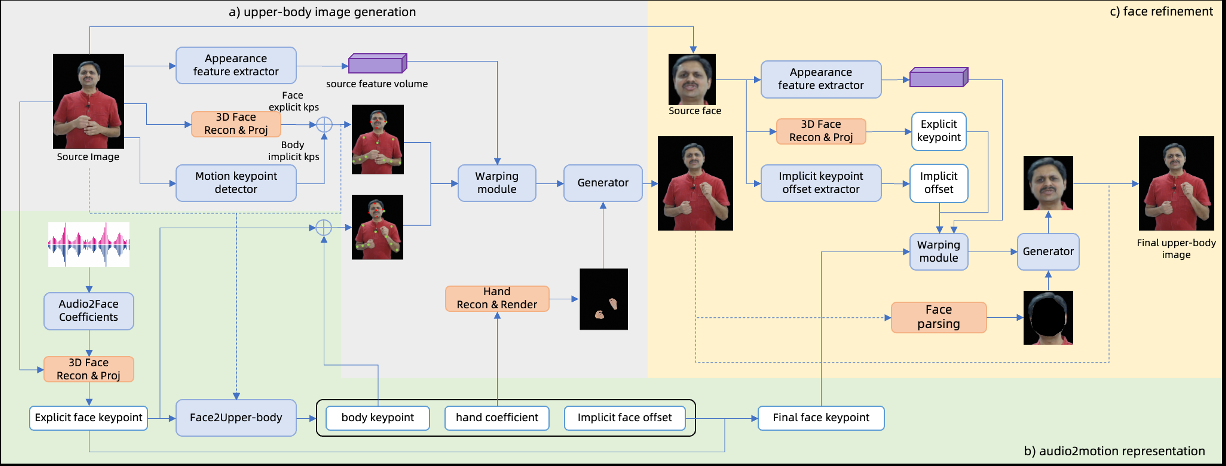
Firecrawl MCPサーバー: FirecrawlベースのWebクローラーMCPサービス

はじめに
ファイヤークロール エムシーピー サーバーは、MendableAIによって開発されたオープンソースツールです。 モデル・コンテキスト・プロトコル (MCP)プロトコルの実装は、Firecrawl APIと統合され、強力なウェブクローリングとデータ抽出を提供します。Cursor、Claude、その他のLLMクライアントのようなAIモデル用に設計され、単一ページのクローリングからバッチクローリング、検索、構造化データ抽出まで、幅広いオペレーションをサポートします。動的ウェブページのJavaScriptレンダリング、ディープクローリング、コンテンツフィルタリングなど、Firecrawl MCP Serverは効率的に仕事をこなします。このツールは、開発者、研究者、データエンジニアのために、自動再試行、レート制限、ロギングシステムを備え、クラウドとセルフホストデプロイの両方をサポートしている。2025年3月現在、プロジェクトはGitHub上で継続的に更新されており、コミュニティによって広く認知されている。

機能一覧
- シングルページ・グラブ指定されたURLからMarkdownまたは構造化データを抽出します。
- バルククローラー並列動作と内蔵レート制限のサポートにより、複数のURLを効率的に処理。
- ウェブ検索クエリに基づいて検索結果からコンテンツを抽出します。
- ディープクローリングURLディスカバリーとマルチレイヤーウェブクローリングをサポート。
- データ抽出LLMを用いたウェブページからの構造化情報の抽出。
- JavaScriptレンダリング動的なウェブページの全コンテンツをキャプチャします。
- インテリジェント・フィルトレーションタグインクルード/エクスクルードによるコンテンツフィルタリング。
- コンディション・モニタリングバッチタスクの進捗状況やクレジット使用量のクエリーを提供します。
- ログシステム動作状態、パフォーマンス、エラーメッセージを記録します。
- モバイル/デスクトップ対応異なるデバイスのビューポートに適応。
ヘルプの使用
設置プロセス
Firecrawl MCP Server は、さまざまな使用シナリオに対応するため、さまざまなインストール方法を提供しています。以下はその詳細な手順である:
方法1:npxを使ったクイックラン
- FirecrawlのAPIキーを取得する(取得するにはFirecrawlのウェブサイトに登録する)。
- ターミナルを開き、環境変数を設定する:
export FIRECRAWL_API_KEY="fc-YOUR_API_KEY"
相互互換性 "fc-YOUR_API_KEY" を実際のキーに置き換えてください。
3.オーダーを実行する:
npx -y firecrawl-mcp
- 起動に成功すると、端末には次のように表示される。
[INFO] FireCrawl MCP Server initialized successfully.
モード2:手動設置
- グローバル・インストール:
npm install -g firecrawl-mcp - 環境変数を設定する(上記の通り)。
- 走っている:
firecrawl-mcp
アプローチ3:セルフホスト・デプロイメント
- GitHubリポジトリをクローンする:
git clone https://github.com/mendableai/firecrawl-mcp-server.git cd firecrawl-mcp-server - 依存関係をインストールします:
npm install - ビルド・プロジェクト:
npm run build - 環境変数を設定して実行する:
node dist/src/index.js
方法4:カーソル上で実行する
- セキュア カーソル バージョン0.45.6以上。
- Cursor Settings(カーソル設定)> Features(機能)> MCP Servers(MCPサーバー)を開きます。
- Add New MCP Server "をクリックして入力します:
- 名前
firecrawl-mcp - タイプ
command - 命令だ。
env FIRECRAWL_API_KEY=your-api-key npx -y firecrawl-mcp - 問題が発生しているWindowsユーザーは、試してみてください:
cmd /c "set FIRECRAWL_API_KEY=your-api-key && npx -y firecrawl-mcp"
- 名前
- Composerエージェントが自動的に呼び出すMCPサーバーのリストを保存し、更新する。
方法5:ウィンドサーフで走る
- コンパイラ
./codeium/windsurf/model_config.json::{ "mcpServers": { "mcp-server-firecrawl": { "command": "npx", "args": ["-y", "firecrawl-mcp"], "env": { "FIRECRAWL_API_KEY": "YOUR_API_KEY_HERE" } } } } - Windsurfを保存して実行します。
環境変数の設定
必要な構成
FIRECRAWL_API_KEYクラウドAPIキーは、クラウドサービスを利用する際に設定する必要があります。
オプション構成
FIRECRAWL_API_URLのようなセルフホスト・インスタンス用のAPIエンドポイント。https://firecrawl.your-domain.com.- 設定を再試行する:
FIRECRAWL_RETRY_MAX_ATTEMPTS最大リトライ回数、デフォルトは3。FIRECRAWL_RETRY_INITIAL_DELAYデフォルトは1000。FIRECRAWL_RETRY_MAX_DELAYデフォルトは10000。FIRECRAWL_RETRY_BACKOFF_FACTORデフォルトは2。
- クレジット・モニタリング:
FIRECRAWL_CREDIT_WARNING_THRESHOLD警告のしきい値。FIRECRAWL_CREDIT_CRITICAL_THRESHOLDデフォルトは100。
設定例
クラウドの利用:
export FIRECRAWL_API_KEY="your-api-key"
export FIRECRAWL_RETRY_MAX_ATTEMPTS=5
export FIRECRAWL_RETRY_INITIAL_DELAY=2000
export FIRECRAWL_CREDIT_WARNING_THRESHOLD=2000
主な機能
機能1:単一ページスクレイプ(firecrawl_scrape)
- 手続き::
- サーバーを起動したら、POSTリクエストを送信する:
curl -X POST http://localhost:端口/firecrawl_scrape \ -H "Content-Type: application/json" \ -d '{"url": "https://example.com", "formats": ["markdown"], "onlyMainContent": true, "timeout": 30000}' - メインコンテンツをMarkdown形式で返します。
- サーバーを起動したら、POSTリクエストを送信する:
- パラメータの説明::
onlyMainContent主要な要素のみを抽出。includeTags/excludeTagsHTMLタグを含めるか除外するかを指定します。
- アプリケーションシナリオ記事やページの核となる情報を素早く抽出。
機能2:バッチクロール(firecrawl_batch_scrape)
- 手続き::
- 一括リクエストを送信する:
curl -X POST http://localhost:端口/firecrawl_batch_scrape \ -H "Content-Type: application/json" \ -d '{"urls": ["https://example1.com", "https://example2.com"], "options": {"formats": ["markdown"]}}' - オペレーションIDを取得する。
batch_1. - ステータスをチェックする:
curl -X POST http://localhost:端口/firecrawl_check_batch_status \ -H "Content-Type: application/json" \ -d '{"id": "batch_1"}'
- 一括リクエストを送信する:
- 性格描写大規模データ収集のためのレート制限と並列処理を内蔵。
機能3:ウェブ検索(firecrawl_search)
- 手続き::
- 検索リクエストを送信する
curl -X POST http://localhost:端口/firecrawl_search \ -H "Content-Type: application/json" \ -d '{"query": "AI tools", "limit": 5, "scrapeOptions": {"formats": ["markdown"]}}' - 検索結果のMarkdownコンテンツを返します。
- 検索リクエストを送信する
- 使用クエリに関連するウェブページデータへのリアルタイムアクセス。
機能4:ディープクロール(firecrawl_crawl)
- 手続き::
- クロール要求を開始する:
curl -X POST http://localhost:端口/firecrawl_crawl \ -H "Content-Type: application/json" \ -d '{"url": "https://example.com", "maxDepth": 2, "limit": 100}' - クロールの結果を返す。
- クロール要求を開始する:
- パラメトリック::
maxDepthクロールの深さをコントロールする。limitページ数を制限する。
機能5:データ抽出(firecrawl_extract)
- 手続き::
- 抽出要求を送信する:
curl -X POST http://localhost:端口/firecrawl_extract \ -H "Content-Type: application/json" \ -d '{"urls": ["https://example.com"], "prompt": "Extract product name and price", "schema": {"type": "object", "properties": {"name": {"type": "string"}, "price": {"type": "number"}}}}' - 構造化データを返します。
- 抽出要求を送信する:
- 性格描写LLM抽出のサポート、カスタムスキーマによる出力フォーマットの確保。
ヒントとコツ
- ログビュー: 実行時にターミナルのログを見ておくこと(例えば
[INFO] Starting scrape)をデバッグする。 - エラー処理もし出会ったら
[ERROR] Rate limit exceededリトライパラメータを調整するか、待つ。 - LLMとの統合カーソルまたは クロード に直接クロールの要件を入力すると、ツールが自動的に起動します。
以上の操作により、ユーザーはFirecrawl MCP Serverを簡単に導入し、多様なウェブデータニーズに対応することができる。
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事



コメントはありません