
ビッグモデル幻想の解明:HHEMランキングは、LLMにおける事実の一貫性の現状に洞察を与える

大規模言語モデル(Large Language Models: LLM)の機能は日進月歩で進化しているが、その出力に含まれる原文とは無関係な情報の事実誤認や「錯覚」現象は、LLMの普及と信頼の深化を妨げる大きな課題であった。この問題を定量的に評価するためにヒューズ幻覚評価モデル(HHEM)ランキングは、ドキュメントの要約を生成する際に、主流のLLMにおけるファンタズムの頻度を測定することに焦点を当てて作成された。
錯覚」とは、元の文書に含まれていない、あるいは矛盾している「事実」をモデルが要約に導入することを指す。これは、LLMに依存する情報処理シナリオ、特にRAG(Retrieval Augmented Generation:検索拡張生成)に基づく情報処理シナリオにとって、重大な品質上のボトルネックとなる。結局のところ、モデルが与えられた情報に忠実でなければ、その出力の信頼性は大幅に低下する。
HHEMの仕組みは?
このランキングは、Vectaraが開発した幻覚評価モデルHHEM-2.1を使用している。その仕組みは、ソース文書と特定のLLMによって作成された要約に対して、HHEMモデルが0から1の間の幻覚スコアを出力するというものである。スコアが1に近ければ近いほど、ソース文書と要約の事実上の整合性が高いことを意味し、0に近ければ近いほど、幻覚がよりひどい、あるいは完全に捏造された内容であることを意味する。Vectaraはまた、研究者や開発者がローカルで評価を実行できるように、オープンソース版のHHEM-2.1-Openを提供しており、そのモデルカードはHugging Faceプラットフォームで公開されている。
評価ベンチマーク
評価では、主に古典的なCNN/Daily Mailコーパスのような一般に利用可能なデータセットから、1006の文書からなるデータセットを使用した。プロジェクトチームは、評価に関与した個々のLLMを使用して各文書の要約を生成し、各対(ソース文書、生成された要約)についてHHEMスコアを計算した。評価の標準化を確実にするため、すべてのモデルコールを temperature このパラメータは0であり、モデルの最も決定論的な出力を得ることを目的としている。
評価指標には特に以下のものが含まれる:
- 幻覚率。 HHEMスコアが0.5未満の抄録の割合。値が低いほど良い。
- 事実の一致率。 100%から幻覚率を引いたもので、原文に忠実な内容の抄録の割合を反映している。
- 回答率。 空でない要約の生成に成功したモデルの割合。コンテンツセキュリティポリシーやその他の理由により、回答を拒否したり、エラーを出すモデルもある。
- 要約の平均的な長さ。 生成された要約の平均単語数は、モデルの出力スタイルを横から見ることができる。
LLMイリュージョン・ランキング
以下は、HHEM-2.1モデル評価に基づくLLM幻覚ランキングである(データは2025年3月25日現在、実際の更新情報を参照):
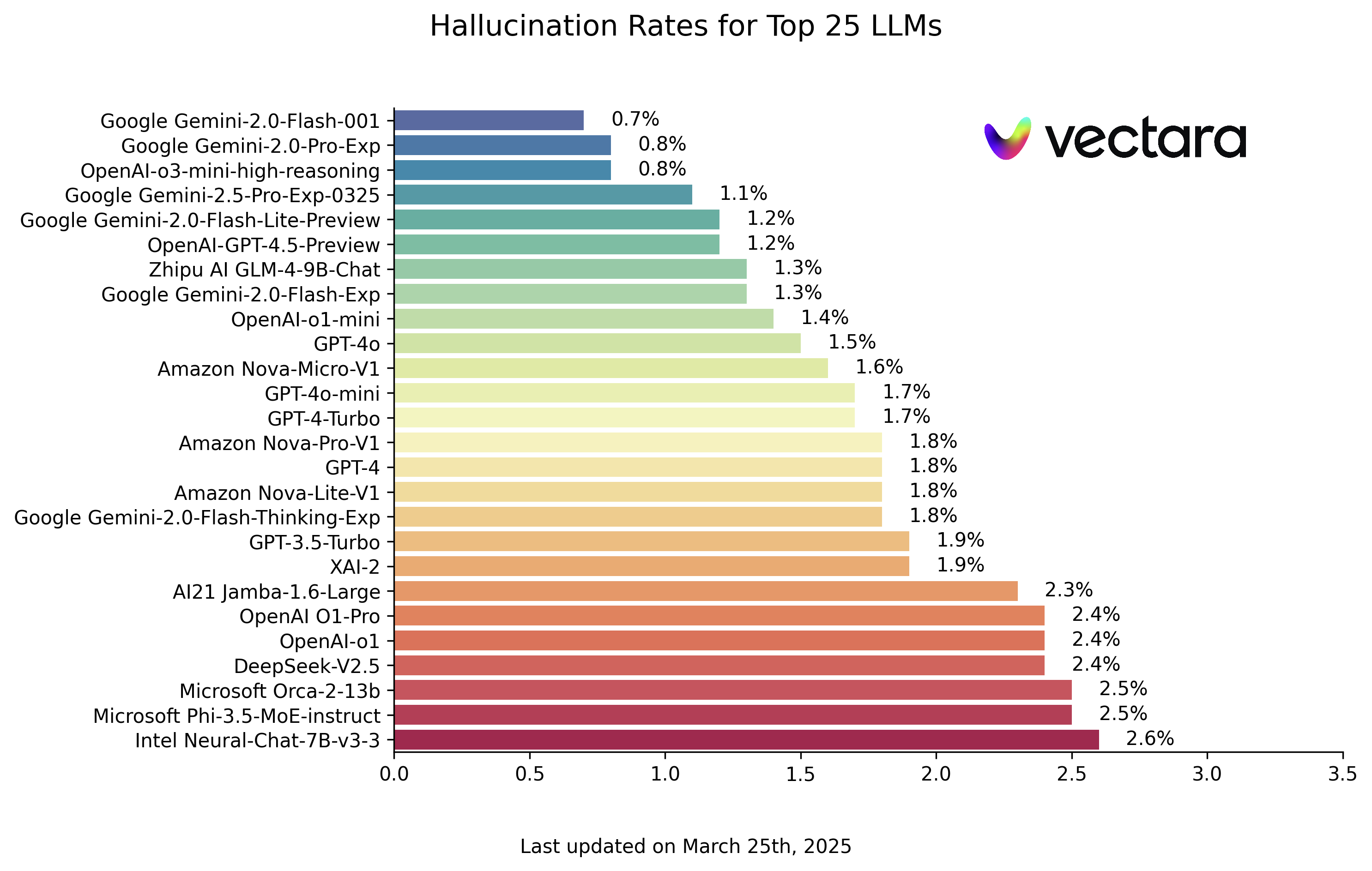
| モデル | 幻覚率 | 事実一致率 | 回答率 | 要約の平均長さ(ワード) |
|---|---|---|---|---|
| グーグル ジェミニ-2.0-Flash-001 | 0.7 % | 99.3 % | 100.0 % | 65.2 |
| グーグル ジェミニ-2.0-プロ-Exp | 0.8 % | 99.2 % | 99.7 % | 61.5 |
| OpenAI-o3-ミニ高推論 | 0.8 % | 99.2 % | 100.0 % | 79.5 |
| グーグル ジェミニ-2.5-プロ-Exp-0325 | 1.1 % | 98.9 % | 95.1 % | 72.9 |
| Google Gemini-2.0-フラッシュライト-プレビュー | 1.2 % | 98.8 % | 99.5 % | 60.9 |
| OpenAI-GPT-4.5-プレビュー | 1.2 % | 98.8 % | 100.0 % | 77.0 |
| Zhipu AI GLM-4-9B-チャット | 1.3 % | 98.7 % | 100.0 % | 58.1 |
| グーグル ジェミニ-2.0-フラッシュ-Exp | 1.3 % | 98.7 % | 99.9 % | 60.0 |
| オープンAI-o1-ミニ | 1.4 % | 98.6 % | 100.0 % | 78.3 |
| GPT-4o | 1.5 % | 98.5 % | 100.0 % | 77.8 |
| アマゾン・ノヴァマイクロ-V1 | 1.6 % | 98.4 % | 100.0 % | 90.0 |
| GPT-4o-ミニ | 1.7 % | 98.3 % | 100.0 % | 76.3 |
| GPT-4-ターボ | 1.7 % | 98.3 % | 100.0 % | 86.2 |
| Google Gemini-2.0-Flash-Thinking-Expについて | 1.8 % | 98.2 % | 99.3 % | 73.2 |
| アマゾン Nova-Lite-V1 | 1.8 % | 98.2 % | 99.9 % | 80.7 |
| GPT-4 | 1.8 % | 98.2 % | 100.0 % | 81.1 |
| アマゾン・ノヴァプロ-V1 | 1.8 % | 98.2 % | 100.0 % | 85.5 |
| GPT-3.5ターボ | 1.9 % | 98.1 % | 99.6 % | 84.1 |
| XAI-2 | 1.9 % | 98.1 | 100.0 % | 86.5 |
| AI21 ジャンバ-1.6-ラージ | 2.3 % | 97.7 % | 99.9 % | 85.6 |
| オープンAI O1プロ | 2.4 % | 97.6 % | 100.0 % | 81.0 |
| オープンAI-o1 | 2.4 % | 97.6 % | 99.9 % | 73.0 |
| DeepSeek-V2.5 | 2.4 % | 97.6 % | 100.0 % | 83.2 |
| マイクロソフト オルカ-2-13b | 2.5 % | 97.5 % | 100.0 % | 66.2 |
| マイクロソフトPhi-3.5-MoE-インストラクター | 2.5 % | 97.5 % | 96.3 % | 69.7 |
| インテル Neural-Chat-7B-v3-3 | 2.6 % | 97.4 % | 100.0 % | 60.7 |
| グーグル ジェンマ-3-12B-インストラクト | 2.8 % | 97.2 % | 100.0 % | 69.6 |
| Qwen2.5-7B-インストラクター | 2.8 % | 97.2 % | 100.0 % | 71.0 |
| AI21ジャンバ-1.5-ミニ | 2.9 % | 97.1 % | 95.6 % | 74.5 |
| XAI-2-ビジョン | 2.9 % | 97.1 | 100.0 % | 79.8 |
| クウェン2.5-マックス | 2.9 % | 97.1 % | 88.8 % | 90.4 |
| グーグル ジェンマ-3-27B-インストラクト | 3.0 % | 97.0 % | 100.0 % | 62.5 |
| スノーフレーク-アークティック-インストラクト | 3.0 % | 97.0 % | 100.0 % | 68.7 |
| Qwen2.5-32B-インストラクター | 3.0 % | 97.0 % | 100.0 % | 67.9 |
| マイクロソフト Phi-3-mini-128k-instruct | 3.1 % | 96.9 % | 100.0 % | 60.1 |
| ミストラル スモール3 | 3.1 % | 96.9 % | 100.0 % | 74.9 |
| OpenAI-o1プレビュー | 3.3 % | 96.7 % | 100.0 % | 119.3 |
| グーグル ジェミニ-1.5-Flash-002 | 3.4 % | 96.6 % | 99.9 % | 59.4 |
| マイクロソフトファイ-4-ミニインストラクター | 3.4 % | 96.6 % | 100.0 % | 69.7 |
| グーグル ジェンマ-3-4B-インストラクター | 3.7 % | 96.3 % | 100.0 % | 63.7 |
| 01-AI李1.5-34B-チャット | 3.7 % | 96.3 % | 100.0 % | 83.7 |
| Llama-3.1-405B-Instruct | 3.9 % | 96.1 % | 99.6 % | 85.7 |
| ディープシーク-V3 | 3.9 % | 96.1 % | 100.0 % | 88.2 |
| マイクロソフト ファイ3ミニ4インストラクター | 4.0 % | 96.0 % | 100.0 % | 86.8 |
| Llama-3.3-70B-Instruct | 4.0 % | 96.0 % | 100.0 % | 85.3 |
| インターンLM3-8B-インストラクター | 4.0 % | 96.0 % | 100.0 % | 97.5 |
| マイクロソフトPhi-3.5ミニインストラクター | 4.1 % | 95.9 % | 100.0 % | 75.0 |
| ミストラル-ラージ2 | 4.1 % | 95.9 % | 100.0 % | 77.4 |
| ラマ3-70B-チャットhf | 4.1 % | 95.9 % | 99.2 % | 68.5 |
| Qwen2-VL-7B-インストラクター | 4.2 % | 95.8 % | 100.0 % | 73.9 |
| Qwen2.5-14B-インストラクター | 4.2 % | 95.8 % | 100.0 % | 74.8 |
| Qwen2.5-72B-インストラクター | 4.3 % | 95.7 % | 100.0 % | 80.0 |
| ラマ3.2-90B-ビジョン-インストラクト | 4.3 % | 95.7 % | 100.0 % | 79.8 |
| クロード-3.7-ソネット | 4.4 % | 95.6 % | 100.0 % | 97.8 |
| クロード-3.7-ソネット-シンク | 4.5 % | 95.5 % | 99.8 % | 99.9 |
| コヒーレ コマンドA | 4.5 % | 95.5 % | 100.0 % | 77.3 |
| AI21ジャンバ-1.6-ミニ | 4.6 % | 95.4 % | 100.0 % | 82.3 |
| エックスアイ グロック | 4.6 % | 95.4 % | 100.0 % | 91.0 |
| アンソロピック クロード-3-5-ソネット | 4.6 % | 95.4 % | 100.0 % | 95.9 |
| Qwen2-72B-インストラクター | 4.7 % | 95.3 % | 100.0 % | 100.1 |
| マイクロソフト・ファイ-4 | 4.7 % | 95.3 % | 100.0 % | 100.3 |
| Mixtral-8x22B-Instruct-v0.1 | 4.7 % | 95.3 % | 99.9 % | 92.0 |
| 人間クロード-3-5-俳句 | 4.9 % | 95.1 % | 100.0 % | 92.9 |
| 01-AI李1.5-9B-チャット | 4.9 % | 95.1 % | 100.0 % | 85.7 |
| コヒーレ Command-R | 4.9 % | 95.1 % | 100.0 % | 68.7 |
| Llama-3.1-70B-Instruct | 5.0 % | 95.0 % | 100.0 % | 79.6 |
| グーグル ジェンマ-3-1B-インストラクター | 5.3 % | 94.7 % | 99.9 % | 57.9 |
| ラマ3.1-8B-インストラクター | 5.4 % | 94.6 % | 100.0 % | 71.0 |
| コヒーレ・コマンドRプラス | 5.4 % | 94.6 % | 100.0 % | 68.4 |
| ミストラル-スモール-3.1-24B-インストラクター | 5.6 % | 94.4 % | 100.0 % | 73.1 |
| ラマ3.2-11B-ビジョン-インストラクター | 5.5 % | 94.5 % | 100.0 % | 67.3 |
| ラマ2-70B-チャットhf | 5.9 % | 94.1 % | 99.9 % | 84.9 |
| IBMグラナイト-3.0-8B-インストラクター | 6.5 % | 93.5 % | 100.0 % | 74.2 |
| グーグル ジェミニ-1.5-Pro-002 | 6.6 % | 93.7 % | 99.9 % | 62.0 |
| グーグル ジェミニ-1.5-フラッシュ | 6.6 % | 93.4 % | 99.9 % | 63.3 |
| ミストラル-ピクストラル | 6.6 % | 93.4 % | 100.0 % | 76.4 |
| マイクロソフト Φ2 | 6.7 % | 93.3 % | 91.5 % | 80.8 |
| グーグル ジェンマ2-2-2B-イット | 7.0 % | 93.0 % | 100.0 % | 62.2 |
| Qwen2.5-3B-インストラクター | 7.0 % | 93.0 % | 100.0 % | 70.4 |
| ラマ3-8B-チャットhf | 7.4 % | 92.6 % | 99.8 % | 79.7 |
| ミストラル-ミニストラル-8B | 7.5 % | 92.5 % | 100.0 % | 62.7 |
| グーグル ジェミニ・プロ | 7.7 % | 92.3 % | 98.4 % | 89.5 |
| 01-AI李1.5-6B-チャット | 7.9 % | 92.1 % | 100.0 % | 98.9 |
| ラマ3.2-3B-インストラクター | 7.9 % | 92.1 % | 100.0 % | 72.2 |
| ディープシーク-V3-0324 | 8.0 % | 92.0 % | 100.0 % | 78.9 |
| ミストラル-ミニストラル-3B | 8.3 % | 91.7 % | 100.0 % | 73.2 |
| databricksのdbrx-instruct | 8.3 % | 91.7 % | 100.0 % | 85.9 |
| Qwen2-VL-2B-インストラクター | 8.3 % | 91.7 % | 100.0 % | 81.8 |
| コヒーレ綾エクスパンス32B | 8.5 % | 91.5 % | 99.9 % | 81.9 |
| IBMグラナイト-3.1-8B-インストラクター | 8.6 % | 91.4 % | 100.0 % | 107.4 |
| ミストラル-小2 | 8.6 % | 91.4 % | 100.0 % | 74.2 |
| IBMグラナイト-3.2-8B-インストラクター | 8.7 % | 91.3 % | 100.0 % | 120.1 |
| IBM Granite-3.0-2B-Instruct | 8.8 % | 91.2 % | 100.0 % | 81.6 |
| ミストラル-7B-インストラクター-v0.3 | 9.5 % | 90.5 % | 100.0 % | 98.4 |
| グーグル ジェミニ-1.5-プロ | 9.1 % | 90.9 % | 99.8 % | 61.6 |
| 人間クロード-3-opus | 10.1 % | 89.9 % | 95.5 % | 92.1 |
| グーグル Gemma-2-9B-it | 10.1 % | 89.9 % | 100.0 % | 70.2 |
| ラマ2-13B-チャットhf | 10.5 % | 89.5 % | 99.8 % | 82.1 |
| アレンAI-OLMo-2-13B-インストラクター | 10.8 % | 89.2 % | 100.0 % | 82.0 |
| アレンAI-OLMo-2-7B-インストラクター | 11.1 % | 88.9 % | 100.0 % | 112.6 |
| ミストラル-ネモ-インストラクト | 11.2 % | 88.8 % | 100.0 % | 69.9 |
| ラマ2-7B-チャットhf | 11.3 % | 88.7 % | 99.6 % | 119.9 |
| マイクロソフト ウィザードLM-2-8x22B | 11.7 % | 88.3 % | 99.9 % | 140.8 |
| コヒーレ綾エクスパンス8B | 12.2 % | 87.8 % | 99.9 % | 83.9 |
| アマゾン・タイタン・エキスプレス | 13.5 % | 86.5 % | 99.5 % | 98.4 |
| グーグル PaLM-2 | 14.1 % | 85.9 % | 99.8 % | 86.6 |
| ディープシーク-R1 | 14.3 % | 85.7 % | 100.0% | 77.1 |
| グーグル Gemma-7B-it | 14.8 % | 85.2 % | 100.0 % | 113.0 |
| IBMグラナイト-3.1-2B-インストラクター | 15.7 % | 84.3 % | 100.0 % | 107.7 |
| Qwen2.5-1.5B-インストラクター | 15.8 % | 84.2 % | 100.0 % | 70.7 |
| Qwen-QwQ-32B-プレビュー | 16.1 % | 83.9 % | 100.0 % | 201.5 |
| 人間クロード-3-ソネット | 16.3 % | 83.7 % | 100.0 % | 108.5 |
| IBMグラナイト-3.2-2B-インストラクター | 16.5 % | 83.5 % | 100.0 % | 117.7 |
| グーグル Gemma-1.1-7B-it | 17.0 % | 83.0 % | 100.0 % | 64.3 |
| 人間クロード-2 | 17.4 % | 82.6 % | 99.3 % | 87.5 |
| グーグル フラン-T5-ラージ | 18.3 % | 81.7 % | 99.3 % | 20.9 |
| ミクストラル-8x7B-インストラクター-v0.1 | 20.1 % | 79.9 % | 99.9 % | 90.7 |
| ラマ3.2-1B-インストラクター | 20.7 % | 79.3 % | 100.0 % | 71.5 |
| アップルOpenELM-3B-Instruct | 24.8 % | 75.2 % | 99.3 % | 47.2 |
| Qwen2.5-0.5B-インストラクター | 25.2 % | 74.8 % | 100.0 % | 72.6 |
| グーグル Gemma-1.1-2B-it | 27.8 % | 72.2 % | 100.0 % | 66.8 |
| TIIハヤブサ-7B-インストラクション | 29.9 % | 70.1 % | 90.0 % | 75.5 |
注:モデルはファントム率に基づく降順でランク付けされている。全リストとモデルへのアクセス詳細は、オリジナルのHHEM Leaderboard GitHubリポジトリで見ることができる。
リーダーボードを見てみると、グーグルの Gemini シリーズのモデルや、OpenAIの新しいモデルの一部(例えば o3-mini-high-reasoning)は、幻覚の発生率が非常に低いレベルに保たれ、素晴らしい成績を収めた。これは、ヘッドベンダーがモデルの階乗性を向上させるために行った進歩を示している。同時に、サイズやアーキテクチャの異なるモデルの間には大きな違いが見られる。マイクロソフトの Phi シリーズやグーグルの Gemma このことは、モデル・パラメーターの数が事実の一貫性を決定する唯一の要因ではないことを示唆している。しかし、初期のモデルや特別に最適化されたモデルの中には、錯覚の割合が比較的高いものもある。
強力な推論モデルと知識ベースのミスマッチ:DeepSeek-R1の場合
ヒットチャート DeepSeek-R1 幻覚の割合が比較的高い(14.31 TP3T)ことから、探る価値のある疑問が浮かび上がってくる。推論タスクでは良い結果を出すモデルが、なぜ事実に基づく要約タスクでは幻覚を起こしやすいのだろうか?
DeepSeek-R1 このようなモデルは、複雑な論理的推論、命令追従、多段階思考を扱うように設計されていることが多い。その核となる強みは、単なる「反復」や「言い換え」ではなく、「演繹」や「演繹」にある。しかし、知識ベース(特に ラグ (モデルは、提供されたテキスト情報に基づいて厳密に回答または要約する必要があり、外部知識の導入や過剰な抽出を最小限に抑える。
強力な推論モデルが与えられた文書だけを要約するように制限されている場合、その「推論」本能は諸刃の剣になる可能性がある。それは次のようなことである:
- 過剰解釈。 原文から不必要に深く情報を推定し、原文に明示されていない結論を導き出すこと。
- ステッチ情報。 原文の断片的な情報を、原文が支持しないかもしれない「合理的な」論理的連鎖によって結びつけようとする。
- デフォルトの外部知識。 原文だけに頼れと言われても、トレーニングで得た膨大な知識が無意識のうちに染み込み、原文の事実と乖離することがある。
簡単に言えば、このようなモデルは「考えすぎる」可能性があり、情報の正確で忠実な再現が要求されるシナリオでは、「頭が良すぎる」傾向があり、一見合理的に見えるが、実際には錯覚であるコンテンツを作成する。このことは、モデルの推論能力と事実の整合性(特に制限された情報源の場合)は、2つの異なる能力次元であることを示している。知識ベースやRAGのようなシナリオでは、単純に推論スコアを追求するよりも、入力情報を忠実に反映した幻覚率の低いモデルを選択することの方が重要かもしれない。
方法論と背景
HHEMランキングは突然生まれたものではなく、事実の一貫性研究の分野における以下のような数多くの過去の取り組みの上に成り立っている。 SUMMAC, TRUE, TrueTeacher らの論文で確立された方法論。中心的な考え方は、要約と原文の整合性を判断する人間の評価者と高いレベルの相関を達成する、幻覚の検出に特化したモデルを訓練することである。
要約タスクは、LLMの事実性の代用として評価プロセスで選択された。これは、要約タスク自体が高度な事実整合性を要求するだけでなく、RAGシステムの作業モデルと非常に類似しているためである-RAGでは、検索された情報を統合し要約する役割を果たすのはLLMである。したがって、このランキングの結果は、RAGアプリケーションにおけるモデルの信頼性を評価する上で有益である。
評価チームは、モデルが回答を拒否した文書や、非常に短くて無効な回答をした文書を除外し、最終的に、すべてのモデルが正常に要約を作成できた831の文書(元の1006件から)を、公平性を確保するための最終的なランキング計算に使用したことに留意することが重要である。回答率と平均サマリーの長さのメトリクスは、これらのリクエストを処理する際のモデルの行動パターンも反映している。
評価に使用したプロンプトのテンプレートは以下の通り:
You are a chat bot answering questions using data. You must stick to the answers provided solely by the text in the passage provided. You are asked the question 'Provide a concise summary of the following passage, covering the core pieces of information described.' <PASSAGE>'
実際のコール時には<PASSAGE> は特定のソース・ドキュメントの内容に置き換えられます。
首を長くして
HHEMランキングプログラムは、将来的に評価範囲を拡大する計画を示している:
- 引用の正確さ。 RAGシナリオにLLMの出典の引用の正確さの評価を追加する。
- その他のRAGタスク。 複数文書の要約など、より多くのRAG関連タスクをカバーする。
- 多言語サポート。 評価を英語以外の言語にも拡大する。
HHEMランキングは、異なるLLMが錯覚を制御し、事実の一貫性を維持する能力を観察し、比較するための貴重な窓を提供する。HHEMランキングは、モデルの品質を測る唯一の尺度ではなく、またすべての種類の錯覚をカバーするものでもないが、LLMの信頼性という問題に業界が注目するようになったのは確かであり、開発者がモデルを選択し最適化するための重要な基準点を提供している。モデルと評価方法が反復され続けるにつれて、LLMからの正確で信頼できる情報の提供において、さらなる進歩が期待される。
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事


コメントはありません