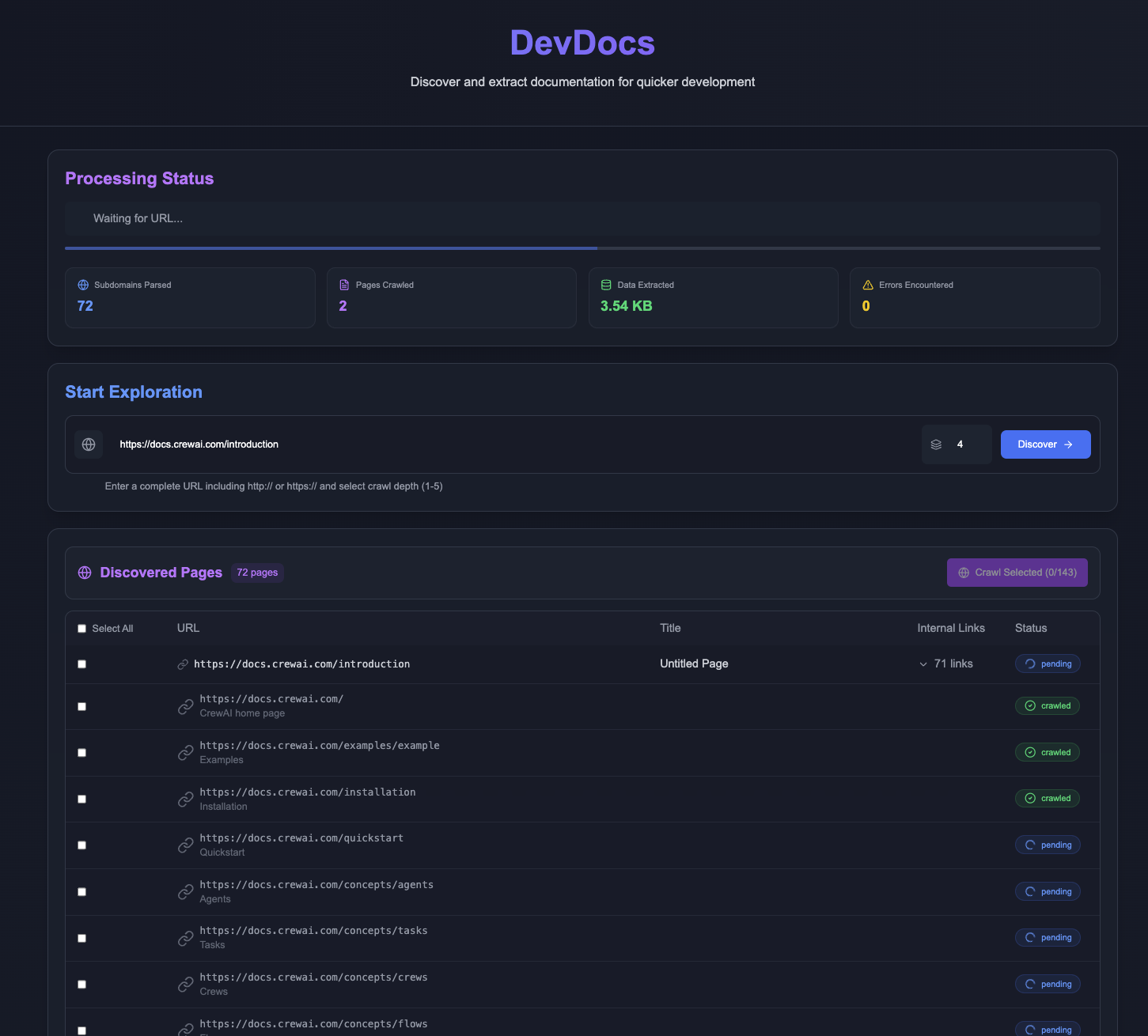
HippoRAG: 長期記憶に基づくマルチホップ知識検索フレームワーク

はじめに
HippoRAGはオハイオ州立大学のOSU-NLPグループによって開発されたオープンソースのフレームワークで、人間の長期記憶メカニズムにヒントを得ています。HippoRAG 2はHippoRAGの最新バージョンで、NeurIPS 2024でデモされた。HippoRAG 2は、NeurIPS 2024でデモされたHippoRAGの最新バージョンで、低コストと低遅延を維持しながら、マルチホップ検索と複雑な文脈理解を実行するモデルの能力を向上させている。GraphRAGのようなソリューションに比べ、オフライン・インデックス作成におけるリソースのフットプリントが少ない。ユーザーはGitHub経由でコードを入手し、無料でデプロイすることができる。

HippoRAG2の実施方法
機能一覧
- ドキュメントの索引付け外部文書を検索可能な知識構造に変換し、継続的な更新をサポートします。
- マルチホップ検索知識を結びつけて、多段階の推論を必要とする問題に答える。
- Q&A世代検索結果に基づいて的確な回答を生成します。
- モデルサポートOpenAIのモデルとネイティブに対応 ブイエルエルエム 配備されたLLM。
- 効率的な処理高速なオンライン検索と低いオフライン索引付けリソース要件。
- 実験的検証研究の再現性をサポートするためのデータセットとスクリプトを提供する。
ヘルプの使用
設置プロセス
HippoRAGのインストールは簡単で、Pythonの基本的な知識を持つユーザーに適しています。以下はその詳細な手順である:
- 仮想環境の構築
ターミナルで以下のコマンドを入力して、Python 3.10の環境を作る:
conda create -n hipporag python=3.10
そして環境をアクティブにする:
conda activate hipporag
- HippoRAGのインストール
活性化された環境で実行される:
pip install hipporag
- 環境変数の設定
ハードウェアと要件に応じて、以下の変数を設定します。例えば、複数のGPUを使用する:
export CUDA_VISIBLE_DEVICES=0,1,2,3
export HF_HOME=<你的 Huggingface 目录路径>
export OPENAI_API_KEY=<你的 OpenAI API 密钥> # 使用 OpenAI 模型时需要
環境が有効になるように、もう一度アクティベートしてください:
conda activate hipporag
OpenAIモデルの使用
HippoRAGをすぐに使い始めるには、OpenAIのモデルを使うことができる。以下はその手順です:
- 書類の準備
例えば、文書のリストを作成する:
docs = [
"张三是一名医生。",
"李四住在北京。",
"北京是中国的首都。"
]
- HippoRAGの初期化
Pythonでパラメータを設定する:from hipporag import HippoRAG save_dir = 'outputs' llm_model_name = 'gpt-4o-mini' embedding_model_name = 'nvidia/NV-Embed-v2' hipporag = HippoRAG(save_dir=save_dir, llm_model_name=llm_model_name, embedding_model_name=embedding_model_name) - インデックスファイル
索引付けのための文書を入力する:hipporag.index(docs=docs) - 質問と回答
質問を入力すると答えが表示されます:queries = ["张三做什么工作?", "李四住在哪里?"] rag_results = hipporag.rag_qa(queries=queries) print(rag_results)出力は次のようになる:
- チャン・サンは医者だ。
- 北京在住。
ネイティブvLLMモデルの使用
ローカルにデプロイしたいですか?HippoRAGをvLLMで実行することができます:
- vLLMサービスの開始
Llamaモデルなどで、ターミナルでローカルサービスを開始する:export CUDA_VISIBLE_DEVICES=0,1 export VLLM_WORKER_MULTIPROC_METHOD=spawn export HF_HOME=<你的 Huggingface 目录路径> conda activate hipporag vllm serve meta-llama/Llama-3.3-70B-Instruct --tensor-parallel-size 2 --max_model_len 4096 --gpu-memory-utilization 0.95 - HippoRAGの初期化
ローカルサービスのアドレスをPythonで指定する:hipporag = HippoRAG(save_dir='outputs', llm_model_name='meta-llama/Llama-3.3-70B-Instruct', embedding_model_name='nvidia/NV-Embed-v2', llm_base_url='http://localhost:8000/v1') - インデックス&Q&A
操作はOpenAIモデルと同じで、ドキュメントと質問を入力するだけです。
注目の機能操作
マルチホップ検索
HippoRAGのハイライトはマルチホップ検索だ。例えば、"Li Si lives in the capital city of which country? "と尋ねると、システムはまず "Li Si lives in Beijing "を見つけ、次に "Beijing is capital of China "と関連づけて "China "と答える。 システムはまず "Li Si lives in Beijing "を見つけ、それを "Beijing is the capital of China "と関連付け、"China "と答える。使い方は、質問を入力するだけです:
queries = ["李四住在哪个国家的首都?"]
rag_results = hipporag.rag_qa(queries=queries)
print(rag_results)
実験的再現
論文の結果を検証したいですか? HippoRAGは再現ツールを提供します。
- データセットの準備
GitHubまたはHuggingFaceからデータセットをダウンロードする(例sample.jsonを入れる。reproduce/datasetカタログ - 走行実験
それをターミナルに入力する:python main.py --dataset sample --llm_base_url https://api.openai.com/v1 --llm_name gpt-4o-mini --embedding_name nvidia/NV-Embed-v2 - 結果を見る
出力をチェックして、マルチホップ検索とQ&Aの有効性を検証する。
オフラインバッチ処理
vLLMはオフラインモードをサポートし、インデックス作成速度を3倍以上向上させることができる。操作方法は以下の通り:
- オフラインバッチの実行
export CUDA_VISIBLE_DEVICES=0,1,2,3 export HF_HOME=<你的 Huggingface 目录路径> export OPENAI_API_KEY='' python main.py --dataset sample --llm_name meta-llama/Llama-3.3-70B-Instruct --openie_mode offline --skip_graph - フォローアップ手術
終了したら、オンライン・モードに戻り、vLLMサービスとQ&Aプロセスを実行する。
ほら
- 記憶障害GPUメモリが不足している場合は、GPUメモリを調整してください。
max_model_lenもしかしたらgpu-memory-utilization. - テスト中にコンポーネントを調整するの使用
reproduce/dataset/sample.jsonテスト環境。 - 書類審査実験を再実行する前に古いデータを消去する:
rm -rf outputs/sample/*
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事


コメントはありません