



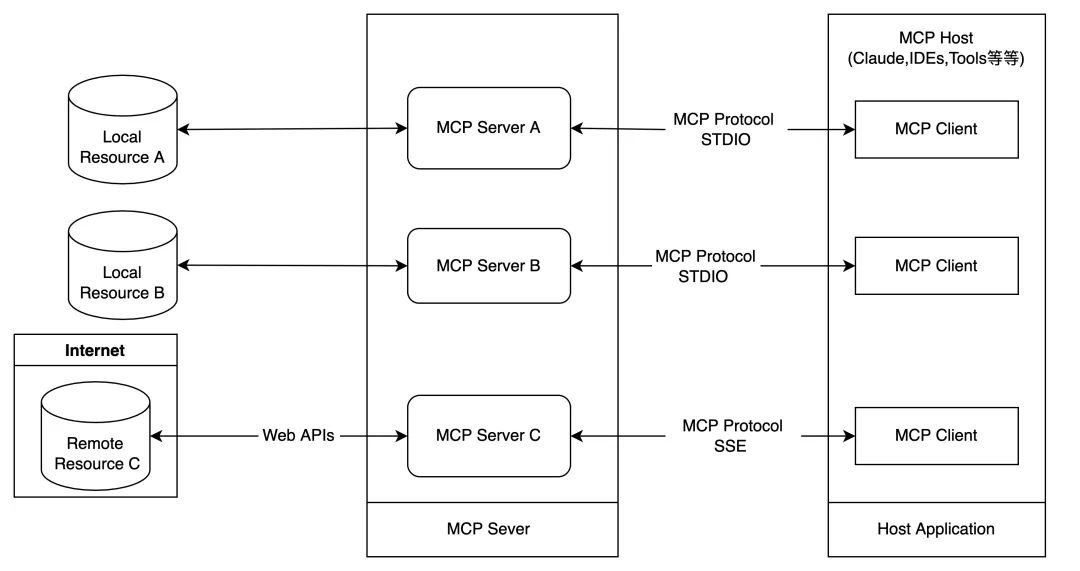
混乱を解決する o1、DeepSeek-R1のような推論モデルは考えているのか、考えていないのか?

で楽しい論文を見つけた。思考はあちこちに:O1ライクなLLMの過小評価について"と呼ばれる、思考経路の頻繁な切り替えと思考における焦点の欠如を分析することである。「アンダーシンキング」。また、その緩和方法も示されている。この記事は同時に、推論モデルは再び考えるのか、そうでないのかという疑問にも答えており、読者が自分なりの答えを見つけてくれることを願っている。
I. 背景
近年、OpenAIのo1モデルに代表される大規模言語モデル(LLM)は、推論プロセスに関わる計算量をスケールアップすることで、人間の思考の深さを模倣する複雑な推論タスクにおいて優れた能力を発揮している。しかし、既存の研究では、LLMの思考の深さについては疑問視されている:これらのモデルは本当に深く考えているのだろうか?
この疑問に答えるために、本稿の著者たちは次のように提案する。"アンダーシンキング"を体系的に分析している。著者は不十分な思考は、複雑な問題を解決するLLMのO1クラスである。有望な推論経路を早期に放棄することは、十分な思考の深化を招き、最終的にモデルの性能に影響を与える。.この現象は特に数学パズルで顕著だ。
反省と研究の方法
アンダーシンキングという現象をより深く掘り下げるために、著者らは次のような調査を行った:
1.定義と観察不足・思考不足の現象
- 思考の定義 著者らは、「思考」をモデルの推論過程における認知的な中間段階と定義し、思考の切り替えのサインとして「alternatively(代替的に)」などの用語を用いている。
- 例 図2では、25の思考ステップを含むモデルの出力例を示し、考えすぎの出力と比較している。
- 実験デザイン:
- テストセット: 著者らは3つのチャレンジングなテストセットを選んだ:
- MATH500. 難易度1から5までの高校数学コンテストの問題を収録。
- GPQAダイヤモンド 物理学、化学、生物学の大学院レベルの多肢選択問題を収録。
- AIME2024 米国招待数学コンクールのトピックは、代数、計数、幾何、整数論、確率など幅広い分野をカバーしている。
- モデル選択: 著者らは、長い思考鎖が目に見えるo1クラスの2つのオープンソースモデル、QwQ-32B-PreviewとDeepSeek-R1-671Bを選び、DeepSeek-R1-Previewを補完モデルとして用いて、R1ファミリーのモデルの発展を示した。
- テストセット: 著者らは3つのチャレンジングなテストセットを選んだ:
2.不十分な反省の表れの分析
- 切り替え頻度と問題の難易度を考える
- 著者らは、問題の難易度が上がるにつれて、生成される推論反射の数と生成されるトークンの数がすべてのモデルで増加することを発見した(図3参照)。
- このことは、クラスo1のLLMは、より複雑な問題に対処するために推論プロセスを動的に適応させる能力があることを示唆している。

- スイッチングとエラー対応を考える
- すべてのテストセットにおいて、クラスo1のLLMは不正解を生成する際に、より頻繁に思考の切り替えを示した(図1と4参照)。
- このことは、このモデルが問題解決のために認知プロセスを動的に適応させることを目的としているにもかかわらず、思考の切り替えの頻度が高ければ高いほど精度が高くなるとは限らないことを示唆している。
3.思考力不足の本質を深く探る
- 思考の正しさを評価する
- 著者らは、ラマとクウェンに基づく2つのモデル(DeepSeek-R1-Distill-Llama-70BとDeepSeek-R1-Distill-Qwen-32B)を使用して、各思考ステップが正しいかどうかを評価した。
- 結果は以下の通りである。誤答における初期の思考ステップのかなりの部分は正しいが、十分に検討されていない。(図5参照)。
- このことは、このモデルが複雑な問題に直面したときに、その問題を解決できることを示唆している。有望な推論を早々に放棄する傾向があり、思考に深みがない。.
- 正誤分布について考えてみよう:
- 著者らは、701以上のTP3Tエラー回答が、少なくとも1つの正しい思考ステップを含んでいることを発見した(図6参照)。
- これは上記の見解をさらに裏付けるものである:o クラス1のモデルは、推論の正しい経路を開始することはできるが、その経路を正しい結論まで続けることは難しいかもしれない。.
4.反省の欠如を数値化する:評価のための新たな指標を提案する
- アンダー・インディケータ(UT)について考える:
- この指標は、エラー応答を生成する際のトークンの効率を測定することで、アンダーシンキングの度合いを定量化する。
- 具体的には、UT メトリックは、(1) のエラー応答を計算する。トークンの総数に占める、先頭から順に正しく考えられたトークンの数.
- UTの値が高いほど、過小思考のレベルが高いことを示す。つまり、エラーに反応してモデルによって生成されたトークンのうち、正しい思考の生成に効果的に貢献できない割合が多くなる。
5.アンダーシンキングがモデルのパフォーマンスに与える影響:
- 著者らは次のことを発見した。アンダーシンキングという現象は、データセットやタスクによって異なる。::
- MATH500-HardデータセットとGPQA Diamondデータセットでは、DeepSeek-R1-671Bモデルは、より正確である一方で、UT値も高く、エラー応答においてよりアンダーシンキングであることが示唆された。
- AIME2024テストセットでは、DeepSeek-R1-671Bモデルは精度が高いだけでなく、UT値も低く、より集中的で効率的な推論プロセスを示しています。
III.重要な結論
- 複雑な問題に対するo1カテゴリーのLLMの成績不振の重要な要因は、不十分な思考である。 頻繁に思考が切り替わると、モデルは有望な推論経路を深く探索できなくなり、結果的に精度に影響する。
- アンダーシンキングという現象は、問題の難易度やモデリング能力に関係している。 より困難な問題はアンダーシンキングを悪化させ、より強力なモデルが必ずしもアンダーシンキングを減らすとは限らない。
- アンダーシンキングとオーバーシンキングは違う。 考えすぎとは、モデルが単純な問題で計算資源を浪費することであり、考えが足りないとは、モデルが複雑な問題で有望な推論経路を早々に放棄することである。
- アンダーシンキング指標(UT)は、アンダーシンキングの程度を効果的に数値化することができる。 この指標は、クラスo1のLLMの推論効率を評価する新しい視点を提供する。
IV.対応策
不十分な思考の問題を軽減するために、著者らは次のような方法を提案している。シンク・スイッチング・ペナルティ(TIP)を用いた解読戦略::
- 核となる考え方 デコード処理中、シンクスイッチに関連するトークンにはペナルティが適用される。新しい考え方に切り替える前に、現在の考え方をより深く探求するようモデルを奨励する。.
- 結果 TIP戦略は、すべてのテストセットにおいてQwQ-32B-Previewモデルの精度を向上させ、アンダーシンキング問題の軽減に有効であることを実証した。
V. 将来の展望
著者らは、今後の研究の方向性として次のようなことを提案している:
- 思考スイッチの自己制御を可能にする適応メカニズムの開発。
- クラスo1のLLMの推論効率をさらに向上させる。
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事

コメントはありません