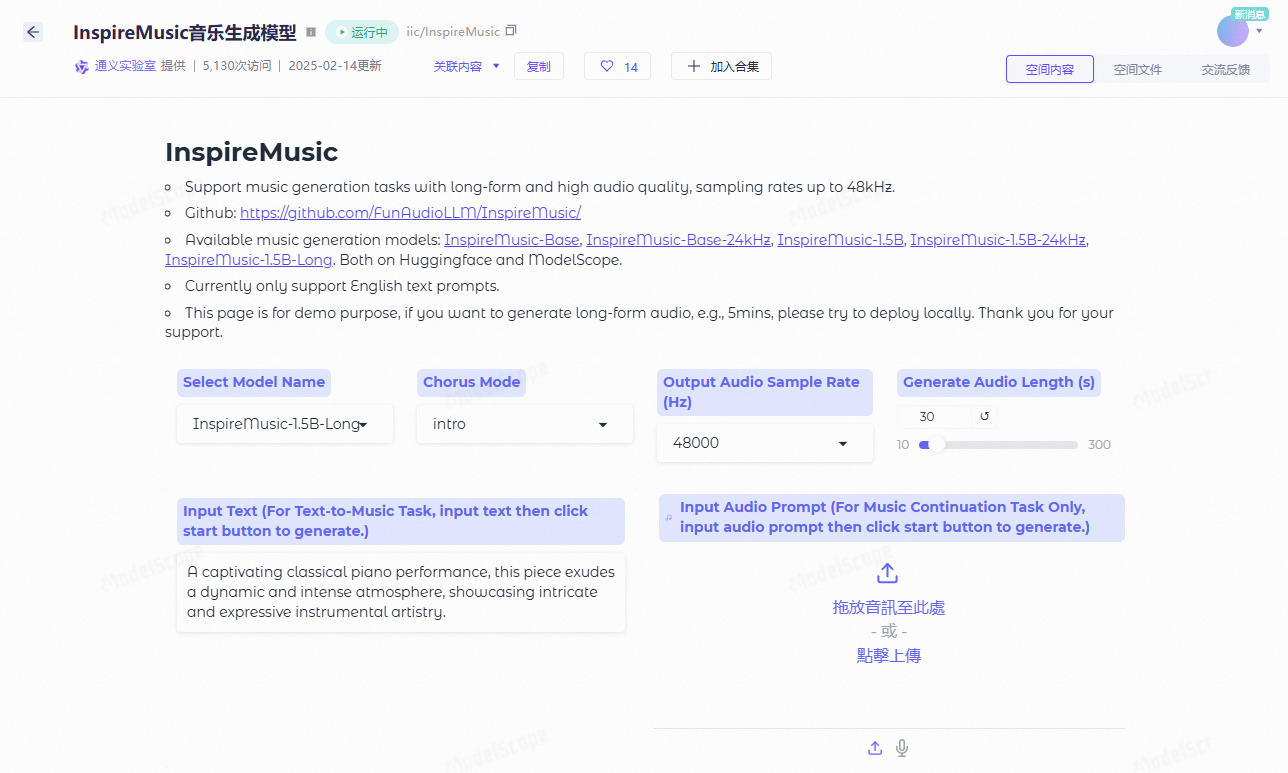
HiOllama: Ollamaのネイティブ・モデルと対話するためのクリーンなチャット・インターフェース

はじめに
HiOllamaは、PythonとGradioで作られた、Ollamaモデルと対話するためのユーザーフレンドリーなインターフェースです。リアルタイムのテキスト生成とモデル管理機能をサポートし、シンプルで直感的なウェブインターフェースを提供します。ユーザーは、温度やトークンの最大数などのパラメータを調整することができ、複数のOllamaモデルの管理やカスタムサーバーURLの設定をサポートしています。
レコメンデーション:オッラマvs. WebUIを開く 統合はより友好的だが、導入コストは若干高くなる。

機能一覧
- シンプルで直感的なウェブインターフェース
- リアルタイムテキスト生成
- 調整可能なパラメータ(温度、最大メダル数)
- モデル管理機能
- 複数のOllamaモデルをサポート
- カスタムサーバーURLの設定
ヘルプの使用
インストール手順
- クローン倉庫
git clone https://github.com/smaranjitghose/HiOllama.git cd HiOllama - 仮想環境を作成し、起動する:
- ウィンドウズ
python -m venv env .\env\Scripts\activate - Linux/Mac。
python3 -m venv env source env/bin/activate
- ウィンドウズ
- 必要なパッケージをインストールする:
pip install -r requirements.txt - Ollamaをインストールする(まだインストールされていない場合):
- Linux/Mac。
curl -fsSL https://ollama.ai/install.sh | sh - ウィンドウズ
まずWSL2をインストールしてから、上記のコマンドを実行してください。
- Linux/Mac。
使用手順
- Ollamaサービスを開始する:
ollama serve - ヒオラマを走らせる:
python main.py - ブラウザを開き、次のページに移動する:
http://localhost:7860
クイックスタートガイド
- ドロップダウンメニューからモデルを選択します。
- テキストエリアにプロンプトを入力します。
- 必要に応じて、温度と最大メダル数を調整する。
- Generate "をクリックし、返答を得る。
- モデル管理オプションを使用して、新しいモデルを取り込みます。
コンフィグ
デフォルト設定はmain.pyで修正した:
DEFAULT_OLLAMA_URL = "http://localhost:11434"
DEFAULT_MODEL_NAME = "llama3"
一般的な問題
- 接続エラーOllamaが起動していることを確認する。
ollama serve)、サーバーのURLが正しいことを確認し、ポート11434がアクセス可能であることを確認する。 - モデルが見つかりませんまずモデルを引っ張ってください:
ollama pull model_name利用可能なモデルを確認してください:ollama list. - 港湾紛争で
main.pyのポートを変更する。app.launch(server_port=7860) # 更改为其他端口
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事


コメントはありません