
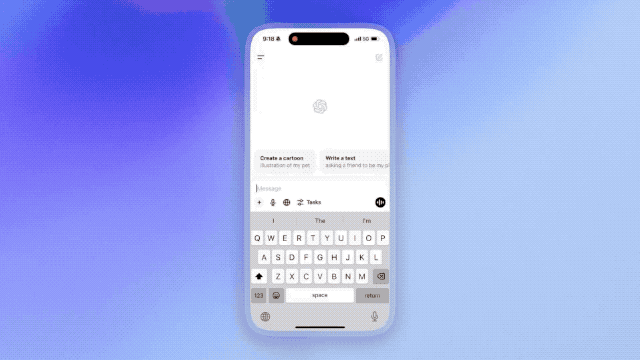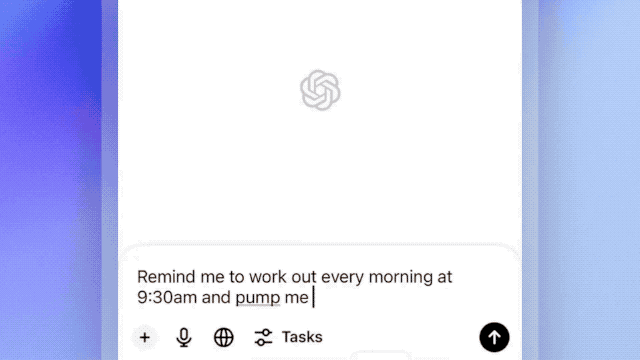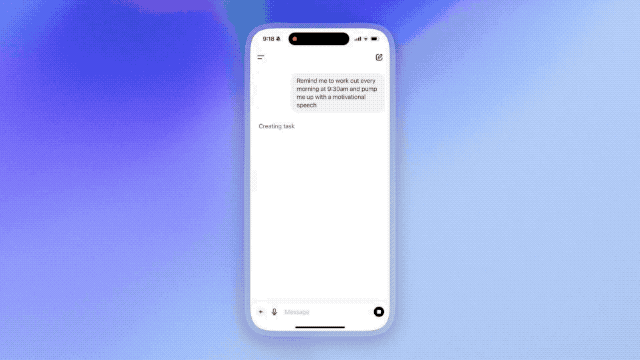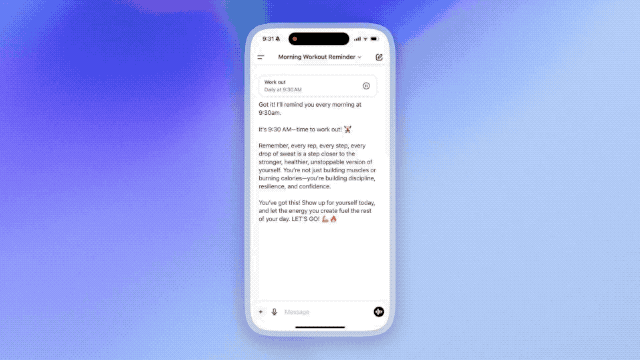
国産ビッグモデルデビューの中国論理推理、「天宮ビッグモデル4.0」o1バージョンが登場!

テクノロジーがこれほど急速に発展しているとは知らなかった。最近、人々はすでにAI時代の後の生活を想像している。
週末、JPモルガン・チェースのジェイミー・ダイモンCEOは、AI技術のおかげで未来の世代は週3日半働くだけで100歳まで生きられると語った。
ジェネレーティブAIのようなテクノロジーは、現在、人々の労働時間の60~70%を占めているタスクを自動化する可能性があることを示唆する研究もある。このような変化に必要なテクノロジーはどこから来るのだろうか?一般的な人工知能(AGI)の出現時期について、さまざまなAIの大物たちが予測したリストをまとめた人がいる。ディープマインドのハサビスは、AGIの出現まであと2~3回の大きな技術革新があると考えている。

オープンエイのCEOであるサム・アルトマンのように、彼はAGIが来年には登場するとさえ考えている。そういえば。このような自信の理由は、人々が最近、大きなモデルに「理性」を学ばせたという事実にあるのかもしれない。.
ちょうど9月、OpenAIは前例のない複雑な推論の大規模モデル「o1」を公式に公開した。この新しいモデルは、汎用的な能力と、これまでの科学的、コード的、数学的モデルよりも難しい問題を解決する能力を併せ持つという点で、大きなブレークスルーとなった。実験結果は、o1が推論タスクの大部分においてGPT-4oを大幅に上回ることを示している。

OpenAIは、ビッグモデルの能力について新たな方向性を切り開いた。「人間のように考え、推論できるかどうか」が、その能力を判断する重要な指標になったのだ。もし、ベンダーが発表する新しいモデルが思考の連鎖を持っていなければ、恥ずかしくて見せられないだろう。
しかし現在に至るまで、o1の正式バージョンはまだ遅れている。AIコミュニティ、特に中国の大手モデル会社は、o1の優位性に影響を与え、いくつかの権威あるレビューで主導権を握り始めている。
今日は崑崙MSIが発表した「Skywork 4.0」o1バージョン(英語名:Skywork o1)である。.同社にとって、ビッグモデルや関連アプリケーションに関する大きな動きは、この1ヶ月で3度目となる。Skyworks AI アドバンス検索そしてリアルタイム音声対話AIアシスタント Skyo 連続出場。

今後、スカイワークo1では社内テストを実施する。
www.tiangong.cn。
3つのモデルを並べる
推理の新たな戦場
今回のスカイワークo1には、オープンソースコミュニティへの還元を目的としたオープンバージョンと、より高性能な専用バージョンの、以下の3モデルが含まれる。
とりわけ、オープンソース版の スカイワーク o1 オープン また、Llama-3.1-8Bを同じエコシステムのSOTAに引き込み、Qwen-2.5-7Bのインストラクターを上回った。同時に、スカイワークo1オープンは、GPT-4oのような大規模モデルでは不可能な数学的推論タスク(24ポイント計算など)をアンロックする。これはまた、軽量デバイスに推論モデルを展開する可能性を開くものでもあります。


さらに、崑崙は推論タスクのための2つのPRM(Process-Reward-Models)もオープンソース化する。 スカイワークo1オープンPRM-1.5B 歌で応える スカイワークo1オープンPRM-7B以前オープンソース化されていたSkywork-Reward-Modelは、モデル応答全体を採点するだけでした。以前オープンソースで提供されていたSkywork-Reward-Modelはモデルレスポンス全体を採点するだけでしたが、Skywork o1 Open-PRMはモデルレスポンスの各ステップを採点するように改良することができます。
オープンソースコミュニティの既存のPRMと比較して、Skywork o1 Open-PRM-1.5Bは、RLHFlowのLlama3.1-8B-PRM-Deepseek-DataやOpenRのMath-psa-7Bのような8Bモデルの結果を達成することができます。Open-PRM-7Bはより強力で、ほとんどのベンチマークでQwen2.5-Math-RM-72Bに近づき、あるいはQwen2.5-Math-RM-72Bを10倍上回ります。
と報じられている。Skywork o1 Open-PRMは、コードベースのタスクのための最初のオープンソースPRMでもあります。.以下の表は、Skywork-o1-Open-8Bをベースモデルとして、MathsセットとCode Reviewセットで異なるPRMを使用した評価結果です。


注:Skywork-o1-Open-PRMを除き、他のオープンソースPRMはコードベースのタスクに特に最適化されていないため、コードベースのタスクに関する比較は行っていない。
詳細な技術報告書もまもなく発表される。このモデルと関連するプレゼンテーションは、現在Huggingfaceでオープンソース化されている。
オープンソースのアドレス:https://tinyurl.com/skywork-o1
スカイワーク o1 Lite 完全な思考力を持ち、推理や思考のスピードが速いため、特に中国の論理や推理、数学などの問題を得意とする。スカイワークo1プレビュー これは推論モデルの完全版であり、自己開発したオンライン推論アルゴリズムで、Lite版と比較して、より完全で質の高い推論を達成するために、より多様で深い思考プロセスを提示することができます。
スカイワークo1は、推論レベルで動作するo1モデルの再現に関する現在の仕事と何が違うのかと尋ねられるかもしれない。
崑崙は、一連のモデルは、モデルの出力について考え、計画し、反映させる能力を内生化し、推論し、反映させ、ゆっくりとした思考で一歩一歩検証し、「深い思考」のような複雑な人間の思考能力の典型的な高度版を解き放ち、答えの質と深さを保証すると述べた。
もちろん、スカイワークo1が現場でどうなるかは見てみないとわからない。
実体験
今回、スカイワークのo1は完全にその理由に釘付けになった。
私は事前にテスト資格を取得し、スカイワークo1シリーズ、特にLite版とPreview版の推論能力をあらゆる角度から検証した。下図はスカイワークo1 Liteのインターフェースです。

まず、スカイワークo1 Liteに自分自身を公表させることから始める。問題志向性、自己能力プロファイリングなどを含む完全な思考プロセスをユーザーに可視化する。そして思考時間を示すこれは今日の推論モデルの特徴である。

公式テストに移り、私たちはスカイワークのo1について実際に理解できるかどうかを確認するため、さまざまなタイプの推論問題を解いた。
サイズを比較し、"r "の問題を数え、もう後戻りはしない!
これまでの大型モデルは、サイズを比較したり数を数えたりといった一見単純な問題に直面すると、しばしば失敗していた。スカイワークo1 Liteでは、こうした問題はもはや問題ではない。
13.8が13.11より大きいかどうかを比較するとき、スカイワークo1 Liteは、問題を解く鍵が小数点以下の桁の大きさにあることを見つけるために、完全な思考の連鎖を行います。また、このモデルは自己反省も行い、到達した結論を再確認し、不正解になりやすいポイントを思い出させます。

同様に、"いちごには "r "がいくつありますか?"という質問に正しく答える際にも、スカイワークo1 Liteは、思考、検証、確認の完全な連鎖を実現します。スカイワークo1 Liteは、"Strawberryには "r "がいくつあるか?"に正しく答えるための思考、検証、確認の完全な連鎖でもあります。

スクランブルをかけた質問に答えるとき、スカイワークo1 Liteは、雑念を素早く取り除きます。

言葉の罠にはまらない脳トレ遊び
大モデルが中国語文脈の脳を刺激する問題に惑わされ、間違った解答をしてしまうことがあります。今回のSkywork o1 Liteは、そのような問題を簡単に解くことができます。


2組の親子が3匹しか釣らなかったが、それぞれが1匹ずつゲットし、スカイワークo1 Liteは何が起こっているのかを解明することができた。

さまざまな常識を身につけ、知恵遅れ属性にサヨナラしよう
大規模なモデルが人間の常識的推論のレベルに近づけるかどうかは、そのモデルの信頼性を高め、意思決定能力を強化し、複数のドメインへの応用を拡大できるかどうかの最も重要な指標の1つである。スカイワークo1 Liteとプレビューは、この点で良い結果を出している。
例えば、長さ(インチ、センチ、ヤード)と質量単位(キログラム)の区別。

例えば、なぜ塩水の角氷は普通の水の角氷よりも溶けやすいのか。

もうひとつの例は、完全に静止したボートの上に立っている人が、後ろにジャンプすると前に進むというものだ。

問題解決能力を身につければ、GCSEの問題に困ることはない!
数学的推論は、複雑なタスクを解決するための基本的な能力であり、強力な数学的推論能力を備えた大規模モデルは、ユーザーが複雑な学際的タスクを効率的に解決するのに役立つ。
数列問題「2、6、12、20、30...」の数列「2、6、12、20、30...」の第10項は? この数列の第10項は何か」。スカイワークo1 Liteは、数字の並びを観察し、パターンを見つけ、そのパターンを検証し、最後に正解を出す。

組み合わせの問題(10人中3人のチームを作るにはいくつの選択肢を選ぶか)を解くとき、スカイワークo1プレビューはフルリンクで考えた末に正解を出した。

別の動的計画法(額面1、3、5のコインを11枚作るには何枚必要か)問題では、スカイワークo1 Liteが最適解を与える。

2024年度GCSE全国ペーパーA数学(Wen)から2問を出題し、スカイワークo1 Liteを少し難しくします。
確率の問題(A、B、C、Dが一列に並び、Cが列の先頭になく、AかBのどちらかが列の最後にある確率は)から始まり、スカイワークo1 Liteが素早く正解を出す。

それから、関数に関する質問(  )、Skywork o1 Liteのソリューションと回答を一挙にご紹介します。
)、Skywork o1 Liteのソリューションと回答を一挙にご紹介します。

緻密で論理的な思考能力
大規模なモデルを用いた論理的推論は、より強力な汎用AIを実現するための中核的な能力の一つであり、スカイワークo1 Liteはそのような問題に答えることに長けています。例えば、古典的な嘘の問題では、スカイワークo1 Liteは、論理的に自己矛盾のない観点から、誰が本当のことを言っているのか、誰が嘘をついているのかを見分けることができます。

スカイワークo1ライトは、パラドックスに目を奪われることもない。

道徳的ジレンマに直面したときの公平性
倫理的な意思決定は、AIの安全な開発、道徳的な社会規範の遵守、ユーザーの信頼と受容の向上を保証するための重要な要素であり、ビッグモデルにとっては、発言に注意することがより重要である。
Skywork o1 Liteは、「妻を救うか、母親を救うか」という古くからのジレンマに絶対的な答えを与えるのではなく、長所と短所を比較検討し、適切なアドバイスを与える。

スカイワークのo1プレビューは、結論を急がず、より深い考えを提示している。

このテストは、知恵遅れのテストだ。
スカイワークo1 Liteは、大学入試で750点満点を取るか985点満点に入るかの違いなど、大型モデルの知能テストによく使われるような知恵遅れの問題にも簡単に答えることができる。

それから「夜にランチミートを食べられるか」だが、スカイワークのo1 Liteは明らかに食べ物の名前に惑わされない。

コードの問題も修正可能
スカイワークo1 Liteは、LeetCodeの島の数の問題など、いくつかのコード問題を解くことができます。
1」(陸地)と「0」(水)の2次元格子地図が与えられたとき、島の数を数えなさい。島は水に囲まれており、隣接する陸地を水平または垂直に結ぶことで形成される。"格子の4辺はすべて水に囲まれていると仮定してよい。

この時点で、私たちは次の結論を導き出すことができる:
一方では、大型モデルが転がり落ちていた "小さな "問題も、推理力のあるスカイワークo1の目には楽勝に映る。一方で思考と計画の完全な連鎖、自省と自己検証スカイワークo1はまた、複雑な問題シナリオを考え抜き、より正確で効率的な結果を出すことができる。
このように、従来よりもはるかに強力な推論能力は、スカイワークo1がより多様なペンダントタスクやドメイン、特に論理的推論や複雑な科学的・数学的タスクなど、転がりやすいタスクに適用される可能性を刺激する。また、スカイワークの登場は、クリエイティブ・ライティングのような質の高いコンテンツ生成やディープ・サーチのタスクの効果をさらに最適化するはずです。
国内O1モデル
技術主導の自己研究
これまで、崑崙万威が提案した検索、音楽、ゲーム、ソーシャルネットワーキング、AIショートプレイなどの一連の生成的AI垂直応用をすでに目撃した。崑崙万威は、ビッグモデルの基礎技術の研究開発において、長い間、レイアウトを持っていた。
2020年以降、崑崙万威はAIビッグモデルへの投資を継続的に強化しており、ChatGPTが稼動したわずか1カ月後には独自のAIGCモデルシリーズをリリースしている。崑崙は、世界初のAIストリーミング音楽プラットフォーム「Melodio」、AI音楽制作プラットフォーム「Mureka」、AIショートドラマプラットフォーム「Mureka」など、多くの分野ですでにアプリケーションを発表している。 スカイリール などなど。
基礎技術レベルでは、崑崙はすでに「演算インフラ-ビッグモデルアルゴリズム-AI応用」という全産業チェーンレイアウトを構築しており、そのうちビッグモデルの「天宮」シリーズが中核となっている。
昨年4月、崑崙ワールドワイドは自社開発の「天宮1.0」モデルを発表した。今年4月、天宮モデルはバージョン3.0にアップグレードされ、4000億のパラメーターを持つMoEハイブリッドエキスパートモデルを採用し、同時にオープンソースを選択した。現在、天宮4.0バージョンは、インテリジェント創発の方法に基づいて、論理的推論タスクの能力向上を達成する。
技術的には、スカイワークo1の論理的推論タスクのパフォーマンスは、スカイワークが独自に開発した以下のような3段階のトレーニングソリューションのおかげで劇的に向上しています:
まず推論と内省のスキルトレーニングスカイワークo1は、自ら開発したマルチ・インテリジェンス・ボディシステムにより、高品質なステップバイステップの思考、考察、検証データを構築し、高品質で多様な長期思考データにより補完され、継続的な事前トレーニングとベースモデルの監視下での微調整を行います。
ついで推論集中学習スカイワークo1チームは、複雑な推論タスクの最終解答に対する中間ステップや思考ステップの影響を効果的に捉えるだけでなく、自社開発のステップバイステップ推論強化アルゴリズムと組み合わせることで、モデルの推論・思考能力をさらに強化する、ステップバイステップ推論強化のための最新のスカイワークo1プロセス報酬モデル(PRM)を開発しました。
さんばん推論.天宮が独自に開発したQ *オンライン推論アルゴリズムに基づき、モデルと連携してオンラインで思考し、最適な推論経路を見つける。これは、MATHのようなデータセットに対するLLMの推論能力を大幅に向上させ、コンピューティングリソースの需要を削減することができます。

MATH データセットでは、Q * は DeepSeek-Math-7b の精度を 55.4% まで向上させ、DeepSeek-Math-7b を上回った。 ジェミニ ウルトラだ。
Q * アルゴリズム論文のアドレス:https://arxiv.org/abs/2406.14283
崑崙万威の技術は業界をリードするレベルに達しており、競争の激しいジェネレーティブAI分野で徐々に確固たる地位を築いていることが分かる。
現在のジェネレーティブAIアプリケーションの開花に比べ、研究は基礎技術レベルの「深海」に入り始めている。長期的な蓄積を持つ企業だけが、私たちの生活を変える新世代のアプリケーションを構築できるだろう。
私たちは、崑崙万威が今後ますます強力な技術をもたらしてくれることを期待している。
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事

コメントはありません