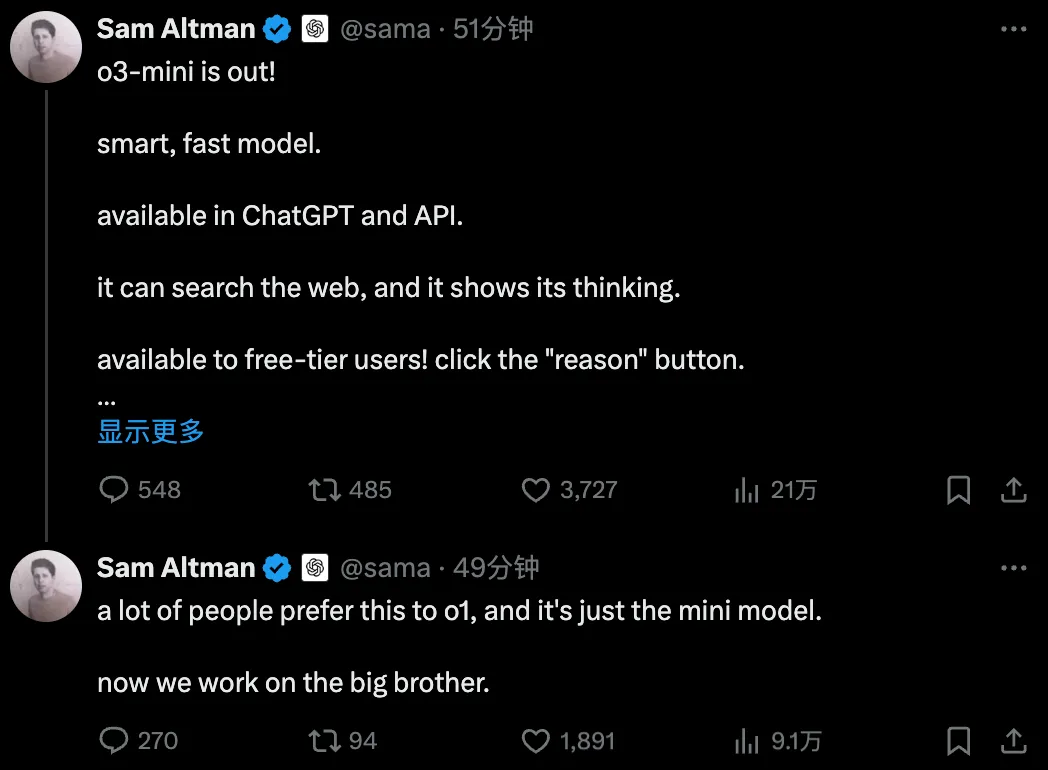
Jina Embeddings v2からv3への移行ガイド


Jina Embeddings v3 最新の5億7000万パラメータを持つトップレベル・テキスト・ベクトル・モデルは、多言語・長文検索タスクにおいて現在クラス最高のSOTAを達成。
v3はより強力になっただけでなく、新しくエキサイティングな機能をたくさん備えています。2023年10月にリリースされたJina Embeddings v2をまだお使いの方は、できるだけ早くv3に移行されることを強くお勧めします。
まずは、Jina Embeddings v3のハイライトを簡単に紹介しよう:
- 89言語をサポート v2が数カ国語しか扱えないという制約を打破し、真の多言語テキスト処理を実現。
- ローラ・アダプター内蔵v2は一般的なEmbeddingモデルで、v3は検索、分類、クラスタリング、その他のタスクに最適化されたベクトルを生成するLora Adapterを内蔵しています。
- 長文検索はより正確 :: 8192のV3利用 トークン より豊富な文脈情報を持つブロックベクトルを生成するレイトチャンキング技術は、長文検索の精度を大幅に向上させることができる。
- ベクトル寸法は柔軟で制御可能 v3のベクトル次元は、パフォーマンスと記憶容量のバランスを取るために柔軟に調整することができ、高次元ベクトルに伴う高い記憶容量のオーバーヘッドを回避することができる。これはマトリョーシカ表現学習(MRL)によって実現されています。
オープンソースモデルへのリンク:https://huggingface.co/jinaai/jina-embeddings-v3
モデル API リンク:https://jina.ai/?sui=apikey
モデルペーパーへのリンク:https://arxiv.org/abs/2409.10173
クイック移行ガイド
- v3は全く新しいモデルなので、v2のベクトルやインデックスをそのまま再利用することはできず、再度データのインデックスを作成する必要があります。
- ほとんどのシナリオ(96%)において、v3はv2を大きく上回るが、v2は英語の要約タスクにおいてv3と同点、あるいはわずかに上回る程度である。しかし、v3の多言語サポートと高度な機能を考えると、ほとんどのシナリオでv3が好まれるはずである。
- v3 API には以下が含まれるようになりました。
taskそしてdimensions歌で応えるlate_chunking3つのパラメータがあり、正確な使い方はブログ記事を参照されたい。
寸法調整
- v3はデフォルトで1024次元のベクトルを出力するが、v2は768次元しかない。マトリョーシカ表現学習により、v3は理論的にはどの次元でも出力できるようになった。開発者は
dimensionsパラメータで出力ベクトルの次元数を柔軟に制御し、ストレージ・コストとパフォーマンスの最適なバランスを見つける。 - 以前のプロジェクトがv2 APIに基づいて開発されていた場合は、モデル名を直接次のように変更してください。
jina-embeddings-v3は、デフォルトの寸法が変更されたため不可能です。データ構造やサイズをv2と同じにしたい場合はdimensions=768同じ次元であっても、v3とv2のベクトルの分布は全く異なる。たとえ次元が同じであっても、v3とv2のベクトルは意味空間上で全く異なる分布を持つため、直接互換性を持って使用することはできない。
モデル交換
- v3の強力な多言語サポートは、v2(v2-base-de、v2-base-es、v2-base-zh)のバイリンガルモデルに完全に取って代わりました。
- 純粋なコーディングタスクでは、jina-embeddings-v2-based-codeが依然として最良の選択である。テストによると、v3ジェネリックベクター(タスクセットなし)の0.7537、LoRAアダプターの0.7564と比較して、0.7753という高いスコアを出しており、v2エンコーディングはv3に対して約2.8%の性能リードを与えている。
ミッション・パラメーター
- v3 APIは、タスク・パラメータが指定されていない場合、良質なジェネリック・ベクトルを生成しますが、より良いベクトル表現を得るためには、特定のタスク・タイプに応じてタスク・パラメータを設定することを強く推奨します。
- v3がv2の動作をエミュレートするには
task="text-matching"最適な解決策を見つけるために、さまざまなタスクオプションを試してみることをお勧めします。text-matching普遍的なプログラムとして。 - プロジェクトで情報検索にv2を使用している場合、検索タスク・タイプをv3に切り替えることを推奨する(
retrieval.passage歌で応えるretrieval.query)であれば、より良い検索結果を得ることができる。
その他の考慮事項
- 全く新しいタスクタイプ(これはまれである)の場合、出発点としてタスクパラメーターをNoneに設定してみてください。
- もしv2でゼロサンプル分類タスクにラベル書き換えテクニックを使ったなら、v3では単に
task="classification"v3が分類タスクのためにベクトル表現を最適化したため、同様の効果が得られる。 - v2もv3も最大8192トークンのコンテキスト長をサポートするが、v3はFlashAttention2テクノロジーのおかげでより効率的であり、v3のレイトスコア機能の基礎を築く。

レイト・チャンキング
- v3では、8192個のトークンを使って長い文脈を形成し、それをベクトルに分割するレイトスプリッティング機能を導入している。
late_chunking現在のところAPIでのみ利用可能なので、ローカルでモデルを走らせている場合は、しばらくこの機能を使うことはできない。- 使い始める
late_chunkingv3は一度に処理できるコンテンツの量が限られているため、各リクエストのテキスト長は8192トークンを超えてはならない。
パフォーマンスとスピード
- スピードの面では、v3はv2の3倍のパラメータを持っているにもかかわらず、推論はv2より速いか、少なくとも同等である。これは主にFlashAttention2テクノロジーによるものである。
- すべてのGPUがFlashAttention2に対応しているわけではありません。対応していないGPUを使用している場合でもv3は動作しますが、v2より若干遅くなる可能性があります。
- APIを使用する場合、ネットワークのレイテンシー、レート制限、アベイラビリティゾーンなどの要因もレイテンシーに影響するため、APIのレイテンシーはv3モデルの真のパフォーマンスを完全に反映するものではない。
v2と異なり、Jina Embeddings v3はCC BY-NC 4.0でライセンスされています。v3は、私たちのAPI、AWS、またはAzureを介して商業的に使用することができます。研究や非商業的な使用は問題ありません。ローカルの商業的な展開については、ライセンスについて私たちの営業チームに連絡してください:
https://jina.ai/contact-sales
多言語サポート
v3は現在、業界をリードする多言語ベクトルモデル**であり、M*****TEBチャートでは、10億以下のパラメータを持つモデルで2位にランクされています。**世界の主要言語のほとんどをカバーする89言語をサポートしています。
中国語、英語、日本語、韓国語、ドイツ語、スペイン語、フランス語、アラビア語、ベンガル語、デンマーク語、オランダ語、フィンランド語、グルジア語、ギリシャ語、ヒンディー語、インドネシア語、イタリア語、ラトビア語、ノルウェー語、ポーランド語、ポルトガル語、ルーマニア語、ロシア語、スロバキア語、スウェーデン語、タイ語、トルコ語、ウクライナ語、ウルドゥー語、ベトナム語。トルコ語、ウクライナ語、ウルドゥー語、ベトナム語。
v2の英語モデル、英語/ドイツ語モデル、英語/スペイン語モデル、英語/中国語モデルを使用していた場合は、次のように変更するだけです。 model パラメータを選択し、適切な task タイプであれば、簡単にv3に切り替えることができる。
# v2 英语-德语
data = {
"model": "jina-embeddings-v2-base-de",
"input": [
"The Force will be with you. Always.",
"Die Macht wird mit dir sein. Immer.",
"The ability to destroy a planet is insignificant next to the power of the Force.",
"Die Fähigkeit, einen Planeten zu zerstören, ist nichts im Vergleich zur Macht der Macht."
]
}
# v3 多语言
data = {
"model": "jina-embeddings-v3",
"task": "retrieval.passage",
"input": [
"The Force will be with you. Always.",
"Die Macht wird mit dir sein. Immer.",
"力量与你同在。永远。",
"La Forza sarà con te. Sempre.",
"フォースと共にあらんことを。いつも。"
]
}
response = requests.post(url, headers=headers, json=data)
タスク固有のベクトル表現
v2は一般的なベクトル表現を使用し、すべてのタスクが同じモデルを共有する。v3は、特定のシナリオでパフォーマンスを向上させるために、タスク(検索、分類、クラスタリングなど)ごとに最適化されたベクトル表現を提供する。
異なるものを選択する task これは、そのタスクに関連する特徴を抽出するようモデルに指示することと同じで、タスクの要件により適したベクトル表現を生成する。
以下はLightsaber Repair Knowledge Baseの例で、v2のコードをv3に移行し、タスク固有のベクトル表現によるパフォーマンス向上を体験する方法を示している:
# 实际项目中我们会使用更大的数据集,这个只是示例
knowledge_base = [
"为什么我的光剑刀锋在闪烁?刀锋闪烁可能表示电池电量不足或不稳定的水晶。请为电池充电并检查水晶的稳定性。如果闪烁持续,可能需要重新校准或更换水晶。",
"为什么我的刀锋比以前暗淡?刀锋变暗可能意味着电池电量低或电源分配有问题。首先,请为电池充电。如果问题仍然存在,可能需要更换LED。",
"我可以更换我的光剑刀锋颜色吗?许多光剑允许通过更换水晶或使用剑柄上的控制面板更改颜色设置来自定义刀锋颜色。请参阅您的型号手册以获得详细说明。",
"如果我的光剑过热,我该怎么办?过热可能是由于长时间使用导致的。关闭光剑并让其冷却至少10分钟。如果频繁过热,可能表明内部问题,需由技术人员检查。",
"如何为我的光剑充电?通过剑柄附近的端口,将光剑连接到提供的充电线,确保使用官方充电器以避免损坏电池和电子设备。",
"为什么我的光剑发出奇怪的声音?奇怪的声音可能表示音响板或扬声器有问题。尝试关闭光剑并重新开启。如果问题仍然存在,请联系我们的支持团队以更换音响板。"
]
query = "光剑太暗了"
v2では、タスクは1つ(テキスト・マッチング)だけなので、コード・ブロックの例は1つだけでよい:
# v2 代码:使用文本匹配任务对知识库和查询进行编码
data = {
"model": "jina-embeddings-v2-base-en",
"normalized": True, # 注意:v3 中不再需要此参数
"input": knowledge_base
}
docs_response = requests.post(url, headers=headers, json=data)
data = {
"model": "jina-embeddings-v2-base-en",
"task": "text-matching",
"input": [query]
}
query_response = requests.post(url, headers=headers, json=data)
v3は、検索、分離、分類、テキストマッチングなど、特定のタスクに最適化されたベクトル表現を提供する。
検索タスクのベクトル表現
単純なライトセーバー修理知識ベースを例として、テキスト検索タスクを扱う際のv2とv3の違いを示す。
意味検索タスクでは、v3はそれぞれ retrieval.passage 歌で応える retrieval.query 検索性能と精度を向上させるために、文書とクエリをコーディングする。
ドキュメントのコーディング: retrieval.passage
data = {
"model": "jina-embeddings-v3",
"task": "retrieval.passage", # "task" 参数是 v3 中的新功能
"late_chunking": True,
"input": knowledge_base
}
response = requests.post(url, headers=headers, json=data)
クエリーコード retrieval.query
data = {
"model": "jina-embeddings-v3",
"task": "retrieval.query",
"late_chunking": True,
"input": [query]
}
response = requests.post(url, headers=headers, json=data)
注:上記のコードはlate_chunking関数は、長いテキストのエンコーディングを強化するもので、後で詳しく紹介する。
ライトセーバーは暗すぎる」というクエリに対するv2とv3のパフォーマンスを比較してみましょう。v2は、コサイン類似度に基づき、以下のように関連性の低いマッチのセットを返します:

対照的に、v3はクエリの意図をよりよく理解し、以下に示すように、「ライトセーバーの刃の外観」に関連するより正確な結果を返す。

v3は検索だけでなく、いくつかのタスクに特化したベクトル表現も提供している:
分離タスクのベクトル表現
v3 separation タスクは、クラスタリング、再ランク付けなどの分離タスクに最適化されており、例えば、異なるタイプのエンティティを分離することで、大規模なコーパスの整理や視覚化に役立つ。
例:スター・ウォーズとディズニーのキャラクターの区別
data = {
"model": "jina-embeddings-v3",
"task": "separation", # 使用 separation 任务
"late_chunking": True,
"input": [
"Darth Vader",
"Luke Skywalker",
"Mickey Mouse",
"Donald Duck"
]
}
response = requests.post(url, headers=headers, json=data)
分類タスクのベクトル表現
v3 classification このタスクは、例えばテキストを肯定的なコメントと否定的なコメントに分類するような、感情分析や文書分類のようなテキスト分類タスクに最適化されている。
例:スター・ウォーズの映画評の感情的傾向の分析
data = {
"model": "jina-embeddings-v3",
"task": "classification",
"late_chunking": True,
"input": [
"《星球大战》是一部划时代的杰作,彻底改变了电影业,并永远重新定义了科幻电影!",
"《星球大战》拥有令人惊叹的视觉效果、令人难忘的角色和传奇的叙事,是一部无与伦比的文化现象。",
"《星球大战》是一场过度炒作的灾难,充满了浅薄的角色,毫无有意义的情节!",
}
response = requests.post(url, headers=headers, json=data)
テキストマッチングのベクトル表現
v3 text-matching 文の類似性や、繰り返される文や段落を除外するなどの強調除去など、意味的類似性のタスクに焦点を当てる。
例:スター・ウォーズのセリフの繰り返しを識別する
data = {
"model": "jina-embeddings-v3",
"task": "text-matching",
"late_chunking": True,
"input": [
"Luke, I am your father.",
"No, I am your father.",
"Fear leads to anger, anger leads to hate, hate leads to the dark side.",
"Fear leads to anger. Anger leads to hate. Hate leads to suffering."
]
}
response = requests.post(url, headers=headers, json=data)
後期チャンキング:長文エンコーディングの強化
v3では late_chunking パラメータが late_chunking=True モデルが文書全体を処理した後、それを複数のブロックに分割し、完全な文脈情報を含むブロックベクトルを生成する場合。 late_chunking=False モデルが各ブロックを独立して処理する場合、生成されるブロックベクトルにはブロック間の文脈情報が含まれない。
銘記する
- 使い始める
late_chunking=TrueAPIリクエストごとのトークンの総数は、v3でサポートされるコンテキストの最大長である8192を超えることはできない。 late_chunking=Falseトークンの総数に制限はありませんが、Embeddings APIのレート制限に従います。
長いテキストを処理するには late_chunkingチャンク全体の文脈情報を保持し、生成されるベクトル表現をより完全で正確なものにするためである。
チャットの記録を用いて評価した。 late_chunking 長文検索の有効性への影響。
history = [
"Sita,你决定好周六生日晚餐要去哪儿了吗?",
"我不确定,对这里的餐厅不太熟悉。",
"我们可以上网看看推荐。",
"那听起来不错,我们就这么办吧!",
"你生日那天想吃什么类型的菜?",
"我特别喜欢墨西哥菜或者意大利菜。",
"这个地方怎么样,Bella Italia?看起来不错。",
"哦,我听说过那个地方!大家都说那儿很好!",
"那我们订张桌子吧?",
"好,我觉得这会是个完美的选择!我们打电话预定吧。"
]
v2を使って、"お勧めのレストランを教えてください "というクエリを実行した。というクエリにv2を使用したところ、得られた結果は特に関連性のあるものではありませんでした。

v3でレイトチャンキングを有効にしていない場合、結果は同様に満足のいくものではなかった。

ただし、v3を使用し late chunking 最も関連性の高い結果(おいしいレストランの推薦)がまさに1位になったとき。

検索結果

検索結果から明らかなように late_chunking その後、v3はクエリに関連するチャットをより正確に識別し、最も関連性の高い結果を最初にランク付けすることができる。
また、次のことも示している。 late_chunking<span> </span>長文検索の精度は、特に文脈的な意味を深く理解する必要があるシナリオにおいて、効果的かつ効率的に向上させることができる。
ロシア語のネストされたベクトルを使って、バランシングの効率とパフォーマンスを表す
v3採用 dimensions パラメータは柔軟なベクトル次元制御をサポートし、実際の需要に応じて出力ベクトルの次元を調整し、パフォーマンスとストレージスペースのバランスを取ることができます。
ベクトル次元を小さくすることで、ベクトルデータベースのストレージオーバーヘッドを削減し、検索速度を向上させることができるが、一部の情報が失われ、パフォーマンスが低下する可能性がある。
data = {
"model": "jina-embeddings-v3",
"task": "text-matching",
"dimensions": 768, # 设置向量维度为 768,默认值为 1024
"input": [
"The Force will be with you. Always.",
"力量与你同在。永远。",
"La Forza sarà con te. Sempre.",
"フォースと共にあらんことを。いつも。"
]
}
response = requests.post(url, headers=headers, json=data)
一般的な問題
Q1: ベクトル化する前にすでにチャンク化されている場合、レイト・チャンキングを使う利点は何ですか?
A1: プレ・スプリットに対するレイト・スプリットの利点は、次のようなことである。 チャンキングの前に文書全体を処理することで、より完全な文脈情報を保持します。 .チャンキングを遅らせることは、複雑な文書や長い文書を処理する際に重要である。チャンキングを行う前に、モデルが文書を全体的に理解しているため、検索時に関連性の高い応答を提供することができる。一方、セグメンテーション前のブロックは、完全な文脈のないブロックとは独立して処理される。
Q2: ペアワイズ分類タスクでv2がv3よりベンチマークスコアが高いのはなぜですか?心配する必要はありますか?
A2:v2のペアワイズ分類タスクのスコアが高いように見えるのは、主に平均スコアの計算方法が異なるためです。v3のテストセットにはより多くの言語が含まれているため、平均スコアはv2よりも低くなる可能性があります。
Q3: v2バイリンガルモデルでサポートされている特定の言語では、v3の方が優れていますか?
A3:特定の言語に対するv3とv2のバイリンガルモデルのパフォーマンス比較 特定の言語とタスクの種類による v2のバイリンガルモデルは、特定の言語に対して高度に最適化されているため、特定のタスクにおいてより優れたパフォーマンスを発揮する可能性があります。しかしv3は、より広範な多言語シナリオをサポートするように設計されており、より強力な言語横断的汎化機能を持ち、タスク固有のLoRAアダプタによって様々な下流タスクに最適化されている。その結果、v3は通常、多言語にわたって、あるいは意味検索やテキスト分類などのより複雑なタスク固有のシナリオにおいて、より優れた総合性能を達成する。
v2バイリンガルモデルがサポートする特定の言語(中国語-英語、英語-ドイツ語、スペイン語-英語)のみを扱う必要があり、タスクが比較的単純な場合、v2は依然として良い選択であり、場合によってはより良いパフォーマンスを発揮する可能性さえあります。
しかし、複数の言語を扱う必要がある場合や、タスクがより複雑な場合(例えば、意味検索やテキスト分類を実行する必要がある場合)には、強力な言語横断的汎化機能と下流タスクに基づく最適化ストラテジーを備えたv3がより良い選択となる。
Q4: なぜv2がv3よりもサマリータスクで優れているのですか?
A4: v2は要約タスクでより良い結果を出しているが、その主な理由は、そのモデル・アーキテクチャが、要約タスクと密接に関連する意味類似性などのタスクに特に最適化されているためである。
しかし、要約タスクの評価は現在、意味的類似性を測定するテストであるSummEvalに依存しており、要約タスクにおけるモデルの総合的な能力を完全に表しているわけではないので、あまり心配する必要はない。v3が検索などの他の重要なタスクで優れた性能を発揮していることを考えると、要約タスクにおけるわずかな性能差は、通常、実世界のアプリケーションに大きな影響を与えない。
概要
Jina Embeddings v3は、多言語・長文検索タスクのためのクラス最高のSOTAを大幅にアップグレードしたモデルであり、より正確なベクトル化結果のニーズに応じて、検索、クラスタリング、分類、マッチングといった様々なシナリオ用にカスタマイズ可能な様々なLoRAアダプターが組み込まれています。できるだけ早くv3に移行されることを強くお勧めします。
以上、Jina Embeddings v3についてご紹介しましたが、ご参考になれば幸いです。ご質問があれば、お気軽にコメントを残してください!
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事


コメントはありません