Easy Dataset: 大規模モデルの微調整データセットを作成するシンプルなツール

はじめに
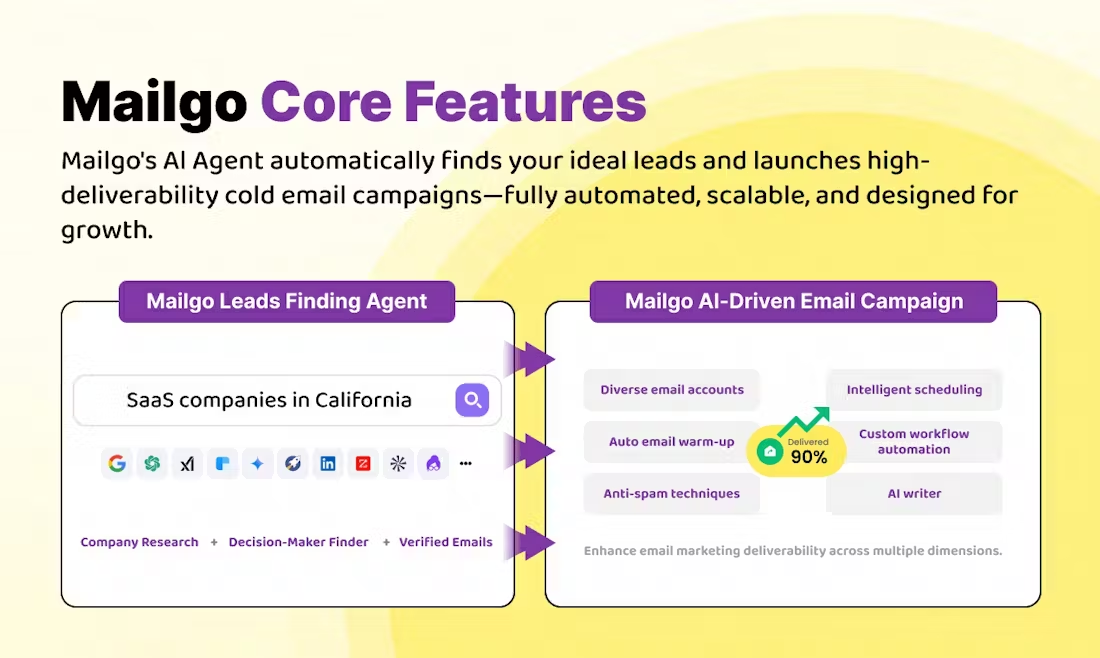
Easy Datasetは、大規模モデル(LLM)の微調整のために特別に設計されたオープンソースツールで、GitHubでホストされています。ユーザーがファイルをアップロードし、コンテンツを自動的にセグメント化し、質問と回答を生成し、最終的にファインチューニングに適した構造化データセットを出力できる、使いやすいインターフェースを提供します。開発者のConard Liは、ユーザーがドメイン知識を高品質のトレーニングデータに変換するのを助けるためにこのツールを作成した。JSONやAlpacaなど複数のエクスポートフォーマットをサポートし、OpenAIフォーマットに従ったすべてのLLM APIと互換性があります。技術的な専門家であろうと、単なるカジュアルユーザーであろうと、このツールを使えば簡単に始められ、素早くデータセットを作成できます。

機能一覧
- インテリジェント・ドキュメント・プロセッシングMarkdownファイルをアップロードすると、ツールは自動的に小さな塊に分割します。
- 質問世代セグメント化されたテキストに基づいて、関連する質問を自動的に生成します。
- 回答世代LLM APIを呼び出して、各質問に対する詳細な回答を生成します。
- 柔軟な編集質問、回答、データセットの内容をいつでも変更することができます。
- 複数のエクスポート形式データセットは、JSON、JSONL、またはAlpaca形式でエクスポートできます。
- 幅広いモデルをサポートOpenAIフォーマットに従うすべてのLLM APIと互換性があります。
- ユーザーフレンドリーなインターフェースデザインは直感的で、テクニカルなユーザーにもそうでないユーザーにも適しています。
- カスタムヒント特定のスタイルの回答を生成するようモデルに指示するシステムプロンプトを追加することができます。
ヘルプの使用
設置プロセス
Easy Datasetには、Docker経由でデプロイする方法と、ローカル・ソースから実行する方法の2つの主な使用方法がある。詳しい手順は以下の通りです:
Dockerによるインストール
- Dockerのインストール
コンピューターにDockerがまだ入っていない場合は、Docker Desktopをダウンロードしてインストールする。インストールが完了したら、ターミナルを開いて成功を確認する:
docker --version
バージョン番号が表示されていれば、インストールされていることを意味する。
- イメージを取り出して実行する
ターミナルで以下のコマンドを入力し、公式イメージを取り込み、サービスを開始する:
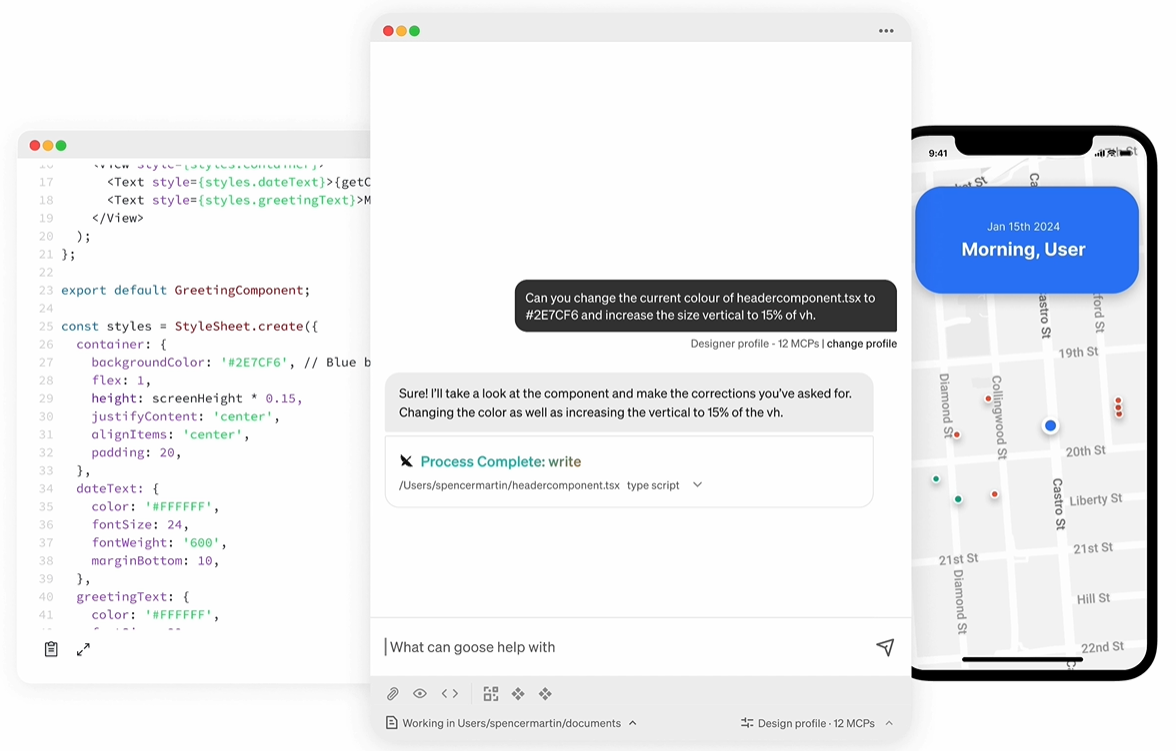
docker run -d -p 3000:3000 -v {你的本地路径}:/app/local-db --name easy-dataset conardli17/easy-dataset:latest
{你的本地路径}これを、データを保存するために使用するコンピューター上のフォルダーへのパスに置き換える必要があります。C:\data(Windows)または/home/user/data(Linux/Mac)。-p 3000:3000コンテナ内のポート3000が、ローカルでポート3000にマップされていることを示す。-vこれは、コンテナの再起動後にデータが失われるのを防ぐためである。
- アクセスインターフェイス
起動に成功したら、ブラウザを開き、次のように入力します。http://localhost:3000Easy Datasetのホームページが表示されます。Easy Datasetのホームページが表示されます。"Create Project "ボタンをクリックして、プロジェクトを開始します。
ソースコードをローカルで実行する
- 環境を整える
- お使いのコンピューターにNode.js(バージョン18.x以上)とnpmがインストールされていることを確認してください。
- チェック方法:ターミナルで入力
node -v歌で応えるnpm -vバージョン番号を見るだけだ。
- クローン倉庫
それをターミナルに入力する:
git clone https://github.com/ConardLi/easy-dataset.git
cd easy-dataset
- 依存関係のインストール
プロジェクトフォルダー内で実行される:
npm install
- サービス開始
以下のコマンドを入力してコンパイルし、実行する:
npm run build
npm run start
完了したら、ブラウザを開いて http://localhost:3000ツール・インターフェースは、"Tools "ボタンをクリックしてアクセスできる。
主な機能
プロジェクトを作成する
- ホームページで「プロジェクトを作成」ボタンをクリックします。
- プロジェクトの名前を入力します(例:"My Dataset")。
- 確認」をクリックすると、システムが新しいプロジェクト・スペースを作成します。
書類のアップロードと処理
- プロジェクトページで、「テキスト分割」または「テキスト分割」オプションを見つける。
- Upload file "をクリックし、ローカルのMarkdownファイルを選択します。
example.md). - アップロード後、ツールは自動的にファイルの内容を小さなセグメントに分割します。各セグメントはインターフェイスに表示され、手動で分割結果を調整することができます。
質問と回答の作成
- 質問」または「質問管理」画面に移動します。
- 質問を生成する」ボタンをクリックすると、ツールは各テキストに基づいて質問を生成します。
- 生成された質問をチェックし、満足できない場合は、質問の横にあるEditボタンをクリックして変更することができます。
- 回答生成」をクリックし、LLM APIを選択してください(事前にAPIキーを設定する必要があります)。
- 回答が生成されたら、その内容が要件を満たしているかどうかを確認するために、手動で編集することができます。
データセットのエクスポート
- データセットまたはデータセット管理画面に移動する。
- エクスポート」ボタンをクリックし、エクスポート形式(JSONやAlpacaなど)を選択します。
- システムがファイルを生成しますので、「ダウンロード」をクリックしてローカルに保存してください。
注目の機能操作
LLM APIの設定
- 設定ページで、モデル設定を見つける。
- LLMのAPIキー(例:OpenAIのAPIキー)を入力します。
- モデルタイプ(多くの一般的なモデルをサポート)を選択し、設定を保存します。
- 一度設定されると、このモデルは回答を生成するときに呼び出されます。
カスタマイズされたシステム・アラート
- 設定]ページで、[プロンプト]または[プロンプト・テンプレート]を見つけます。
- 簡単な言葉で答えてください」など、カスタマイズしたプロンプトを入力します。
- 保存されると、プロンプトに従ってスタイルが調整された回答が作成されます。
データセットの最適化
- Datasets 画面で、Optimise ボタンをクリックします。
- システムはデータセットを分析し、重複を削除したり、フォーマットを最適化したりする。
- 最適化されたデータセットは、モデルの微調整に直接使用するのに適している。
ほら
- Dockerでデプロイする場合は、定期的なバックアップをお忘れなく!
{你的本地路径}その中のデータ。 - ローカルで実行する場合、回答生成にはAPIを呼び出すためのインターネット接続が必要なので、ネットワークが開いていることを確認してください。
- エラーが発生した場合は、GitHubの "Releases "ページをチェックし、問題を解決するための最新バージョンをダウンロードすることができる。
アプリケーションシナリオ
- モデル開発者がLLMを微調整
開発者は、Easy Datasetを使用して、技術文書の処理、Q&Aペアの生成、トレーニングセットの迅速な作成、特定ドメインでのモデル性能の向上を行うことができます。 - 教育者による学習教材の制作
教師は、コースのプリントをアップロードし、生徒の復習やオンラインコースのコンテンツ作成のための質問と回答を作成することができます。 - 研究者はドメイン知識を照合する
研究者は論文やレポートをアップロードし、主要な質問と回答を抽出し、分析のために構造化されたデータに整理することができる。
品質保証
- Easy Datasetはどのようなファイル形式をサポートしていますか?
現在のところ、主なサポートはMarkdownファイル(.md)、将来的には他のフォーマットのサポートも追加されるかもしれない。 - LLMのAPIは自分で用意する必要がありますか?
はい、このツール自体はLLMサービスを提供しておらず、OpenAIやその他の互換性のあるモデルなど、ユーザー自身がAPIキーを設定する必要があります。 - エクスポートされたデータセットはどのようなモデルに使用できますか?
モデルがOpenAIフォーマット(LLaMA、GPTなど)をサポートしている限り、エクスポートされたデータセットを直接使用することができます。
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事


コメントはありません