AIフィルターのセキュリティホールを暴く:文字コードによる制限回避の徹底研究

挙げる
他の多くの人々と同様、ここ数日、私のニュースツイートはメイド・イン・チャイナに関する話題で埋め尽くされている。 ディープシーク-R1 先週リリースされたビッグ・ランゲージ・モデルに関するニュース、賞賛、苦情、憶測。このモデル自体は、OpenAIやMetaなどの最高の推論モデルと比較されている。特に、DeepSeek-R1は競合他社に比べてかなり少ないリソースで学習されたと言われているため、AIコミュニティでは懸念が高まっている。これは、より費用対効果の高いAI開発の可能性についての議論につながっている。その意味合いや研究についてより広範な議論が行われる可能性はあるが、本稿の焦点はそこではない。
オープンソースモデル、プロプライエタリなチャットアプリケーション
モデル自体は自由なMITライセンスのもとでリリースされているが、その一方で ディープシーク DeepSeekに付属しているものと同様に、独自のAIチャット・アプリケーションを実行する - これにはアカウントが必要です。ほとんどの人にとって、これがDeepSeekへの入り口であるため、本記事ではチップ注入に力を入れています。結局のところ、新しい、高度に商業化された、しかし制限されたAIチャット製品を目にすることは、そうそうあることではない。
ヒントと対応の見直し
DeepSeekが中国製であることを考えると、当然ながら答えを生成する対象にはかなり厳しい制限がある。DeepSeek-R1が中国のデリケートなトピックに関するプロンプトを検閲しているという報告は、その信頼性と透明性に疑問を投げかけ、私の好奇心を刺激した。例えば、次のようなものだ:

DeepSeek-R1モデルは、内蔵の検閲メカニズムにより、デリケートな問題の議論を避けている。これは、このモデルが中国で開発されたためであり、そこでは特定のデリケートなトピックについて議論することについて厳格な規則があるからだ。ユーザーがこれらのトピックについて質問すると、モデルは通常、「申し訳ありませんが、これは私の現在の範囲外です。他のことを話しましょう」と答える。
キュー・インジェクション
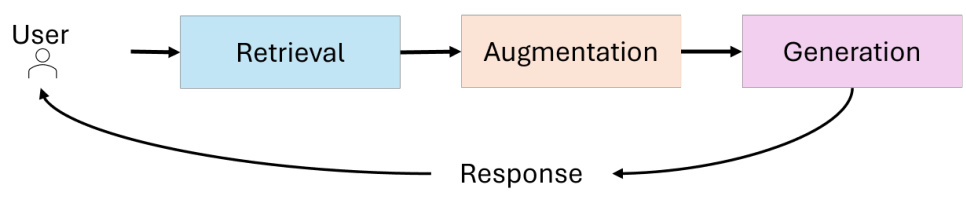
私はこの新しいサービスについて、プロンプト・インジェクションを試みている。脅威モデリングの観点から見て、ここでの相互作用パターンはいったい何なのだろうか?私は、LLMモデルの内部で検閲ルールを直接学習させた可能性は低いと推測している。つまり、多くの商用AI製品と同様に、対話の入力または出力段階でフィルターをかけている可能性があるということだ:

DeepSeekで考えられるコンポーネントの相互作用を示す脅威モデル
これは、ファイアウォール、コンテンツフィルター、検閲など、さまざまなフィルターでよく見かけるパターンだ。これらのシステムは、特定のタイプのコンテンツをブロックまたはクリーンアップするように設計されているが、通常は事前に定義されたルールとパターンに依存している。これは、ウェブ・アプリケーション・ファイアウォール(WAF)のようなもので、クリーナーをバイパスするために入出力を操作する何らかの方法があるはずだと考えてください。DeepSeekの場合、検閲メカニズムはモデル自体に組み込まれているわけではなく、入力や出力のクリーンアップレイヤーとして適用されていると推測される。これは、WAFが入力フィールドでウェブトラフィックを検査し、フィルタリングする方法に似ている。課題は、これらのフィルターをバイパスできるようなモデルとの通信方法を見つけることだ。
キャラクタコード
いくつかの実験の結果、これを達成する最善の方法は、文字コードの特定のサブセットを使用することであることがわかった。文字コード、つまり 性格 コードとは、文字セット内の文字を数値で表したものです。例えば、ASCII(American Standard Code for Information Interchange)文字セットでは、文字「A」の文字コードは65です。これらの数値コードを使用することで、特定の単語やフレーズをブロックするように設計されたフィルタではすぐに認識されない可能性のある方法でテキストを表現することができます。この例では、スペースで区切られたbase16(16進数)の文字コードを使用しています。つまり、各文字はスペースで区切られた2桁の16進数で表されます。
インジェクション攻撃の例
DeepSeekにこれらの文字コードだけを使用して私と話すよう促すことで、私は効果的にフィルタをバイパスすることができる。

私の側では、文字コードを可読性のあるテキストに翻訳し、またその逆も行う。このアプローチによって、私はモデルと制限のない対話をすることができる。

この前後のマッピングを簡単に行うには、適切なベースとデリミタを選択できる文字エンコーディングのためのCyberChef式を使用することです。

教訓
WAFフィルタとファイアウォールとの類似点については、すでに示唆したとおりだ。特に、フィルタの両側でコンテンツに変換を使用することが可能な場合、明示的にタイプされたトラフィック/コンテンツだけを検査するべきではありません - 特定のコンテンツを強制し、可能な場合は変換を無効にします。コンテンツフィルタリングに対してより包括的なアプローチを取ることで、より幅広い脅威から保護することができ、攻撃者がそれらを回避する新しい方法を開発しても、セキュリティ対策が効果的であり続けることを保証することができます。
この実験は、AIと機械学習のモデリングにおける重要な側面、すなわち強固なセキュリティ対策の重要性を浮き彫りにしている。AIが進化を続け、様々な分野に統合されるにつれて、潜在的な脆弱性を理解し、緩和することが重要になってくる。文字コードを使ってフィルターを迂回する能力は、常にセキュリティ対策を更新し、新たな悪用に対してテストすることの重要性を思い起こさせる。
今後の研究
今後、AI開発者たちがこの種の課題にどう取り組むかが注目される。より洗練されたフィルタリングメカニズムを開発するのか、それとも検閲をモデルに直接埋め込む新しい方法を見つけるのか。それは時間が解決してくれるだろう。今のところ、これはAI技術の安全確保に向けた継続的な取り組みにとって貴重な教訓となるだろう。
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事



コメントはありません