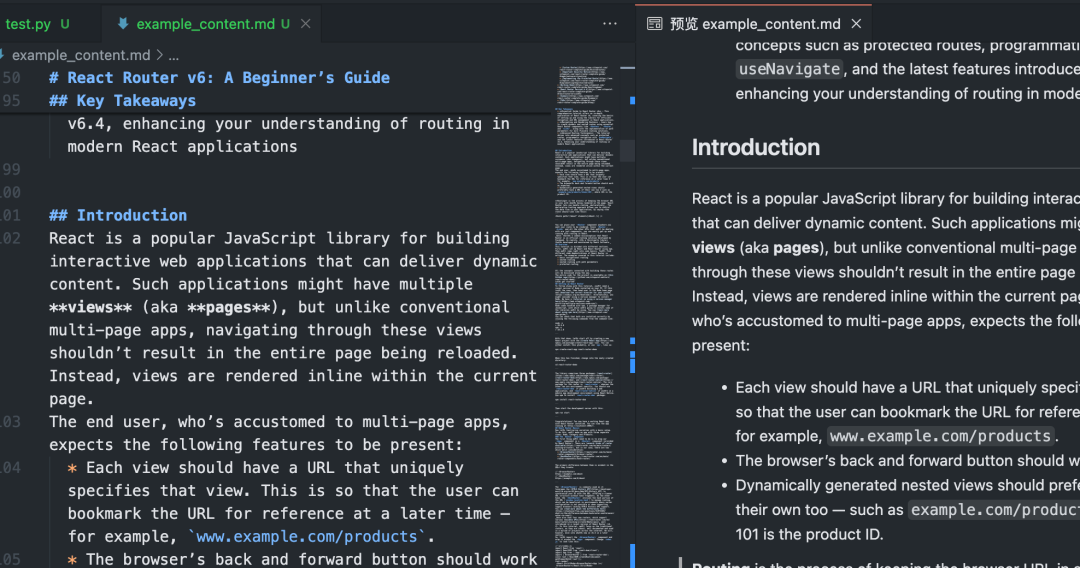
バッチおよび並列クローリング
複数のプロセス URL いつCrawl4AI の並列処理によって、効率を飛躍的に高めることができる。を構成することで CrawlerRunConfig 正鵠を得る concurrency パラメータで、同時に処理するページ数を制御する。
import asyncio
from crawl4ai import AsyncWebCrawler, BrowserConfig, CrawlerRunConfig, CacheMode
async def main():
urls = [
"https://example.com/page1",
"https://example.com/page2",
"https://example.com/page3",
# 添加更多 URL...
]
# 浏览器配置:无头模式,增加超时
browser_config = BrowserConfig(
headless=True,
timeout=45000, # 45秒超时
)
# 爬取运行配置:设置并发数,禁用缓存以获取最新内容
run_config = CrawlerRunConfig(
concurrency=5, # 同时处理 5 个页面
cache_mode=CacheMode.BYPASS # 禁用缓存
)
results = []
async with AsyncWebCrawler(browser_config=browser_config) as crawler:
# 使用 arun_many 进行批量并行爬取
# 注意:arun_many 需要将 run_config 列表传递给 configs 参数
# 如果所有 URL 使用相同配置,可以创建一个配置列表
configs = [run_config.clone(url=url) for url in urls] # 为每个URL克隆配置并设置URL
# arun_many 返回一个异步生成器
async for result in crawler.arun_many(configs=configs):
if result.success:
results.append(result)
print(f"已完成: {result.url}, 获取了 {len(result.markdown)} 字符")
else:
print(f"失败: {result.url}, 错误: {result.error_message}")
# 将所有成功的结果合并到一个文件
with open("combined_results.md", "w", encoding="utf-8") as f:
for i, result in enumerate(results):
f.write(f"## {result.title}\n\n")
f.write(result.markdown)
f.write("\n\n---\n\n")
print(f"所有成功内容已合并保存到 combined_results.md")
if __name__ == "__main__":
asyncio.run(main())
銘記する上記のコードでは arun_many メソッドへの呼び出しをループするのではなく、大きなURLリストを処理するための推奨される方法です。 arun より効率的だ。arun_many コンフィギュレーションのリストが必要です。 URL.もし URL 同じ基本構成で clone() メソッドはコピーを作成し、特定の URL.
構造化データ抽出(セレクタベース)
とは別に Markdown属Crawl4AI こちらも利用可能 CSS セレクターまたは XPath 構造化データを抽出し、通常のデータ形式のサイトに最適です。
import asyncio
import json
from crawl4ai import AsyncWebCrawler, ExtractorConfig
async def main():
# 定义提取规则 (CSS 选择器)
extractor_config = ExtractorConfig(
strategy="css", # 明确指定策略为 CSS
rules={
"products": {
"selector": "div.product-card", # 主选择器
"type": "list",
"properties": {
"name": {"selector": "h2.product-title", "type": "text"},
"price": {"selector": ".price span", "type": "text"},
"link": {"selector": "a.product-link", "type": "attribute", "attribute": "href"}
}
}
}
)
async with AsyncWebCrawler() as crawler:
result = await crawler.arun(
url="https://example-shop.com/products",
extractor_config=extractor_config
)
if result.success and result.extracted_data:
extracted_data = result.extracted_data
with open("products.json", "w", encoding="utf-8") as f:
json.dump(extracted_data, f, ensure_ascii=False, indent=2)
print(f"已提取 {len(extracted_data.get('products', []))} 个产品信息")
print("数据已保存到 products.json")
elif not result.success:
print(f"爬取失败: {result.error_message}")
else:
print("未提取到数据或提取规则匹配失败")
if __name__ == "__main__":
asyncio.run(main())
このアプローチでは LLM 低コストで迅速な介入は、ターゲットとなる要素が明確なシナリオに適している。
AIによるデータ抽出
複雑な構造のページや決まったパターンのないページには LLM インテリジェントな抽出を行う。
import asyncio
import json
from crawl4ai import AsyncWebCrawler, BrowserConfig, AIExtractorConfig
async def main():
# 配置 AI 提取器
ai_config = AIExtractorConfig(
provider="openai", # 或 "local", "anthropic" 等
model="gpt-4o-mini", # 使用 OpenAI 的模型
# api_key="YOUR_OPENAI_API_KEY", # 如果环境变量未设置,在此提供
schema={
"type": "object",
"properties": {
"article_summary": {"type": "string", "description": "A brief summary of the article."},
"key_topics": {"type": "array", "items": {"type": "string"}, "description": "List of main topics discussed."},
"sentiment": {"type": "string", "enum": ["positive", "negative", "neutral"], "description": "Overall sentiment of the article."}
},
"required": ["article_summary", "key_topics"]
},
instruction="Extract the summary, key topics, and sentiment from the provided article text."
)
browser_config = BrowserConfig(timeout=60000) # AI 处理可能需要更长时间
async with AsyncWebCrawler(browser_config=browser_config) as crawler:
result = await crawler.arun(
url="https://example-news.com/article/complex-analysis",
ai_extractor_config=ai_config
)
if result.success and result.ai_extracted:
ai_extracted = result.ai_extracted
print("AI 提取的数据:")
print(json.dumps(ai_extracted, indent=2, ensure_ascii=False))
# 也可以选择保存到文件
# with open("ai_extracted_data.json", "w", encoding="utf-8") as f:
# json.dump(ai_extracted, f, ensure_ascii=False, indent=2)
elif not result.success:
print(f"爬取失败: {result.error_message}")
else:
print("AI 未能提取所需数据。")
if __name__ == "__main__":
asyncio.run(main())
AI抽出は、コンテンツを理解し、オンデマンドで構造化されたアウトプットを生成するための大きな柔軟性を提供しますが、追加の費用が発生します。 API 通話料金(クラウドサービスを利用する場合) LLM)と処理時間。ローカルモデル(例えば Mistral, Llama)は、コストを削減し、プライバシーを保護することができるが、ローカルなハードウェア要件がある。
高度な設定とヒント
Crawl4AI 複雑なシナリオに対処するための豊富な設定オプションを提供します。
ブラウザの設定 (BrowserConfig)
BrowserConfig ブラウザの起動と動作を制御する。
from crawl4ai import BrowserConfig
config = BrowserConfig(
browser_type="firefox", # 使用 Firefox 浏览器
headless=False, # 显示浏览器界面,方便调试
user_agent="MyCustomCrawler/1.0", # 设置自定义 User-Agent
proxy_config={ # 配置代理服务器
"server": "http://proxy.example.com:8080",
"username": "proxy_user",
"password": "proxy_password"
},
ignore_https_errors=True, # 忽略 HTTPS 证书错误 (开发环境常用)
use_persistent_context=True, # 启用持久化上下文
user_data_dir="./my_browser_profile", # 指定用户数据目录,用于保存 cookies, local storage 等
timeout=60000, # 全局浏览器操作超时 (毫秒)
verbose=True # 打印更详细的日志
)
# 在初始化 AsyncWebCrawler 时传入
# async with AsyncWebCrawler(browser_config=config) as crawler:
# ...
ランタイム・コンフィギュレーションをクロールする (CrawlerRunConfig)
CrawlerRunConfig コントロール・シングル arun() もしかしたら arun_many() コールの具体的な動作。
from crawl4ai import CrawlerRunConfig, CacheMode
run_config = CrawlerRunConfig(
cache_mode=CacheMode.READ_ONLY, # 只读缓存,不写入新缓存
check_robots_txt=True, # 检查并遵守 robots.txt 规则
wait_until="networkidle", # 等待网络空闲再提取,适合JS动态加载内容
wait_for="css:div#final-content", # 等待特定 CSS 选择器元素出现
js_code="window.scrollTo(0, document.body.scrollHeight);", # 页面加载后执行 JS 代码 (例如滚动到底部触发加载)
scan_full_page=True, # 尝试自动滚动页面以加载所有内容 (用于无限滚动)
screenshot=True, # 截取页面截图 (结果在 result.screenshot,Base64编码)
pdf=True, # 生成页面 PDF (结果在 result.pdf,Base64编码)
word_count_threshold=50, # 过滤掉少于 50 个单词的文本块
excluded_tags=["header", "nav", "footer", "aside"], # 从 Markdown 中排除特定 HTML 标签
exclude_external_links=True # 不提取外部链接
)
# 在调用 arun() 或创建配置列表给 arun_many() 时传入
# result = await crawler.arun(url="...", config=run_config)
JavaScriptと動的コンテンツを扱う
おかげさまで Playwright属Crawl4AI 依存関係をうまく処理する JavaScript レンダリングされたウェブサイトキーコンフィギュレーション:
wait_untilに設定する。"networkidle"もしかしたら"load"通常、デフォルトの"domcontentloaded"動的なページに適している。wait_for特定の要素を待つかJavaScript条件は満たされている。js_codeページロード後にカスタマイズを実行するJavaScriptボタンをクリックしたり、ページをスクロールしたり。scan_full_page:: 一般的な無限スクロールのページを自動的に処理します。delay_before_return_htmlすべてのスクリプトが実行されるように、抽出の前に短いディレイを追加する。
エラー処理とデバッグ
- プローブ
result.successクロールの後は、必ずこのプロパティをチェックしてください。 - 調べる
result.status_code歌で応えるresult.error_message:: 失敗の理由を知る。 - セットアップ
headless=FalseでBrowserConfigブラウザの動作を観察し、問題を視覚的に診断することができます。 - 使い始める
verbose=TrueでBrowserConfigより詳細なランタイムログを取得するために設定する。 - 利用する
try...except小包arun()もしかしたらarun_many()をキャプチャするPython例外だ。
import asyncio
from crawl4ai import AsyncWebCrawler, BrowserConfig
async def debug_crawl():
# 启用调试模式:显示浏览器,打印详细日志
debug_browser_config = BrowserConfig(headless=False, verbose=True)
async with AsyncWebCrawler(browser_config=debug_browser_config) as crawler:
try:
result = await crawler.arun(url="https://problematic-site.com")
if not result.success:
print(f"Crawl failed: {result.error_message} (Status: {result.status_code})")
else:
print("Crawl successful.")
# ... process result ...
except Exception as e:
print(f"An unexpected error occurred: {e}")
if __name__ == "__main__":
asyncio.run(debug_crawl())
紀律 robots.txt
ウェブクロールを実行する際は、そのサイトの robots.txt 文書化は基本的なネチケットであり、IPブロッキングを防ぐものである。Crawl4AI 自動的に処理できる。
ある CrawlerRunConfig セットアップ check_robots_txt=True::
respectful_config = CrawlerRunConfig(
check_robots_txt=True
)
# result = await crawler.arun(url="https://example.com", config=respectful_config)
# if not result.success and result.status_code == 403:
# print("Access denied by robots.txt")
Crawl4AI 自動的にダウンロード、キャッシュ、解析される robots.txt ファイルへのアクセスを禁止するルールの場合 URL属arun() は失敗するだろう。result.success というのも False属status_code これは通常、適切なエラーメッセージとともに403に表示される。
セッション管理 (Session Management)
ログインや状態の維持が必要なマルチステップの操作(例えば、フォーム送信やページ送 りナビゲーション)には、セッション管理を使うことができる。これは、新しいセッションマネージャーを CrawlerRunConfig で指定する。 session_idこのシステムは、複数の arun() 同じブラウザーページのインスタンスは、呼び出しの間、再利用される。 cookies 歌で応える JavaScript ステータス
import asyncio
from crawl4ai import AsyncWebCrawler, CrawlerRunConfig, CacheMode
async def session_example():
async with AsyncWebCrawler() as crawler:
session_id = "my_unique_session"
# Step 1: Load login page (hypothetical)
login_config = CrawlerRunConfig(session_id=session_id, cache_mode=CacheMode.BYPASS)
await crawler.arun(url="https://example.com/login", config=login_config)
print("Login page loaded.")
# Step 2: Execute JS to fill and submit login form (hypothetical)
login_js = """
document.getElementById('username').value = 'user';
document.getElementById('password').value = 'pass';
document.getElementById('loginButton').click();
"""
submit_config = CrawlerRunConfig(
session_id=session_id,
js_code=login_js,
js_only=True, # 只执行 JS,不重新加载页面
wait_until="networkidle" # 等待登录后跳转完成
)
await crawler.arun(config=submit_config) # 无需 URL,在当前页面执行 JS
print("Login submitted.")
# Step 3: Crawl a protected page within the same session
protected_config = CrawlerRunConfig(session_id=session_id, cache_mode=CacheMode.BYPASS)
result = await crawler.arun(url="https://example.com/dashboard", config=protected_config)
if result.success:
print("Successfully crawled protected page:")
print(result.markdown[:200] + "...")
else:
print(f"Failed to crawl protected page: {result.error_message}")
# 清理会话 (可选,但推荐)
# await crawler.crawler_strategy.kill_session(session_id)
if __name__ == "__main__":
asyncio.run(session_example())
より高度なセッション管理には、ブラウザの保存状態のエクスポートとインポート (cookies, localStorage)、スクリプトの実行間でログインを維持できるようにする。
Crawl4AI 強力で柔軟な機能セットを提供し、適切に設定すれば、さまざまなウェブサイトから必要な情報を効率的かつ確実に抽出し、下流のAIアプリケーション用に高品質なデータを準備することができます。
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事



コメントはありません