
イリヤ・スーツケバーがNeurIPSで憤慨し、こう宣言した。

推論とは予測不可能なものであるため、私たちは信じられないような予測不可能なAIシステムから始めなければならない。
イリヤがついに姿を現し、さっそく驚くべきことを言い出した。金曜日、OpenAIの元チーフ・サイエンティストであるイリヤ・スーツケバーは、グローバルAIサミットで、"我々は得られるデータの限界に達しており、これ以上はないだろう "と述べた。 
OpenAIの共同設立者で元チーフ・サイエンティストのイリヤ・スーツケバーは、今年5月に同社を退社し、自身のAIラボ「Safe Superintelligence」を立ち上げたことで話題となった。彼はOpenAIを去って以来、メディアから遠ざかっていたが、今週金曜日にバンクーバーで開催されたニューラル情報処理システムに関するカンファレンス「NeurIPS 2024」で、珍しく公の場に姿を見せた。
「私たちが知っているようなプレトレーニングは、間違いなく終わりを迎えるでしょう」とスッツケバーは壇上から言った。
人工知能の分野では、近年、BERTやGPTといった大規模な事前学習モデルが大きな成功を収め、技術進歩の一里塚となっている。
複雑な事前学習の目的と膨大なモデルパラメータにより、大規模な事前学習は大量のラベル付き・ラベルなしデータから効率的に知識を取り込むことができる。知識を巨大なパラメータに格納し、特定のタスクに合わせて微調整することで、巨大なパラメータに暗黙的にエンコードされた豊富な知識は、下流の様々なタスクに恩恵をもたらすことができる。AIコミュニティでは現在、ゼロからモデルを学習するのではなく、下流タスクのバックボーンとして事前学習を採用することがコンセンサスとなっている。 
しかし、イリヤ・サッツケバー氏はNeurIPSの講演の中で、既存のデータはまだAIを推進することができるが、業界は使えると呼べる新しいデータを使い果たそうとしていると述べた。彼は、この傾向は、最終的に業界が現在のモデルの学習方法を変更せざるを得なくなると指摘した。
石油が有限の資源であるように、インターネット上の人間が生成したコンテンツも有限なのだ。
「データはピークに達し、もうこれ以上データは出てこない。「インターネットは1つしかないのだから、今あるデータを活用しなければならない。
Sutskever氏は、次世代のモデルは「本当の意味で自律性を示す」ようになると予測している。一方、エージェントはAIの流行語になっている。
自律的』であることに加えて、彼は未来のシステムが推論する能力を持つことにも言及した。パターンマッチング(モデルが過去に見たものに基づく)に大きく依存する現在のAIとは異なり、未来のAIシステムは『思考』に似た方法で問題を段階的に解決できるようになるだろう。
システムが推論すればするほど、その振る舞いは『予測不可能』になるとサツキーバーは言う。彼は、『真の推論力を持つシステム』の予測不可能性を、チェスにおける高度なAIのパフォーマンスに例えている。
これらのシステムは、限られたデータから物事を理解し、混乱することはないだろう。
講演の中で彼は、AIシステムにおけるスケーリングを進化生物学と比較し、異なる種間の脳と体重の比率の関係を引き合いに出した。彼は、ほとんどの哺乳類が特定のパターンのScalingに従っているのに対し、ヒト科(ヒトの祖先)は対数スケールで脳対体重比の成長という非常に異なる傾向を示していると指摘した。
進化が人間の科学的頭脳に新たなスケーリング・パラダイムを見出したように、AIも既存の事前学習法を超えて、まったく新しいスケーリング・パスを発見する可能性がある、とサツキーヴァーは提案する。以下は、イリヤ・サツキーヴァーの講演の全文である: 
この賞に論文を選んでくれた学会主催者に感謝したい(Ilya SutskeverらのSeq2Seq論文はNeurIPS 2024 Time Check Awardに選ばれた)。素晴らしいことだ。目の前にいる素晴らしい共著者のOriol VinyalsとQuoc V. Leにも感謝したい。 

10年前、モントリオールで開催されたNIPS 2014で同じような講演があった。もっと無邪気な時代だった。ここに私たちが写っています。ちなみに、これは前回で、下の写真は今回です。
今、私たちはより多くの経験を積んでいるし、少しは賢くなっているはずだ。というのも、この練習で行われた多くのことは正しかったが、中にはまったく正しくなかったものもあったからだ。私たちはそれらを振り返り、何が起こったのか、そしてそれがどのように今日の私たちを導いたのかを確認することができる。 では、私たちがやったことについて話を始めよう。まず最初に、10年前の同じプレゼンテーションのスライドをお見せします。要点は3つにまとめられている。テキストで訓練された自己回帰モデル、大規模なニューラルネットワーク、大規模なデータセット、以上です。
では、私たちがやったことについて話を始めよう。まず最初に、10年前の同じプレゼンテーションのスライドをお見せします。要点は3つにまとめられている。テキストで訓練された自己回帰モデル、大規模なニューラルネットワーク、大規模なデータセット、以上です。
では、もう少し詳しく見ていこう。 
これは10年前のスライドですが、『ディープラーニングの仮説』というのが良さそうです。ここで言っているのは、10層からなる大規模なニューラルネットワークがあったとして、人間ができることなら何でも一瞬でできるということだ。 なぜ「人間が一瞬でできること」を強調するのか?なぜこんなことを?
なぜ「人間が一瞬でできること」を強調するのか?なぜこんなことを?
人工ニューロンは生物学的ニューロンと似ている、あるいは少なくともそれほど違わないというディープラーニングの教義を信じ、3つの本物のニューロンは遅いと信じるなら、人間は何でも素早く処理できることになる。世界に人間が1人しかいない場合の話だ。もし世界で一人の人間が何かを一瞬で処理できるのなら、10層のニューラルネットワークでもできるはずでしょう?
次に、その接続を人工ニューラルネットワークに埋め込むだけだ。
すべてはモチベーションの問題だ。人間が一瞬でできることは、10層のニューラルネットワークでもできる。
私たちが10層のニューラルネットワークに注目したのは、それが当時私たちが知っていたトレーニング方法だったからで、もしどうにかしてその層数を超えることができれば、もっと多くのことができるようになる。しかし、当時は10層しかできなかった。だからこそ、人間がほんの数秒でできることを重視したのだ。
その年のもう1枚のスライドは、2つのこと、あるいは少なくとも1つのことを特定できるかもしれない、という我々の主な考えを示している。 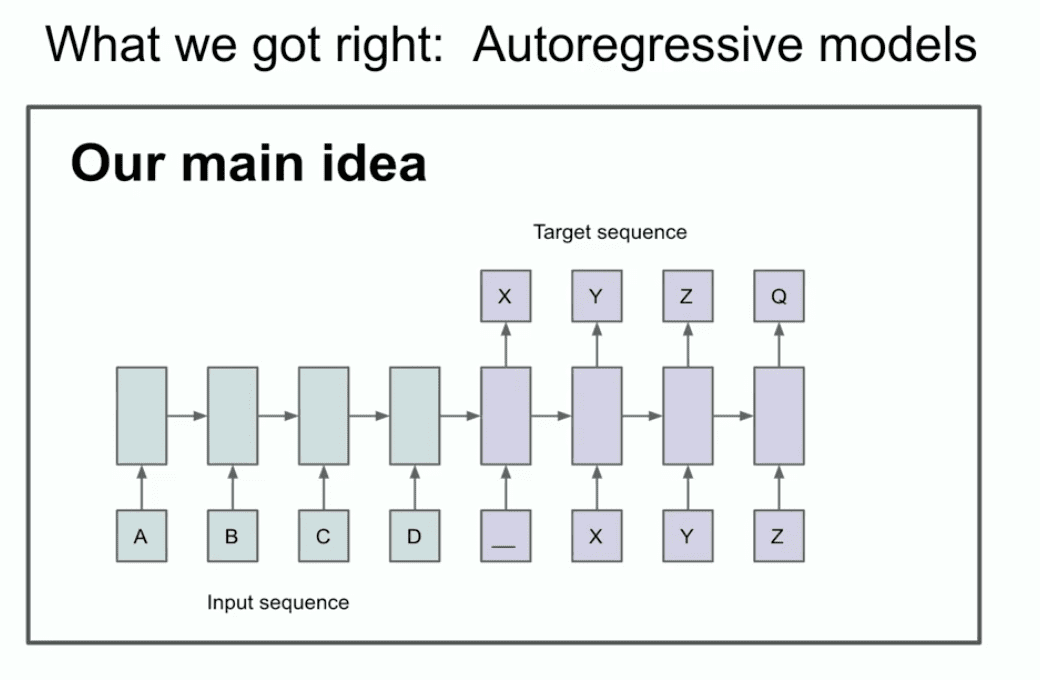
一体何を言っているのか?このスライドは実際には何を言っているのか?このスライドによると、自己回帰モデルがあり、それが次のモデルを予測する場合、そのモデルは次のモデルを予測します。 トークン そうすれば、次にどのようなシークエンスが現れようとも、実際に正しい配分をつかみ、捕捉し、保持することができる。
これは比較的新しいもので、最初の自己回帰ネットワークではないが、最初の自己回帰ニューラルネットワークだと思う。うまく訓練すれば、望むものは何でも得られると、私たちは本当に信じていました。私たちの場合は、今では保守的に思える機械翻訳タスクでしたが、当時はとても大胆に思えました。今から、おそらく多くの人が見たこともないような古い歴史をお見せしましょう。それはLSTMと呼ばれるものです。
馴染みのない方のために説明しておくと、LSTMは、ディープラーニングの研究者の中で最も貧弱なものである。 変圧器 以前はどうだったのか。
基本的にはResNetだが、90度回転してLSTMになっている。LSTMは少し複雑なResNetのようなものです。積分器が見えますが、これは現在残差ストリームと呼ばれています。少し複雑ですが、これが私たちがやっていることです。これはResNetを90度回転させたものです。 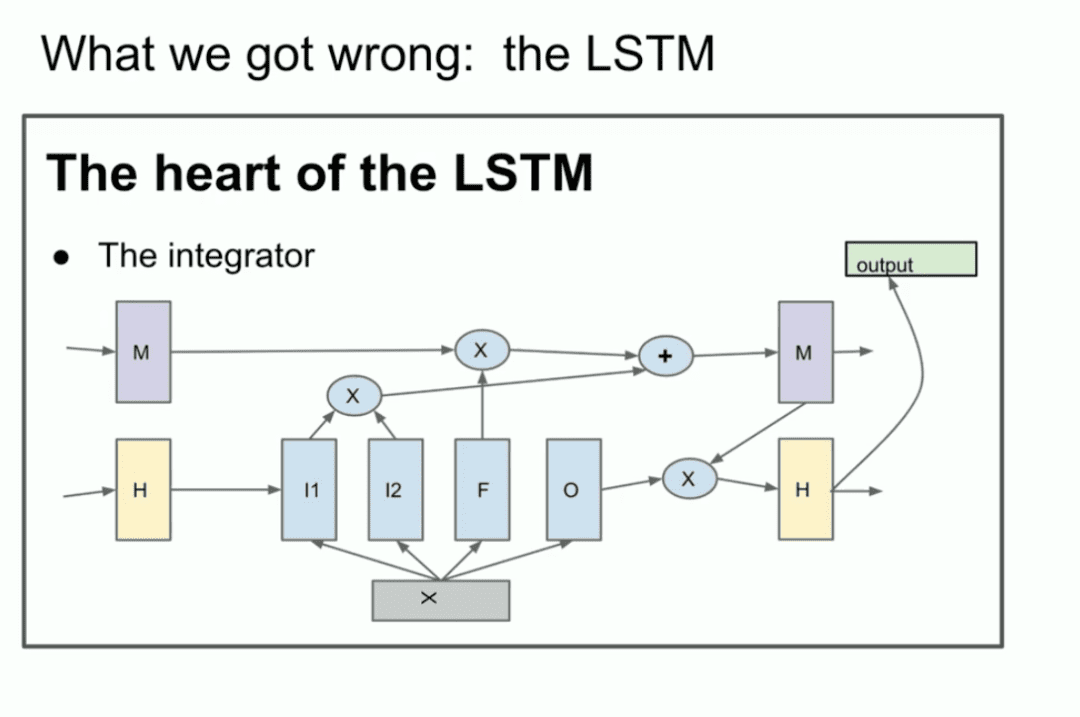
あの古い講演で私が強調したかったもうひとつの重要なポイントは、並列化を使ったが、単なる並列化ではないということだ。
私たちはパイプラインを使い、ニューラルネットワークのレイヤーごとにGPUを1つ割り当てました。今となっては賢い戦略ではないことはわかっていますが、当時の私たちはあまり賢くありませんでした。しかし、当時はまだあまり賢明ではありませんでした。パイプラインを使用したところ、8GPUで3.5倍速くなりました。 
最後の結論、これが最も重要なスライドだ。スケーリング法則の始まりかもしれないことを照らしている。非常に大きなデータセットがあり、非常に大きなニューラルネットワークを訓練すれば、成功は保証されている。気前よく言えば、本当にそうなっているのだ、と主張することもできる。 
ここで、私が時の試練に耐えてきたと思うもうひとつのアイデアについて触れたい。それは、ディープラーニングの核となる考え方そのものだ。それはコネクショニズムという考え方だ。この考え方は、人工ニューロンは生物学的ニューロンに似ているというものだ。一方が他方に少し似ていると信じるなら、ハイパースケールニューラルネットワークを信じる自信が生まれる。人間の脳と同じ規模である必要はなく、もう少し小さいかもしれないが、人間が行うほとんどすべてのことができるように構成することができる。
というのも、人間の脳は自分自身をどのように再構成するかを考え、我々が持っている最高の学習アルゴリズムを使っているからだ。人間はその点でははるかに優れている。 これらはすべて、私がトレーニング前と呼ぶべき時代に向けたものだ。
これらはすべて、私がトレーニング前と呼ぶべき時代に向けたものだ。
そして、GPT-2モデル、GPT-3モデル、スケーリング法則と呼ばれるものがあります。私は、私のかつての共同研究者であるアレック・ラドフォード、そしてジャレッド・カプランとダリオ・アモデイのことを特別に紹介したいと思います。 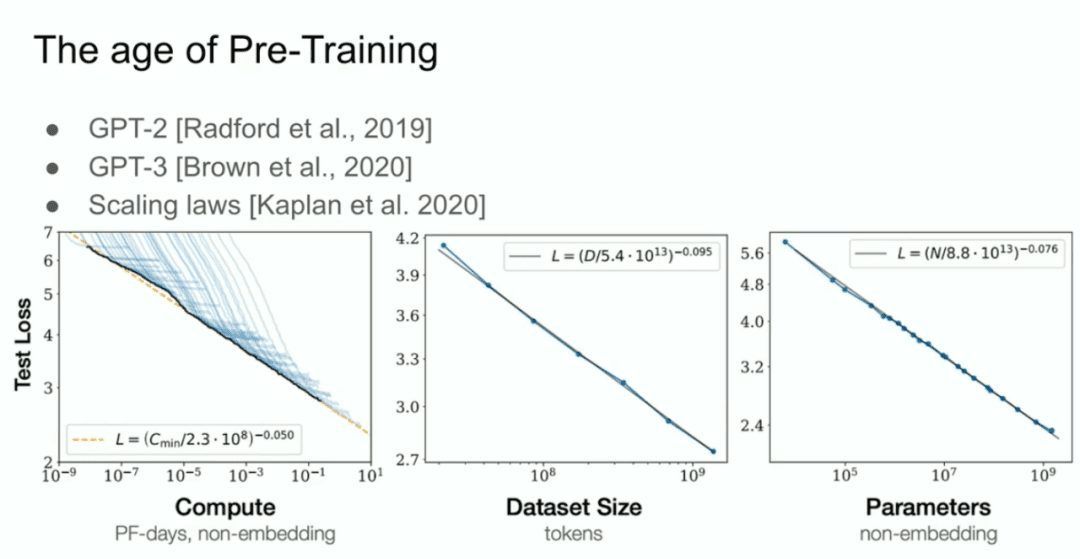 それが事前トレーニングの時代であり、それが今日我々が目にしているすべての進歩、メガ・ニューラル・ネットワーク、巨大なデータセットで訓練されたメガ・ニューラル・ネットワークを牽引している。
それが事前トレーニングの時代であり、それが今日我々が目にしているすべての進歩、メガ・ニューラル・ネットワーク、巨大なデータセットで訓練されたメガ・ニューラル・ネットワークを牽引している。
しかし、私たちが知っているようなプレトレーニング・ルートは間違いなく終わるだろう。なぜ終わるのか?なぜなら、コンピューターはより優れたハードウェア、より優れたアルゴリズム、ロジックのクラスターによって成長し続け、これらすべてがコンピューティングパワーを増やし続ける。 
データはAIの化石燃料だとさえ言える。ある特定の方法で作成され、それを使っている今、私たちはデータを最大限に活用し、これ以上良くなることはないのです。今あるデータで何をしなければならないかを考える。私はまだそれに取り組むつもりだし、それでまだかなり遠くまで行けるが、問題はインターネットが1つしかないということだ。
そこで、この先どうなるのか、あえて推測してみたい。実際、私が推測するまでもなく、他の多くの人たちも同じように推測しているので、彼らの推測にも触れておこう。
- インテリジェント・ボディ・エージェント』という言葉を聞いたことがあるかもしれない。
- より具体的に言えば、しかしやや漠然ともしているが、合成データである。しかし、合成データとは何を意味するのか?それを解明することは大きな挑戦であり、さまざまな人々がそこでさまざまな興味深い進歩を遂げていることは間違いない。
- 推論時間の計算もあるし、もっと最近だと(OpenAIの)o1というモデルも、事前学習後に人々が何をすべきかを考えようとしている様子を最も鮮明に示している。
これらはすべて非常に良いことだ。 
生物学から、私が本当にクールだと思うもう一つの例を挙げたい。何年も前のことだが、哺乳類における体の大きさと脳の大きさの関係を示すグラフを示した発表があった。この場合、脳は巨大だった。生物学ではすべてが混乱するものだが、ここでは動物の体の大きさと脳の大きさの間に非常に強い関係があるという珍しい例がある。
セレンディピティで、この写真に興味を持った。  そこでグーグルで画像検索した。
そこでグーグルで画像検索した。
この写真では、さまざまな哺乳類が列挙されており、霊長類以外のものもいるが、ほぼ同じで、原始人もいる。私が知る限り、原始人はネアンデルタール人のように、進化の過程で人間に近い親戚だった。例えば、「元気な人間」。興味深いことに、彼らは脳と体の比率指数の傾きが異なる。非常に興味深い。
つまり、生物学が何らかの別の尺度を見つけ出す可能性があるということだ。明らかに何かが違う。ところで、このX軸は対数スケールであることを強調しておきたい。これは100、1,000、10,000、100,000、またグラム単位で、1グラム、10グラム、100グラム、1キログラムです。つまり、物事が異なる可能性があるということです。
私たちがしていること、スケーリングに関してこれまでしてきたことは、実際、どのようにスケーリングするかが最優先事項であることが分かってきた。このスペースで働く誰もが、何をすべきかを見つけ出すことは間違いない。しかし、私はここでそれについて話したい。私たち全員が直面することですが、長期的な見通しを立てるために数分時間を取りたいと思います。  私たちが成し遂げているすべての進歩は、驚くべき進歩だ。つまり、10年前にこの分野で働いていた人たちは、何もかもが無力だったことを覚えているだろう。ここ2年でディープラーニングの分野に加わった人は、おそらく共感できないだろう。
私たちが成し遂げているすべての進歩は、驚くべき進歩だ。つまり、10年前にこの分野で働いていた人たちは、何もかもが無力だったことを覚えているだろう。ここ2年でディープラーニングの分野に加わった人は、おそらく共感できないだろう。
スーパーインテリジェンス』について少しお話ししたいと思います。
言語モデルは今、信じられないような能力を持っている一方で、少し信頼性に欠ける面もある。しかし、いずれは、遅かれ早かれ、ゴールは実現されるだろう。今のところ、これらのシステムは強力な意味を持つ知覚的知性ではなく、実際、推論を始めたばかりである。ところで、システムが推論すればするほど、より予測不可能になる。
私たちはすべてのディープラーニングが非常に予測可能であることに慣れている。というのも、人間の直感を再現することに取り組んできたとしたら、0.1秒の反応時間まで遡ることになる。それが直感であり、我々はAISにその直感の一部を与えた。
しかし、推論というのは予測不可能なものであるという兆候を、早い段階でいくつか目にすることができる。例えばチェスは、人間の最高のプレーヤーにとっても予測不可能だ。だから我々は、非常に予測不可能なAIシステムに対処しなければならないだろう。彼らは限られたデータから物事を理解し、混乱することはないだろう。
これらすべてが非常に限定的だ。ところで、私は「自己認識」によって、これらのことがいつ、どのように起こるのか、そしていつ起こるのかについては言わなかった。なぜ「自己認識」が役に立ってはいけないのだろうか?私たち自身が、私たち自身の世界のモデルの一部なのだ。
これらすべてが組み合わさったとき、私たちは現在存在するものとはまったく異なる品質と属性を持つシステムを手にすることになるだろう。もちろん、信じられないような素晴らしい能力を持つことになるだろう。しかし、このようなシステムの問題点は、非常に異なるものになるのではないかということだ。
未来予測も確かに不可能だと言える。本当に、いろんなことが可能なんだ。皆さん、ありがとうございました。
Neurlpsカンファレンスでの拍手の後、イリヤは数人の質問者からの短い質問に答えた。
Q:2024年、ヒトの認知に関連する生物学的構造で、同様の方法で探求する価値があるものは他にもあると思いますか?
イリヤもし、あなたや誰かが「脳が何かをやっていることを明らかに無視している。個人的には、そのような見識はない。もちろん、研究対象の抽象度にもよる。 多くの人が、生物学的な着想を得たAIの開発を志している。ある意味、生物学的な着想を得たAIは大成功を収めていると言えるかもしれない。何しろ、ディープラーニングの基礎はすべて生物学的な着想を得たAIなのだから。しかし一方で、その生物学的な着想は実際には非常に限定的なものだ。基本的には「ニューロンを使いましょう」というだけのもので、それがバイオインスパイアードのすべてなのだ。より詳細で深いレベルのバイオインスパイアを実現するのは難しいですが、私はそれを否定しません。特別な洞察力を持った人が、何か新しい切り口を発見できれば、それはとても価値のあることだと思います。 Q:オートコレクトについて質問したい。
推論が今後のモデル開発の中心的な方向性のひとつであり、差別化できる特徴になるかもしれないとおっしゃっていましたね。ポスター発表のいくつかのセッションで、現在のモデルには「幻覚」があることがわかりました。モデルが幻覚を見ているかどうかを分析する私たちの現在の方法は(この分野の専門家であるあなたが誤解していたら訂正してください)、主に統計分析に基づいています。将来、モデルに推論能力が備われば、オートコレクトのように自己修正できるようになり、将来のモデルの中核機能になると思いますか?そうすれば、モデルは幻覚的な内容を自分で生成している状況を認識できるようになるので、幻覚をあまり見なくなるでしょう。これはもっと複雑な質問かもしれませんが、将来のモデルは推論によって幻覚の発生を理解し、検出できるようになると思いますか?
イリヤ答え:はい。
私は、あなたのおっしゃるような状況は非常にあり得ると思います。確信があるわけではありませんが、調べてみることをお勧めしますし、このようなシナリオは初期の推論モデルではすでに起こっていたかもしれません。しかし、長い目で見れば、なぜそれができないのでしょうか?
Q:つまり、マイクロソフト・ワードのオートコレクト機能のようなものです。
イリヤオートコレクト」と呼ぶのは少し控えめな表現だと思う。オートコレクト」というと、比較的シンプルな機能を思い浮かべますが、そのコンセプトはオートコレクトをはるかに超えています。しかし、全体的な答えは「イエス」だ。
質問者:ありがとうございました。 次に2人目の質問者です。
Q:イリヤさん、こんにちは。謎のホワイトアウトのエンディングがとても良かったです。AIは私たちに取って代わるのでしょうか、それとも私たちより優れているのでしょうか?彼らに権利は必要なのでしょうか?それはまったく新しい種です。ホモ・サピエンス(ホモ・サピエンス)がこの知性を生み出したわけですが、強化学習の人たちは、私たちがこれらの存在に権利が必要だと考えているのかもしれませんね。
関係ない質問だが、私たちホモ・サピエンスが享受しているのと同じ自由を人間も享受できるようにするには、どうすれば人間にとって適切なインセンティブを生み出すことができるだろうか?
イリヤこれはある意味、人々がもっと考え、反省すべき問題だと思う。しかし、どのようなインセンティブを作るべきかという質問に対しては、自信を持って答えられないと思う。ある種のトップダウンの構造やガバナンスモデルを作ろうという話のように聞こえるが、それについてはあまり自信がない。
次は最後の質問者だ。
Q:イリヤさん、素晴らしいプレゼンテーションをありがとうございました。トロント大学の者です。あなたがしてくれたすべての仕事に感謝します。LLMは分布外のマルチホップ推論を一般化できると思いますか?
イリヤさて、この質問は答えが「イエス」か「ノー」のどちらかであることを前提としているが、本当はそのように答えるべきものではない。というのも、私たちはまず、分配外一般化とは実際には何を意味するのか?分配内一般化とは何か?分配外とは何か? これは "タイムテスト "についての話だからだ。ずっとずっと昔、ディープラーニングが登場する前、人々は文字列マッチングやN-gramを使って機械翻訳を行っていた。その頃、人々は統計的フレーズテーブルに頼っていました。想像できますか?これらの方法は何万行もの複雑なコードを持っていました。そして当時、汎化とは、翻訳結果がデータセットのフレーズ表現と文字通り同一でないかどうかということでした。 今なら、「私のモデルは数学コンテストで高得点を取ったが、この数学の問題のアイデアのいくつかは、ある時点でインターネット上のフォーラムで議論されたもので、モデルはそれを記憶しているだけかもしれない」と言えるかもしれない。 まあ、これは分布の範囲内かもしれないし、暗記した結果かもしれないとも言える。しかし、私たちの一般化の基準が劇的に上がったのは事実だと思います。
つまり、私の答えは、ある程度までは、モデルは人間ほど一般化が得意ではないということだ。私は、人間の方が一般化においてはるかに優れていると思います。しかし同時に、AIモデルはある程度分布外の汎化が可能であることも事実です。少し冗長に聞こえるかもしれないが、この答えがあなたにとって役に立つことを願っている。
Q:ありがとうございます。
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事


コメントはありません