
フライングパドルのPPシリーズが新しくなりました!PP-DocBee文書画像理解用の新しい「蜂」です!

文書画像理解技術は、コンピュータが人間と同じように文書画像の内容を理解できるようにすることを目的としている。主に、スキャンや写真撮影によって得られた文書画像(紙の契約書、書籍のページ、請求書など)を分析、処理、理解し、そこに含まれるテキスト、表、グラフなどの貴重な情報を抽出し、その情報を構造化することが含まれる。デジタルトランスフォーメーションの波が押し寄せる今日、文書画像理解技術は、文書処理の効率と精度を高めるために、ビジネス、学術、日常生活で広く利用されている。
以前、FeiPaddleはWenxin Big Modelと組み合わせて、PP-ChatOCRv3サイズモデル融合ソリューションをリリースした。これは、まずOCR技術を使って画像内のテキストを抽出し、それをWenxin Big Modelに入力してクイズを分析し、最終的にテキストと画像のレイアウト解析と情報抽出効果を大幅に向上させる。このスキームは、テキストや表については高い精度を誇るが、文書中の画像や図表を理解する能力はさらに向上させる必要がある。そこで、複雑で多様な文書画像理解タスクに対するユーザのニーズをより良く満たすために、マルチモーダルラージモデルに基づき、エンドツーエンドの文書画像理解を実現する新しいスキームPP-DocBeeを提案する。PP-DocBeeは、文書理解、文書Q&Aなど、あらゆる場面で効率的に適用可能である。特に、財務報告書、法令、論文、マニュアル、契約書、研究報告書など、中国語の文書理解の場面では、非常に優れた性能を発揮する。
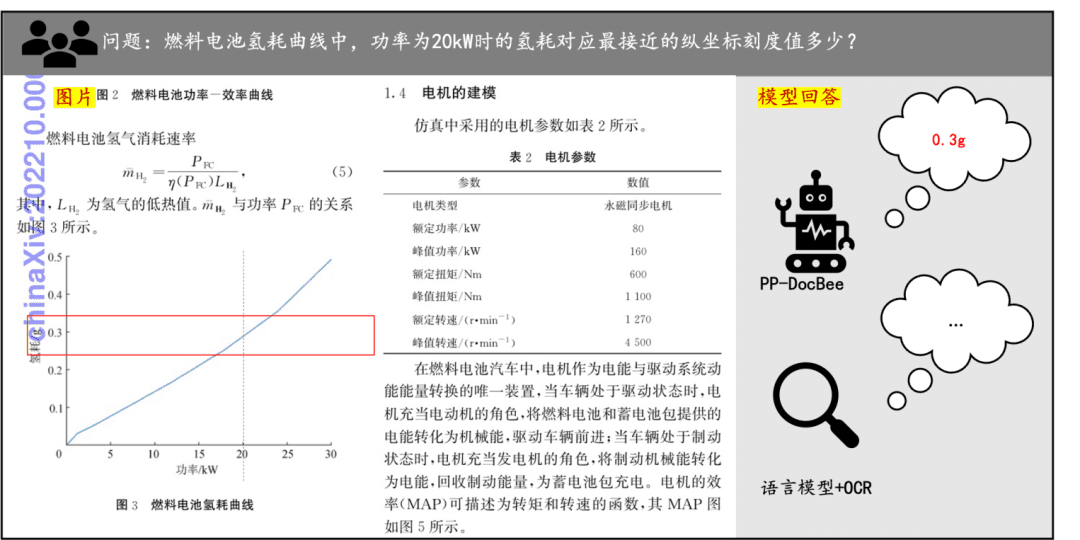
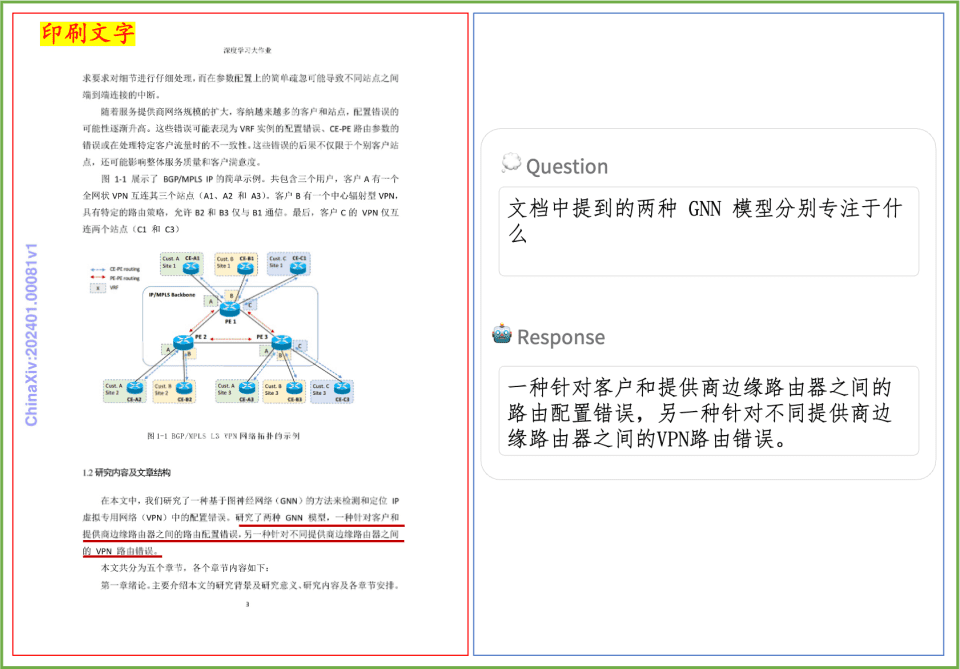
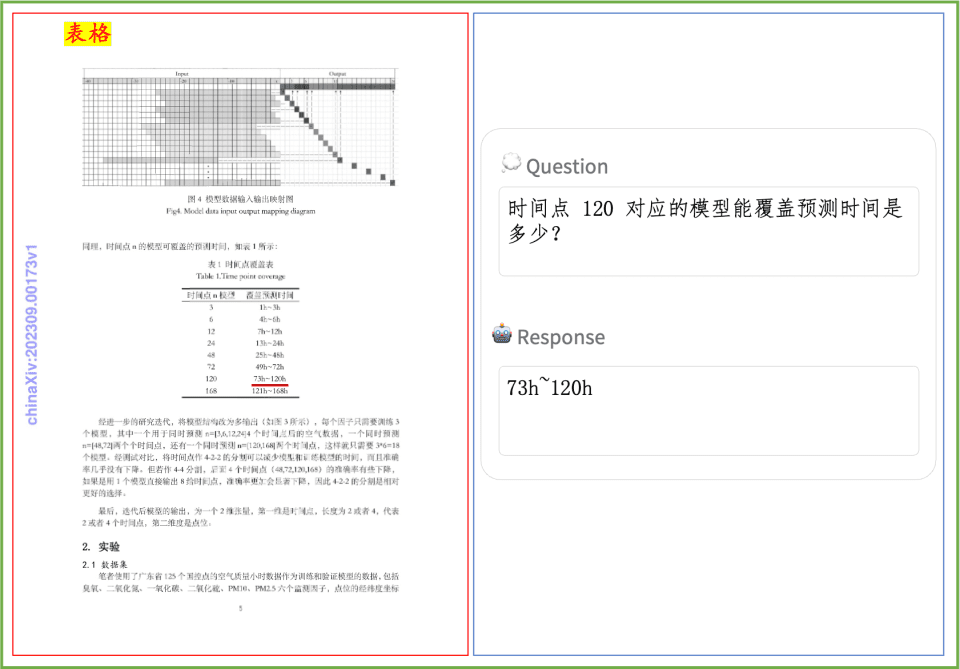
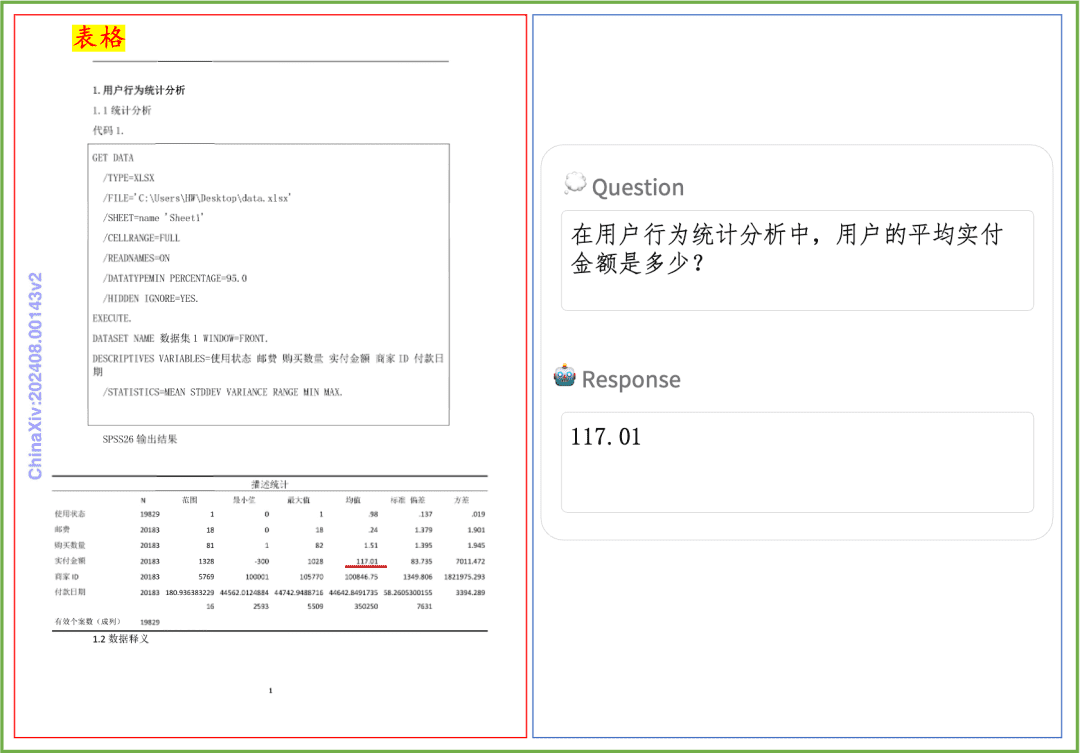
ドキュメント理解度の例 PP-DocBeeが印刷されたテキスト、表、グラフ、その他のドキュメントのドキュメント理解度に与える影響を簡単に見てみましょう:


PP-DocBeeは基本的に、学術的に権威のあるいくつかの英語文書理解レビューリストにおいて、同じパラメータ量レベルのモデルでSOTAを達成しています。
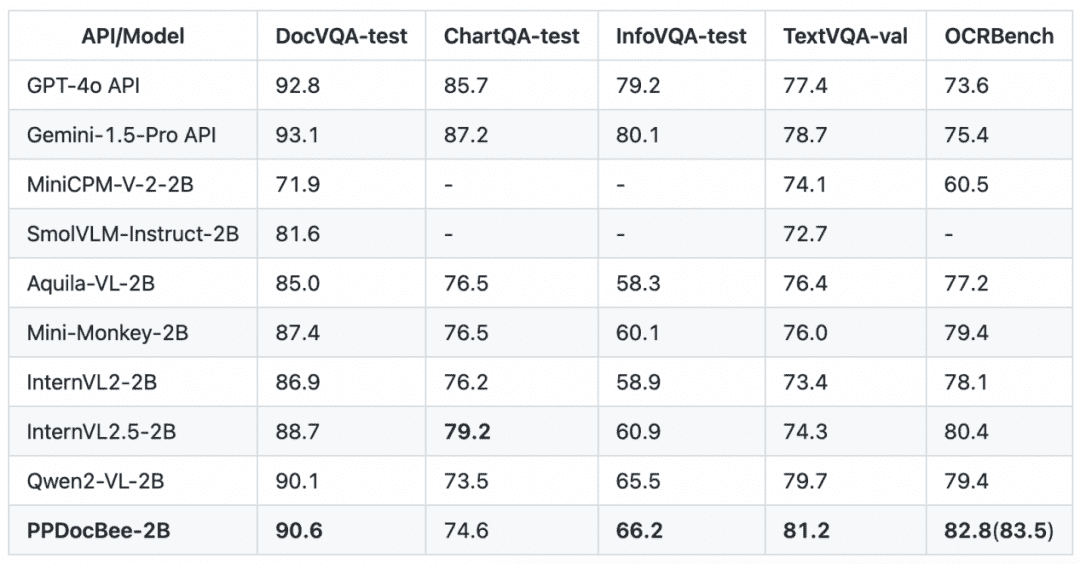
英語文書理解」レビュー一覧 競合他社比較
PPDocBee-2BのOCRBenchメトリクスはエンドツーエンド評価で82.8点、OCRポスト処理アシスト評価で83.5点です。PP-DocBeeはまた、内部ビジネス中国シナリオ・カテゴリのメトリクスにおいて、現在人気のあるオープン/クローズド・ソース・モデルよりも高い評価を得ています。
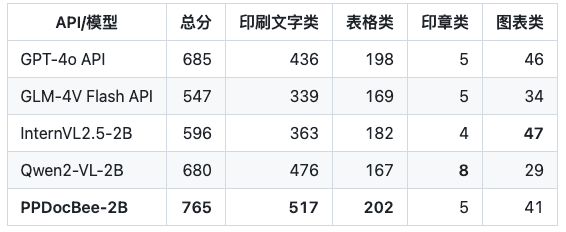
ビジネス中国語シナリオ 競合他社比較
注:中国語の社内業務シナリオ評価セットには、財務報告書、法令、科学技術論文、マニュアル、教養論文、契約書、研究論文などのシナリオが含まれ、印刷物、帳票、印鑑、図表の4つのカテゴリーに大別される。
PP-DocBeeの推論性能をさらに向上させるため、演算子融合の最適化により、推論経過時間を51.51 TP3T短縮し、エンド・ツー・エンドの合計経過時間を41.91 TP3T短縮しました。
| PP-ドクビー | 平均エンド・ツー・エンド時間(秒) | 平均前処理時間(秒) | 推論に費やした平均時間(秒) |
| デフォルトバージョン | 1.60 | 0.29 | 1.30 |
| 高性能版 | 0.93 | 0.29 | 0.63 |
注:高性能バージョンの出力トークンは、基本的に同じ入力トークンのデフォルトバージョンと同じ量です。フライング・パドルの高性能最適化のおかげで、PP-DocBeeは答えの質を維持しながら、より速く応答します。この高性能推論バージョンは https://github.com/PaddlePaddle/PaddleMIX/tree/develop/deploy/ppdocbee にあります。
また、Flying Paddle Star River Community Application Centre (https://aistudio.baidu.com/application/detail/60135) を通して、PP-DocBeeの機能を素早く体験できるオンライン体験環境も提供しています。
さらに、ローカルのgradioのデプロイメント、OpenAIのサービスのデプロイメント、および詳細なインストラクションも提供しています。ユーザーやマニアの方は、プロジェクトのホームページをご覧ください: https://github.com/PaddlePaddle/PaddleMIX/tree/develop/paddlemix/例/ppdocbee
PP-DocBeeプログラムの紹介
ViT+MLP+LLMのアーキテクチャを用いたPP-DocBeeのモデル構造を下図に示す。文書理解シナリオの最適化のアイデアは以下の通りです。データ合成戦略、データ前処理、トレーニング方法、OCR後処理支援最終的に、このモデルは汎用的な文書理解能力と、中国語のシナリオに対応した強力な文書解析能力の両方を備えている。

PP-DocBeeモデルの構造
具体的には、PP-DocBeeには次のような大きな改良が加えられている:
1.データ統合戦略
中国語能力不足とシーンデータ不足の問題に対処するため、文書タイプデータのインテリジェントな生成ソリューションを設計し、Doc、Table、Chartなどの3つの主要データタイプごとに異なるデータ生成リンクを設計し、OCR小型モデルとLLM大型モデルの組み合わせ、レンダリングエンジンに基づく画像データの生成、文書タイプごとのカスタマイズされたデータ生成など、多くの戦略を採用しました。その結果、Q&Aの品質が向上し、生成コストもコントロールできるようになった。その詳細を下図に示す:
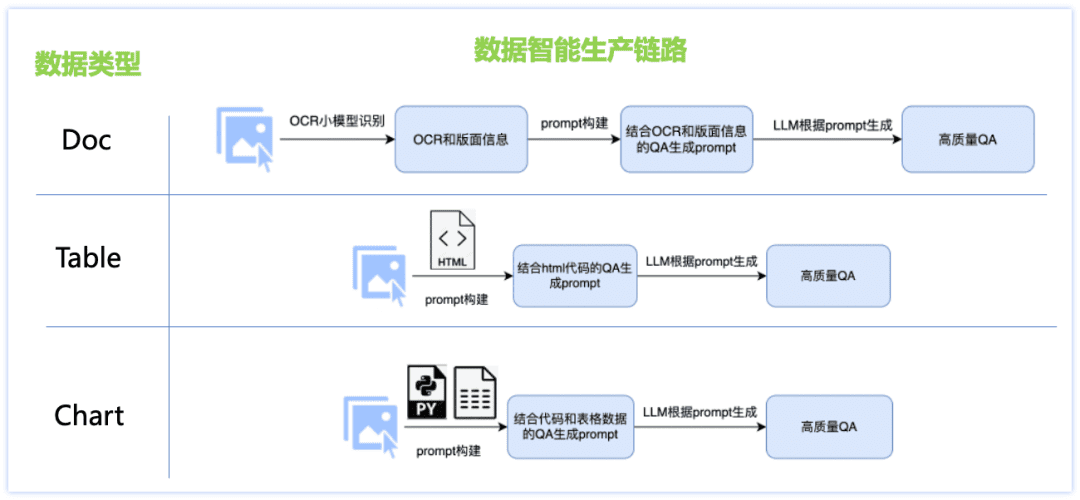
ドククラスのデータ:
Picture:論文、財務報告書、研究論文、その他のpdfファイルを収集・整理し、pdf分析ツールと組み合わせて、膨大な1ページの文書画像データを作成します;
Q&A:OCR小型モデルは、詳細な画像レイアウト情報を抽出することで、大型モデルの視覚的認識の欠点を補うと同時に、大型言語モデルの強力なテキスト理解能力を使用して、OCR小型モデルの個々の文字認識の不正確さを修正し、この2つの組み合わせにより、より高品質でタイプコントロール可能なQ&Aを作成することができます。
テーブルクラスのデータ:
画像:htmlテキスト情報を含む表画像に基づき、大きな言語モデルを通じて、テキストの値、件名などの情報を変更し、表レンダリングツールを通じて、内容の豊富な高品質の表画像を得る。
Q&A:テーブル画像に対応するhtml形式のテキストをGT補助情報として使用し、回答の正確性を確保するとともに、大規模な言語モデルを通じて高品質のQ&Aを生成するために、きめ細かく調整されたプロンプトを設計する。
チャートクラスのデータ:
イメージ:クラウドテストされた高品質のチャートソースデータ(イメージ-コード-テーブルデータ)を基に、大規模な言語モデルを通して、チャートの数値、軸、凡例、テーマ、その他の細かい情報をコード内でランダムに変更し、多様な内容のソースコードを取得し、チャートレンダリングツール(Matplotlib、Seaborn、Vega-Liteetc)を使用して、高品質のチャート画像データを得ることができる;
Q&A:図表画像と表データに対応するコードをGT補助情報として、回答の正確性を確保し、図表の種類に応じて対応する質問タイプを設計し、大規模な言語モデルを通じて高品質なQ&Aを生成するために微調整されたプロンプトを設計します。上記のような文書データのインテリジェントな生成スキームを通じて、我々は膨大な量の合成データを取得し、その一部をPP-DocBeeの学習データの1つとしてフィルタリングします(データの分布は下図)。
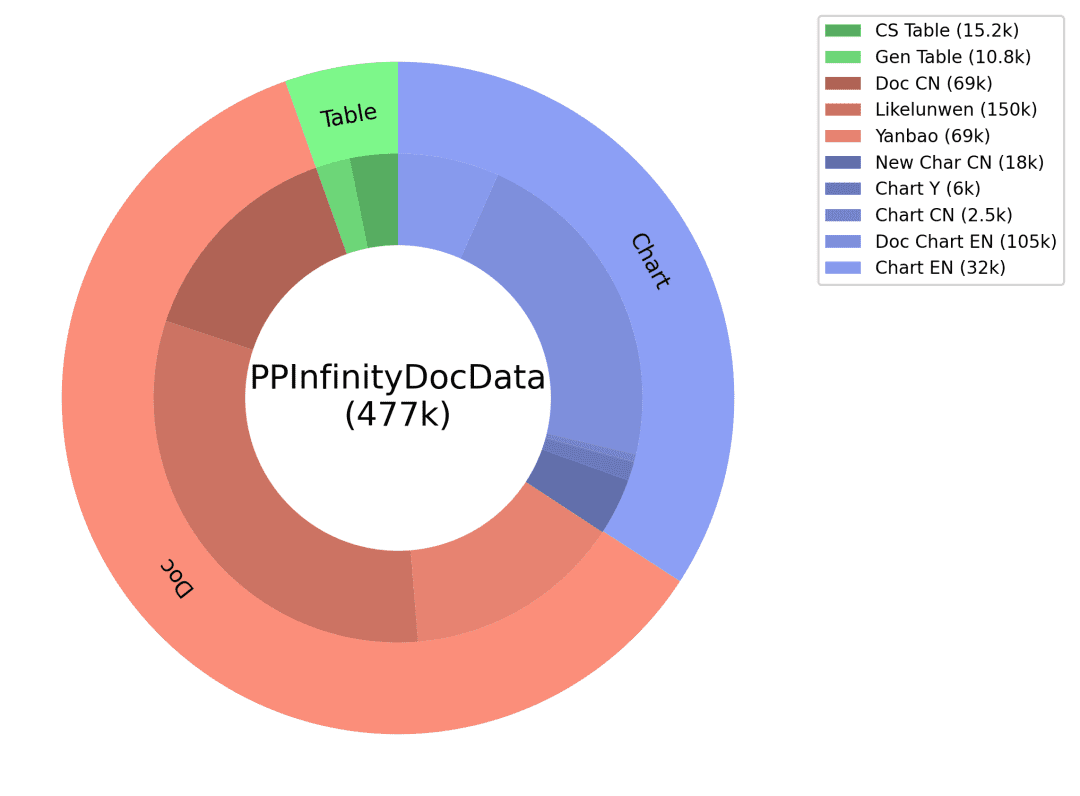
合成データ分布
2.データの前処理
1つは、データセットの全体的な解像度の分布を大きくするために、学習時にリサイズのしきい値を大きく設定することであり、もう1つは、解像度の小さい画像に対しては元のデータ前処理戦略を変更しないまま、推論時にほとんどの通常画像に対して1.1倍から1.3倍の等倍率を設定することである。これら2つの戦略により、より適切で包括的な視覚的特徴が得られ、最終的な理解度が向上した。
3.トレーニング方法
主に様々な文書理解クラスのデータが混在しており、データマッチングメカニズムも設定されている。様々なデータセットには、汎用VQAクラス、OCRクラス、ダイアグラムクラス、テキストリッチ文書クラス、数学・複雑推論クラス、合成データクラス、プレーンテキストデータなどが含まれる。データマッチングメカニズムは、異なるクラスおよびクラス間の異なるソースからのデータに対してサンプリング比率を設定することで、複数のクラスでより大きな利得を持つデータのサンプリングウェイトを増加させるとともに、様々な種類のデータセット間の量的な差異をバランスさせるものである。
4.OCR後処理支援
主に事前にOCRツールやモデルを介してテキストの結果のOCR認識を取得し、補助先験的な情報として絵のクイズの問題で提供され、その後、PP-DocBeeモデルの推論を与え、テキストにすることができますあまりないと明確な画像は、改善にいくつかの効果があります。
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事

コメントはありません